




cpu到 gpu之间的通讯过程
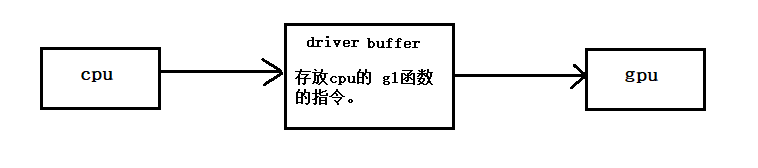
c层写入 gl的一些gpu的操作时,这些指令会在驱动层,驱动层会将系统 从 protect模式切换到unprotect模式,从而将指令传输给gpu,gpu来执行。但切换操作系统模式会很消耗性能,因此,driver层开辟一个buffer,用来存储gl的命令,等存储到一定后一起送往gpu,以来提高性能,如下图:
glflush操作
glflush操作是将 driver buffer种的gl指令集强行送入gpu,在这之前,处于堵塞状态,送入gpu后,就会返回结果值。
glfinish操作
glfinish操作是将driver buffer的数据全部送入gpu,并且gpu执行完毕所以指令后返回值,在这之前会堵塞。


















 1694
1694

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









