




 本文介绍了如何使用Dijkstra算法解决一个涉及电影院票价和道路费用的最短路径问题。通过创建虚拟节点来处理票价,并通过一次Dijkstra算法解决往返问题,从而避免时间复杂度过高。
本文介绍了如何使用Dijkstra算法解决一个涉及电影院票价和道路费用的最短路径问题。通过创建虚拟节点来处理票价,并通过一次Dijkstra算法解决往返问题,从而避免时间复杂度过高。
无聊的小Biu来到了电影之城,他发现这里有n个电影院,而且每个电影院的电影票价是不同的,有一些电影院之间有双向联通的道路,想要通过某条道路也有不同的花费,小Biu想知道,他以每一个电影院为起点(当然也可以原地不动),最少需要多少花费可以看到电影并返回到起点。
Input
第1行:两个整数n,m,n表示城市中电影院的个数,m表示电影院之间的道路总数。(1<=n<=100000,1<=m<=300000) 第2行:n个正整数,第i个正整数表示在第i个电影院看电影的票价vali。(1<=vali<=1000) 第3~m+2行:每行三个正整数,u,v,w,表示电影院u与电影院v之间有一条花费为w的道路。(1<=u,v<=n,1<=w<=1000)
Output
输出n行每行一个正整数。 第i行输出的正整数表示从第i个电影院出发,最少需要多少花费可以看到电影。
Sample Input
4 4
1 2 3 4
1 2 3
2 3 4
1 3 1
1 4 1
Sample Output
1
2
3
3
分析
先看题目要我们求多源的最短路,一看数据范围就懵了,果断用Dij。但是跑n次的Dij的话有会爆时间。
于是我突然想到了这道题,有感而发,建了一个虚拟的节点,把所有点都与这个点建一条边,编号为0,代价为每个电影院的票价,这样很好的解决了票价的问题。(原因后面再讲)
但是
爆时间的问题还是没有解决。还有往返的问题,都比较棘手。
爆时间?
从每个点跑一次Dij肯定是不行的,首先我可以理解为,我建的这个虚拟的节点是所有起点的共同终点。
这样改之后,就相当于我从每个电影院出发看电影的最小代价即为从这个电影院到虚拟节点的最小代价。如图(数据是样例)
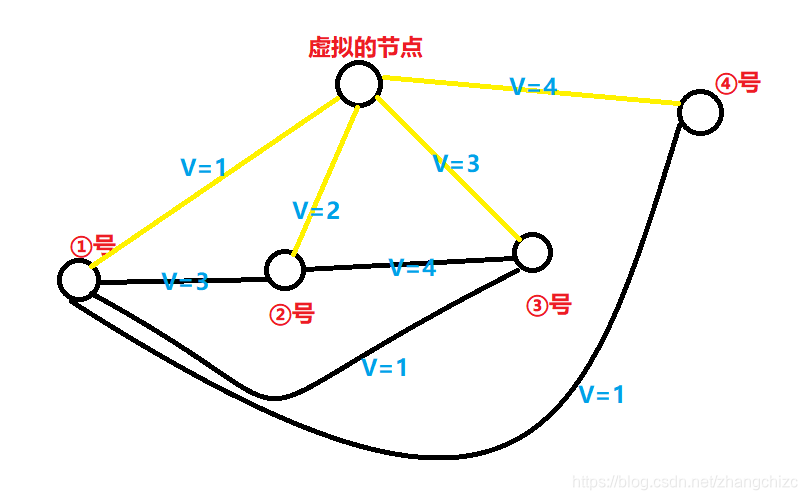
如上图,从①号出发,到终点最短就是直接过去,在原题中就相当于不动在原地买票,其他的以此类推。
但是貌似还是不行啊
于是想到:从A到B和从B到A是一样的,于是反正终点是一样的,不如把终点当做起点,跑一次Dij就可以了啊我好机智
往返?
这个其实很好解决,除了电影院的票价不要往返以外,别的都把权值*2不就解决了吗我好弱,想了好久
上DM!
#include<algorithm>
#include<iostream>
#include<cstring>
#include<iomanip>
#include<cstdio>
#include<string>
#include<vector>
#include<cmath>
#include<queue>
#define ll long long
#define inf 1<<30
using namespace std;
struct node{
int x,dis 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 315
315

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









