



本文基于langgraph的预制件 Agent Chat UI和《搭建一个本地langgraph服务》中的本地服务构建一个简单的agent系统。
说明:Agent Chat UI需要nodejs版本18及以上,而nodejs18需要的glibc版本为2.28,本人使用操作系统为ubuntu18.04,glibc版本最高支持2.27,所以对glibc作了升级。最好使用ubuntu20.04。因为期间运行环境花了很多时间,在此一并把环境搭建内容写出来。
一、安装node
虽然安装方法很多,为避免版本问题,直接手动安装。
1)从官网下载安装18.20.8版本安装包
地址:https://nodejs.org/download/release/latest-hydrogen/node-v18.20.8-linux-x64.tar.gz
2)解压到指定目录
#sudo tar cxf node-v18.20.8-linux-x64.tar.gz -C /usr/local/node
3)设置node和npm软链
#sudo ln -s /usr/local/node/bin/node /usr/local/bin/node
#sudo ln -s /usr/local/node/bin/npm /usr/local/bin/npm
二、安装pnpm
因github访问问题,需要手动下载安装文件,并修改安装包地址。
1)下载install.sh文件
#curl
https://get.pnpm.io/install.sh -o install.sh
2)修改install.sh中的archive_url
#vi install.sh archive_url="https://hub.gitmirror.com/https://github.com/pnpm/pnpm/releases/download/v${version}/pnpm-${platform}-${arch}"
3)执行安装
#chmod u+x install.sh
#./install.sh
三、安装前端
1)下载Agent Chat UI代码
#git clone https://github.com/langchain-ai/agent-chat-ui.git
2)修改配置文件
进入应用主目录,并执行如下操作:
#cp .env.example .env
#vi .env
#修改如下环境变量的值
NEXT_PUBLIC_API_URL=http://{langgraph服务所在主机地址}:2024
NEXT_PUBLIC_ASSISTANT_ID=agent #本地服务agent名(见本地服务config.json)
3)启动前端服务
#pnpm dev
输出如下图所示:
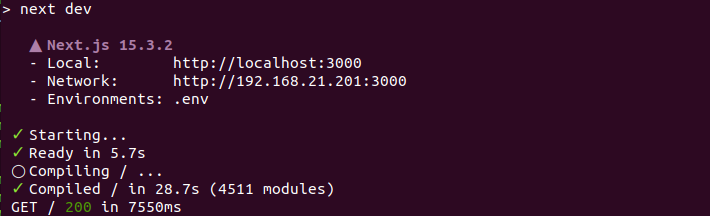
四、重启langgraph服务
使用langgraph dev启动后端服务时,缺省使用地址为127.0.0.1,此时从浏览器访问不到,所以重启langgraph服务,并使用0.0.0.0地址。
#langgraph dev --host 0.0.0.0
五、使用Agent Chat UI聊天
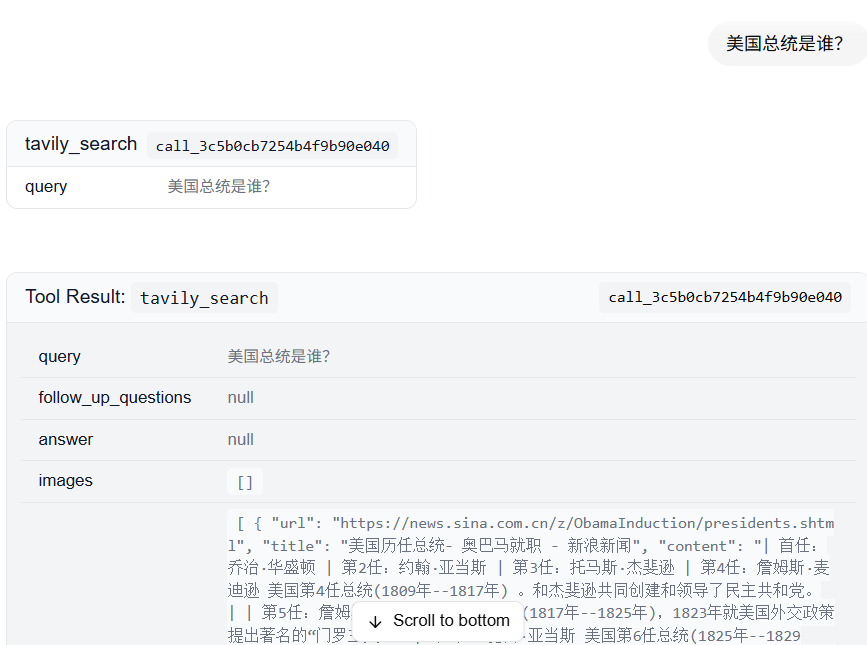
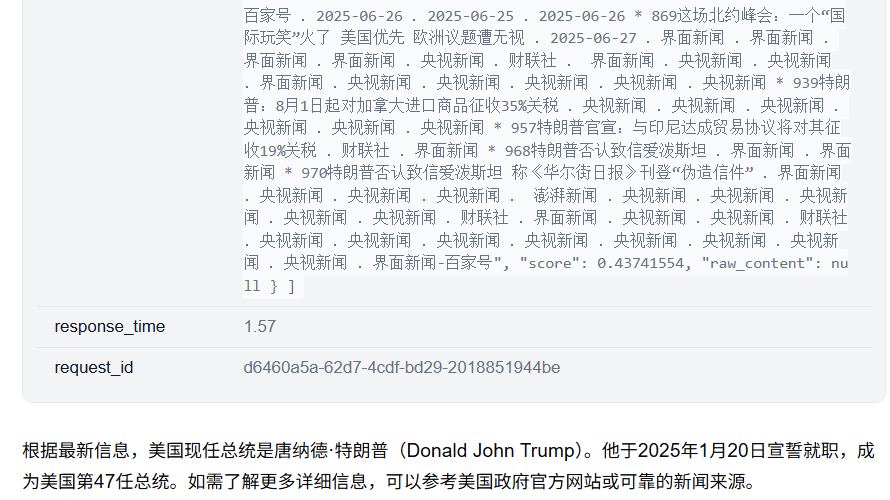

















 448
448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









