







任务链接:https://wx.zsxq.com/dweb/#/index/222248424811
1.TF-IDF
TF-IDF参考链接:https://www.cnblogs.com/pinard/p/6693230.html
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = ["I come to China to travel",
"This is a car polupar in China",
"I love tea and Apple ",
"The work is to write some papers in science"]
# max_features是最大特征数
# min_df是词频低于此值则忽略,数据类型为int或float
# max_df是词频高于此值则忽略,数据类型为Int或float
tfidf_model = TfidfVectorizer(max_features=5, min_df=2, max_df=5).fit_transform(corpus)
print(tfidf_model.todense())
2.互信息
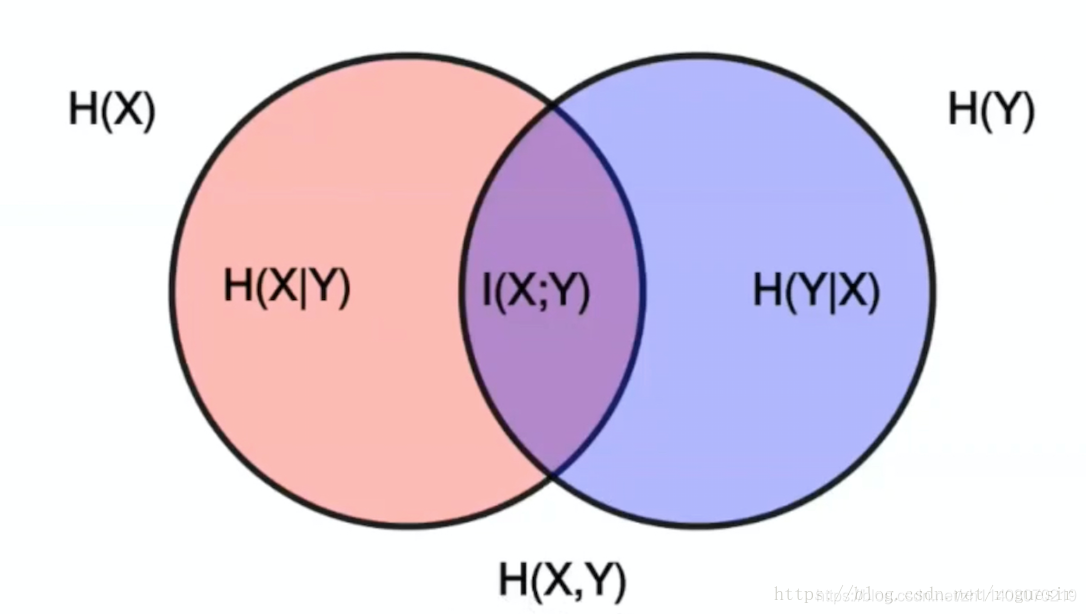
参考链接:https://blog.youkuaiyun.com/roguesir/article/details/80947490
特征选择参考链接1:https://www.jianshu.com/p/b3056d10a20f
特征选择参考链接2:https://baijiahao.baidu.com/s?id=1604074325918456186&wfr=spider&for=pc
信息量:事件发生概率越高,含有的信息量就越低。
熵:事件发生的不确定性越大,熵越大。
联合熵:联合熵可以表示为两个事件的熵的并集。
条件熵:条件熵实际上是联合熵与熵的差集,也可表示为熵与互信息的差集。
互信息:互信息是用来表示变量间相互以来的程度,常用在特征选择和特征关联性等方面。
相对熵:相对熵用来描述两个分布之间的差异。
交叉熵:交叉熵常用在深度学习中目标函数优化。
import pandas as pd
from sklearn import datasets
from sklearn import metrics as mr
iris = datasets.load_iris()
x = iris.data
y = iris.target
x0 = x[:, 0]
x1 = x[:, 1]
x2 = x[:, 2]
x3 = x[:, 3]
# 计算x和y的互信息
print(mr.mutual_info_score(x0, y))
print(mr.mutual_info_score(x1, y))
print(mr.mutual_info_score(x2, y))
print(mr.mutual_info_score(x3, y))

















 213
213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









