







目录
摘要
多任务学习已经在机器学习的很多领域取得成功,包括自然语言处理、语音识别、计算机视觉和药物发现。本文旨在给出多任务学习的概述,尤其是在深度神经网络方面的多任务学习。本文介绍了深度学习中两种最常用的多任务学习方法,给出了这方面的概述,并讨论了最新进展。特别是,它通过阐明多任务学习的工作原理并提供选择适当辅助任务的指南来帮助机器学习从业者应用多任务学习。
1. 引言
在机器学习(ML)中,我们通常关心针对特定指标进行优化,无论这是某个基准的分数还是业务KPI。为了做到这一点,我们通常训练单个模型或模型集合来执行我们想要的任务。然后我们对这些模型进行微调和调整,直到它们的性能不再提高。虽然我们通常可以通过这种方式获得可接受的性能,但由于过于专注于我们的单一任务,我们忽略了可能帮助我们在我们关心的指标上做得更好的信息。具体来说,这些信息来自于相关任务的训练信号。通过在相关任务之间共享表示,我们可以使我们的模型更好地泛化我们的原始任务。这种方法被称为多任务学习(MTL)。
多任务学习已经在机器学习的很多领域取得成功,包括自然语言处理、语音识别、计算机视觉和药物发现。多任务学习有很多形式:联合学习、学会学习、利用辅助任务学习这些名字已经被用来指代多任务学习。通常,只要发现优化的损失函数超过一个,就是在做多任务学习。在这些情况下,这有助于明确地思考正在根据多任务学习做什么,并更好地理解它。
即使在某些典型场合只需要优化一个损失,一个辅助任务也有机会能提高主任务的性能。Caruana在1998年简洁地总结了多任务学习的目的:多任务学习通过利用相关任务的训练信号中包含的特定领域信息来提高泛化能力。
在本文中,我们将给出现阶段多任务学习的概述,尤其是利用深度神经网络的多任务学习。第二节从不同角度给出多任务学习的动机。第三节介绍两种深度学习中最常用的多任务学习方法。第四节描述了一些机理,这些机理共同解释了为什么多任务学习在实践中有效。在关注先进的基于神经网络的多任务学习方法之前,在第五节给出了一些多任务学习相关的内容。第六节介绍了深度神经网络中最近提出的多任务学习方法。最后,在第七节讨论了一些广泛使用的辅助任务,并讨论了什么是多任务学习中好的辅助任务。
2. 动机
可以从不同的角度看多任务学习的动机:
- 从生物角度看,多任务学习可以看作是受人类学习的启发。在学习新的任务时,我们经常利用从相关任务中已经学习到的知识。
- 从教学角度看,我们经常首先学习一些提供必要技能的任务,这些技能可以被用于掌握更复杂的技术。举个例子,空手道老师先教小孩一些看上去无关的任务,比如打磨地板和给车上蜡。但后来,这些被证明是和学习空手道相关的无价技能。
- 从机器学习的角度看,多任务学习可以看成是一种归纳迁移。归纳迁移通过引进一个归纳偏差提升模型能力,而归纳偏差使得模型更偏爱一些假设。例如,一种归纳偏差的常见形式是L1正则化,这使得模型更偏爱稀疏解。在多任务学习中,归纳偏差通过辅助任务提供,而辅助任务使得模型更偏爱那些能解释多个任务的假设。我们很快就能看到,这通常导致更好的泛化性能。
3. 两种深度学习多任务学习方法
到目前为止,我们已经聚焦了多任务学习的理论动机。为了使多任务学习的观点更具体,我们现在将看到在深度神经网络中实现多任务学习的两种最常用的方法。在深度学习背景下,多任务学习通常通过隐藏层的硬参数共享或软参数共享实现。
3.1. 硬参数共享
硬参数共享是神经网络中实现多任务学习最常用的方法,最早可以追溯到1993年。如图1所示,硬参数共享通常通过共享所有任务的隐藏层实现,但会保持一些针对具体任务的输出层。
硬参数共享极大地缓解了过拟合的风险。事实上,在1997年就有研究表明过拟合共享参数的风险要比过拟合特定于任务的参数(即输出层)的数量级小N。直观地看这很有意义:同时学习的任务越多,模型越不得不发现一种能涵盖所有任务的表达,并且在原始任务上越不容易过拟合。

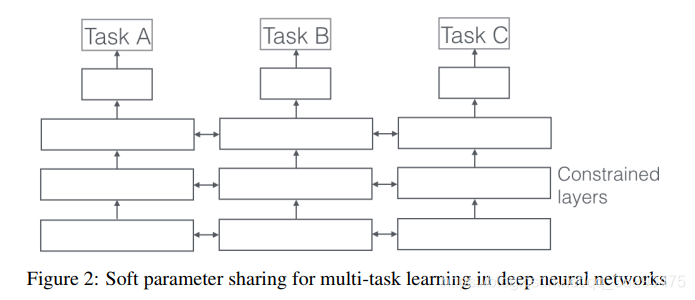
3.2. 软参数共享
在软参数共享中,每个任务有自己的模型和参数。然后通过正则化模型参数的距离来鼓励参数变得相似,如图2所示。Duong在2015年使用L2范数进行正则化,而Yang和Hospedales在2017年使用的是trace norm。
深层神经网络中用于软参数共享的约束受到了多任务学习的正则化技术的极大启发,该技术已应用在其他的模型中。
4. 为什么多任务学习有效?
尽管从多任务学习中获得的归纳偏见看上去是合理的,为了更好地理解多任务学习,我们需要看一下它背后的机理。下面这些的大多数最早由Caruana在1998年提出。在所有例子中,我们假设两个相关的任务A和B,它们依赖于一个公共的隐藏层表示F。
4.1. 隐含的数据增强
多任务学习有效地提升了训练数据的样本数量。由于所有任务至少有一定程度的噪声,当对某个任务A进行训练时,我们的目的是学习一个对A来说优秀的表示,该表示能无视数据依赖的噪声且有较好的泛化能力**。不同的任务有不同的噪声模式,一个同时学习两个任务的模型能学到更通用的表示**。只学习任务A会有对A过拟合的风险,但联合学习A和B使得模型能够通过不同噪声模式的平均获得一个更好的表示F。
4.2. 注意力聚焦
如果一个任务十分嘈杂或者数据是有限且高维的,模型很难区分出相关和无关的特征。多任务学习能帮助模型把注意力聚焦在真正重要的特征上,因为另外的任务提供了特征相关性和无关性的额外
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4089
4089

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









