






一、校级赛
1、书法大师
解压缩得到图片,尾部有zip文件,爆破解压缩密码
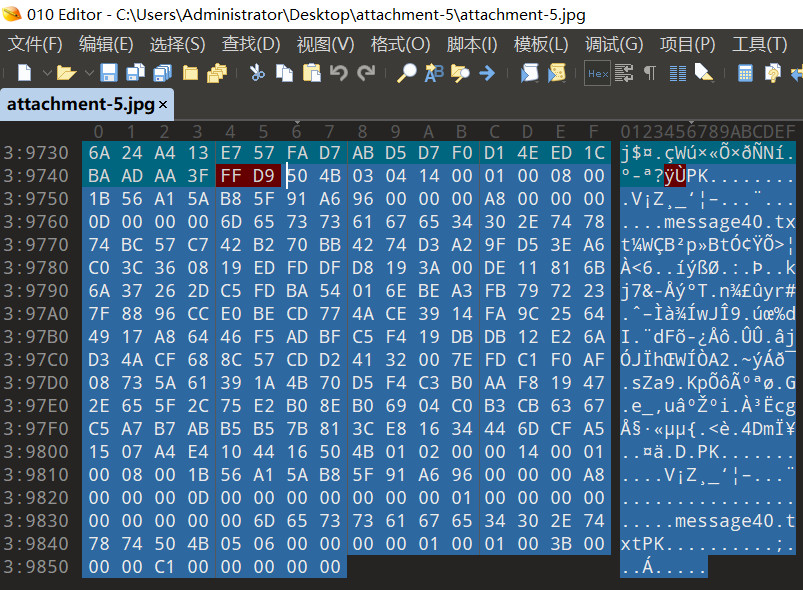
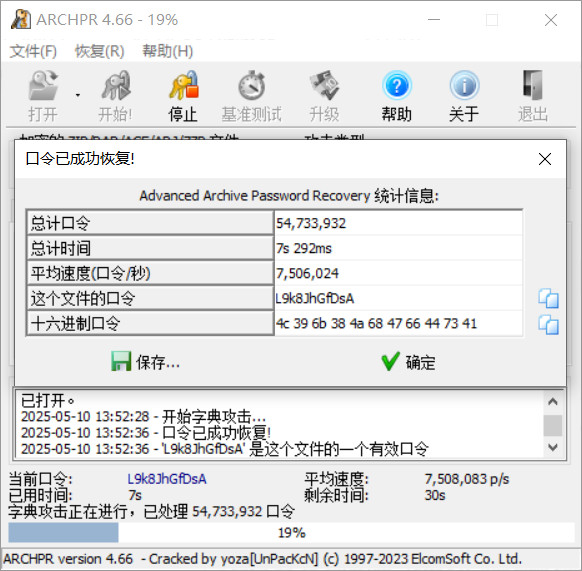
得到解压缩密码:L9k8JhGfDsA,解压缩后得到TXT
石上 巧圾 少慢 为中 石乙 巾卫 找片 找〇 尖右 年海 生圾 作一 生市 少国 时〇 女尖 丙一 众普 丙刀 工那 虫虫 石一 个蓝 马睡
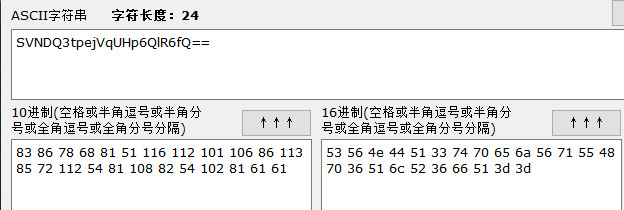
ISCC{iz5jPzzBTz}
2、反方向的钟
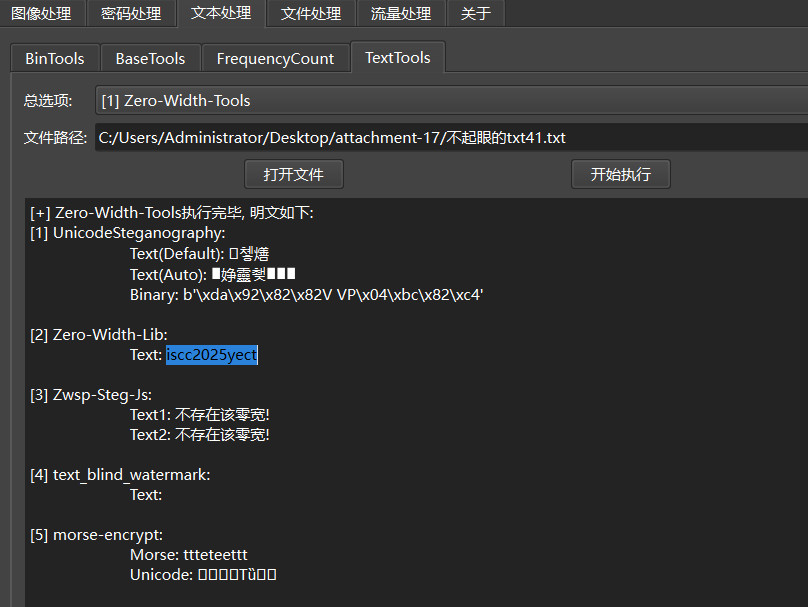
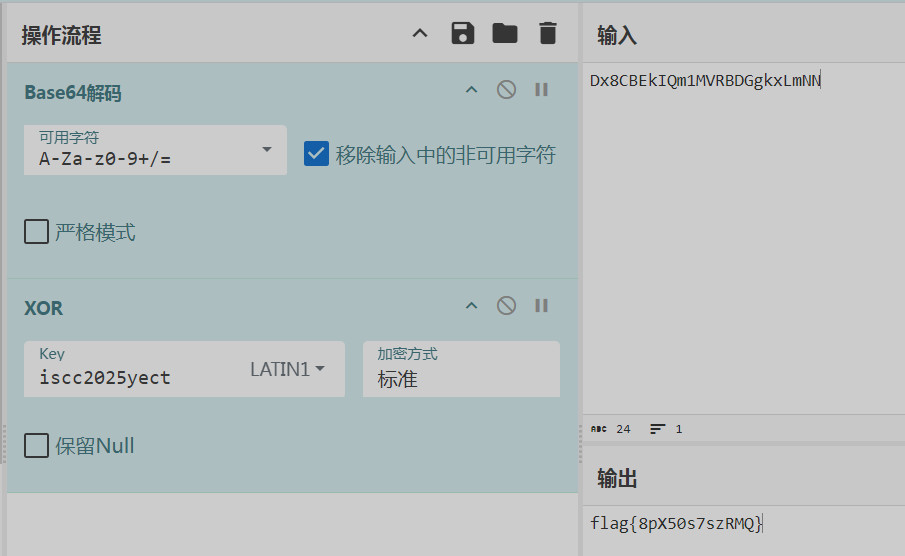
题目附件给了3个文件,只有TXT文件有用,0宽隐写得到XOR密钥,TXT文本Base64解码后异或得到flag
3、碎片真相
不会,有哪位佬做出来,望赐教
二、区域赛
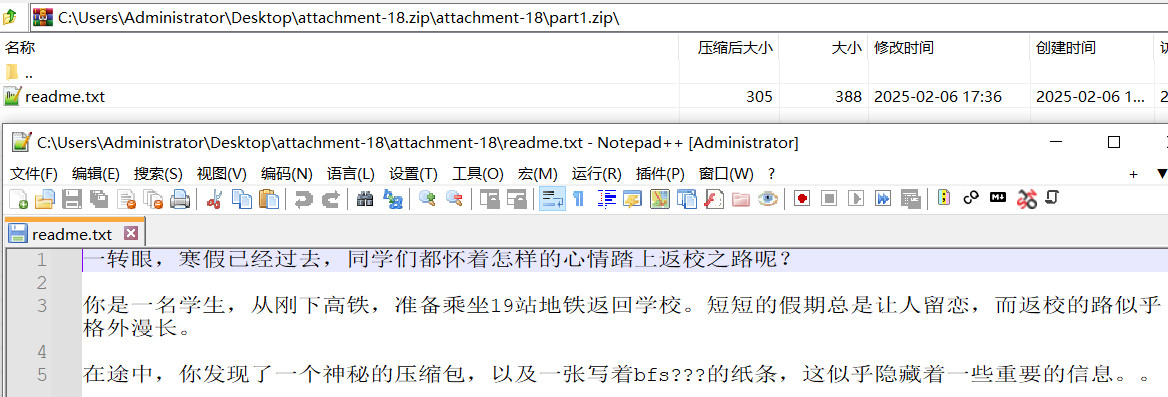
1、返校之路

压缩包里套着2个zip文件,part1.zip伪加密,7z直接查看
掩码爆破part2_3.zip
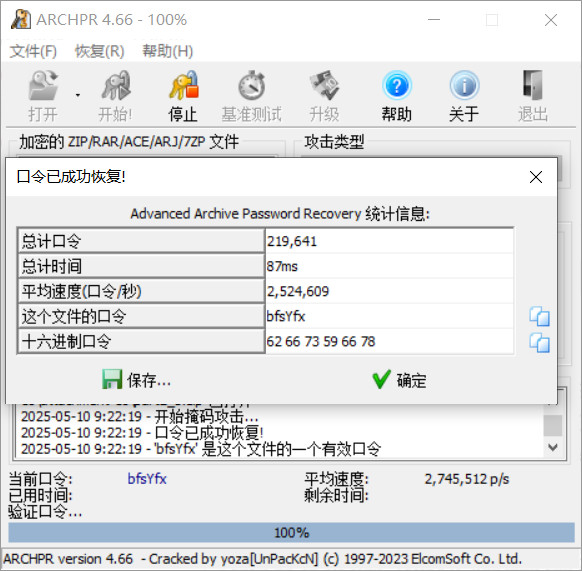
解压缩密码:bfsYfx,解压缩后得到3张图片
1.JPG尾部有PNG,导出是PNG的二维码图片
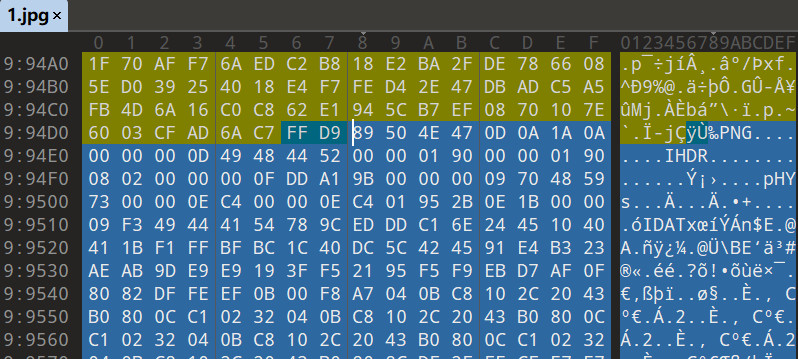
扫码得到提示

picture2.png是LSB隐写

MNVUM2KXIRUFQU2VN46Q====
Base32,Base64
rAbX8WIJ
3.JPG右键可以看到提示
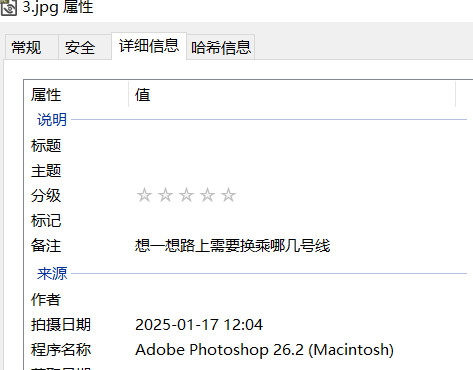
朝阳站到魏公村站,就是3号线-10号线-4号线
ISCC{rAbX8WIJ3104}
2、取证分析

题目给了hint.vmem和attachment-19.docx,R-STUDIO加载恢复桌面的hahaha.zip文件
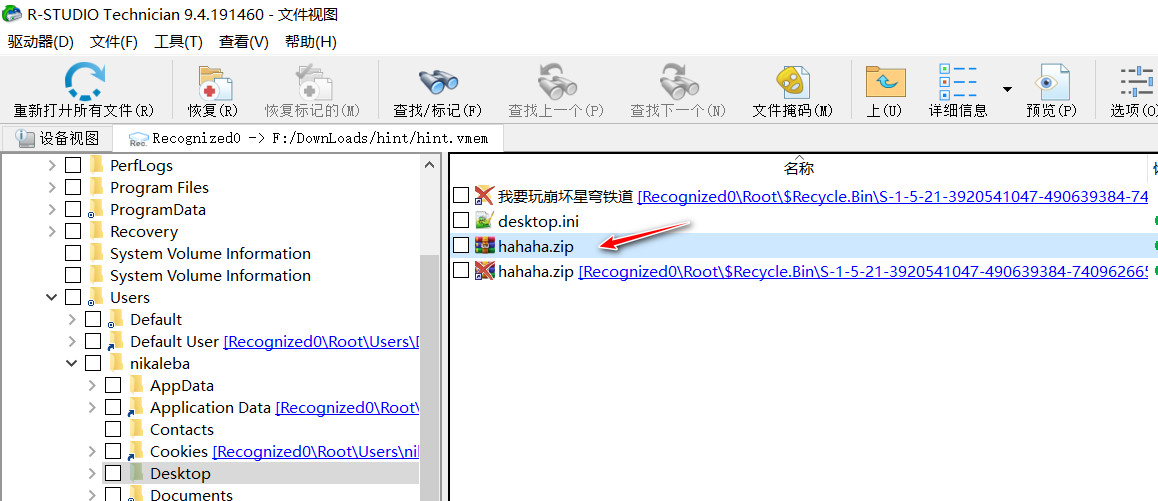
发现需要解压缩密码,寻找镜像里没找到解压缩密码,尝试字典爆破失败。联想到上一道题目btf???的密码格式,继续掩码爆破
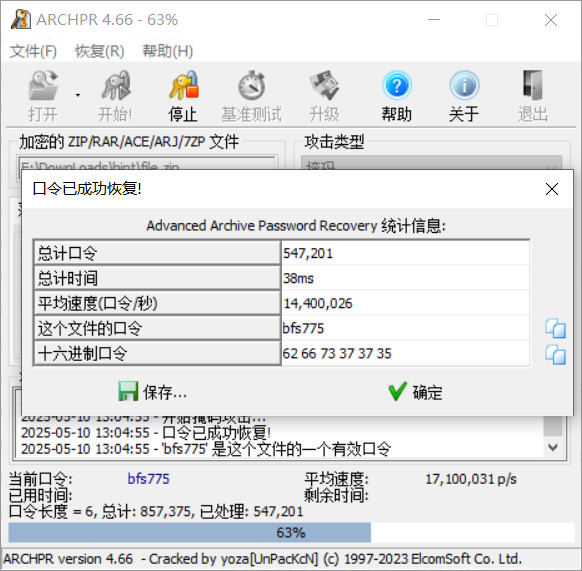
得到解压缩密码bfs775,解压缩后得到3个TXT文件,从hint.txt里rxms{ husqzqdq oubtqd }
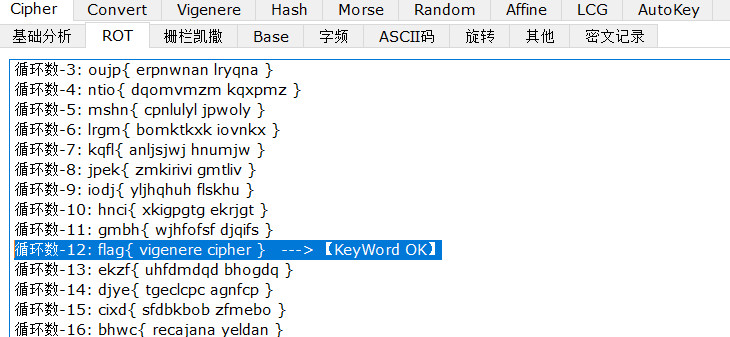
得到提示是维吉亚尼解密,从Alphabet.txt里
(2,10) (4,8) (2,4) (3,4) (11,13) (2,11) (1,1) (10,26) (5,6) (5,9)
杨辉三角是一种经典的数学数表,以中国古代数学家杨辉的名字命名。它是一个三角形数组,其中每个数字都是其上方两个数字的和。杨辉三角在组合数学、概率论和二项式定理等领域有广泛应用
盲猜括号里代表杨辉三角的列和行,(2,10)即第10行的第2个数字,脚本
from math import comb
def number_to_letter(num):
"""将数字转换为字母,1->A, 2->B, ..., 26->Z,超过26的取模"""
mod = (num - 1) % 26 + 1 # 确保结果在1-26之间
return chr(ord('A') + mod - 1)
# 原始坐标数据 (列, 行)
coordinates = [
(2, 10), (4, 8), (2, 4), (3, 4), (11, 13),
(2, 11), (1, 1), (10, 26), (5, 6), (5, 9)
]
# 计算字母序列
letters = []
for coord in coordinates:
col = coord[0]
row = coord[1]
# 检查列是否超过行
if col > row:
calc = "无效(列>行)"
value = "N/A"
letter = "?"
else:
calc = f"C({row-1}, {col-1})"
value = comb(row - 1, col - 1)
letter = number_to_letter(value)
letters.append(letter) # 添加到字母序列
print(f"行:{row:2},列:{col:2},组合数:{calc:10},最终值:{str(value):<7},字母:{letter}")
# 输出最终字母序列
print("\n最终字母序列:", end=" ")
for letter in letters:
print(letter, end="")
运行结果
行:10,列: 2,组合数:C(9, 1) ,最终值:9 ,字母:I
行: 8,列: 4,组合数:C(7, 3) ,最终值:35 ,字母:I
行: 4,列: 2,组合数:C(3, 1) ,最终值:3 ,字母:C
行: 4,列: 3,组合数:C(3, 2) ,最终值:3 ,字母:C
行:13,列:11,组合数:C(12, 10) ,最终值:66 ,字母:N
行:11,列: 2,组合数:C(10, 1) ,最终值:10 ,字母:J
行: 1,列: 1,组合数:C(0, 0) ,最终值:1 ,字母:A
行:26,列:10,组合数:C(25, 9) ,最终值:2042975,字母:Y
行: 6,列: 5,组合数:C(5, 4) ,最终值:5 ,字母:E
行: 9,列: 5,组合数:C(8, 4) ,最终值:70 ,字母:R
最终字母序列: IICCNJAYER
根据提示这应该是维吉尼亚的密钥,密文应该在DOCX中,docx修改后缀为zip,找了半天在[Content_Types].xml中找到一段类似密文的注释:luaauosenfts
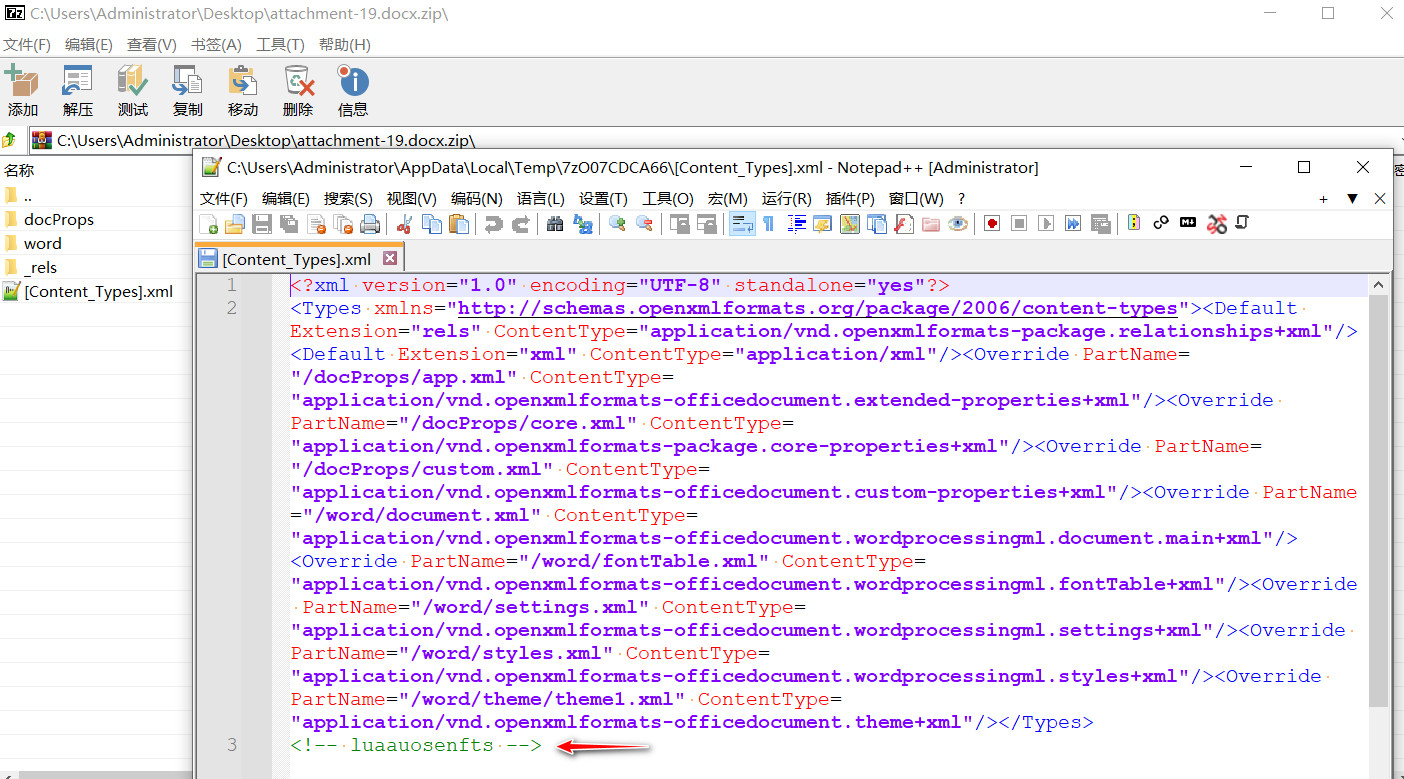
维吉尼亚解密
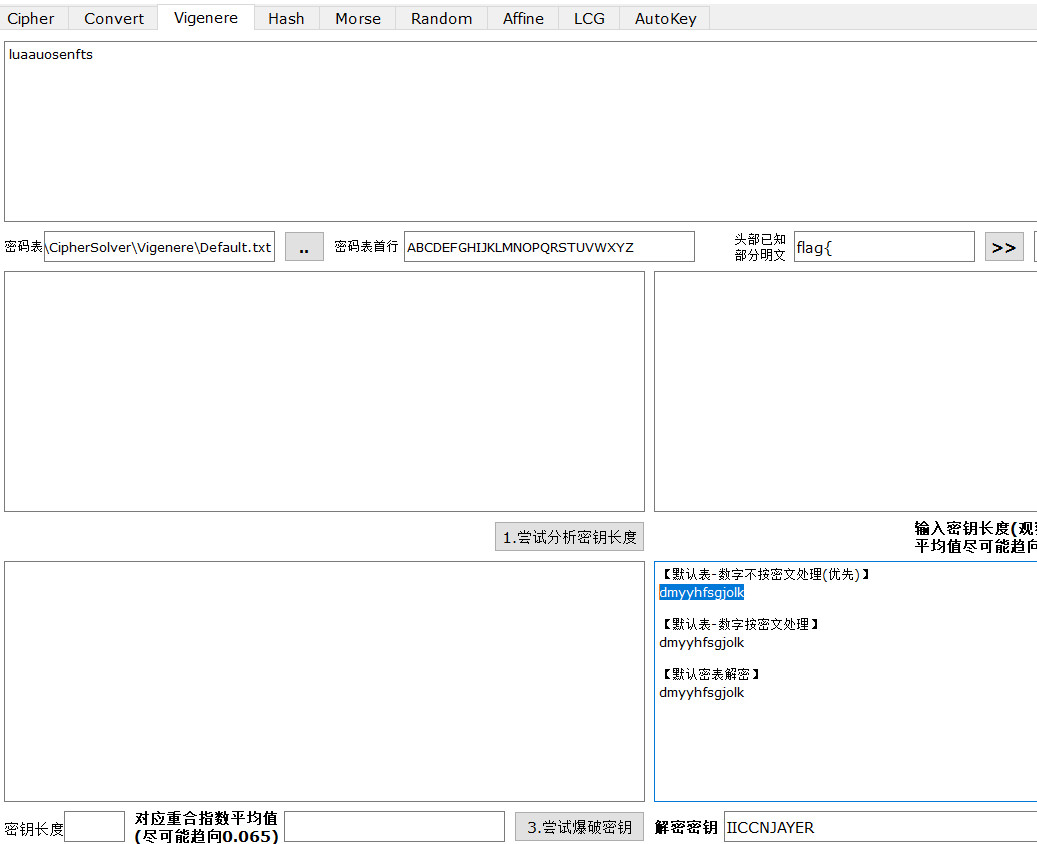
ISCC{dmyyhfsgjolk}
3、签个到吧
题目附加解压缩得到1个二维码flag_is_not_here.jpg,扫码提示:都说了这里没有flag,另一个ZIP文件修复头部
解压缩后得到PNG,打开一眼Arnold变换,变换参数未知

LSB隐写:ArnoldEncryption1112

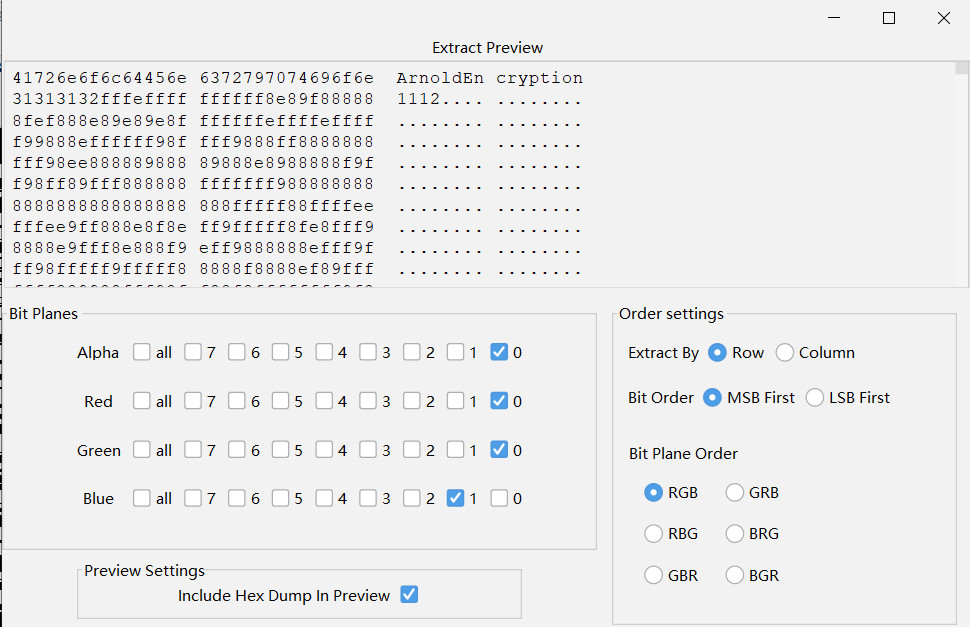
1112一开始以为参数是1、1、12或1、11、2或11、1、2,但都不对,脑洞是1、1、-2


观察还原出来的二维码,发现定位块位置有问题,需要向左旋转90度

颜色反相
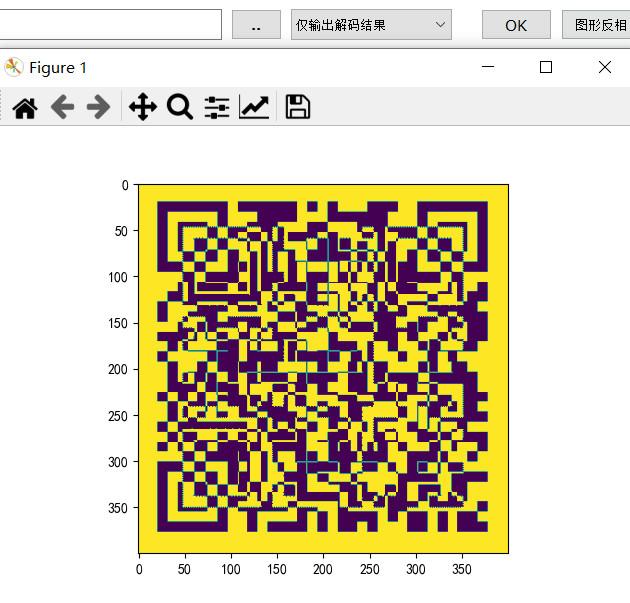
反相后的图片与flag_is_not_here.jpg异或,可以得到完整的二维码图片

异或后的图片无法扫码识别,反相后可以正常扫码识别

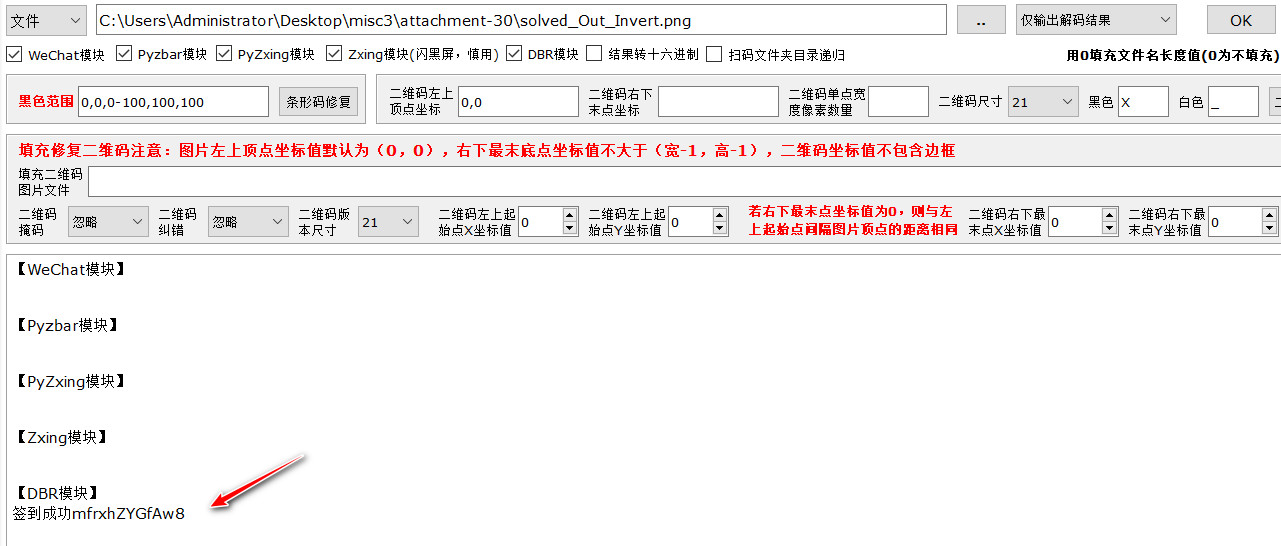
ISCC{mfrxhZYGfAw8}
4、睡美人
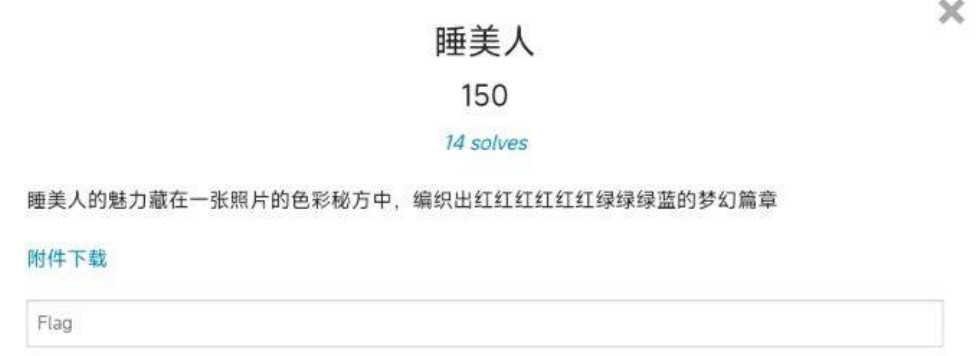

开局一张图,图片尾部有zip文件,分离出来,解压缩需要密码,盲猜密码要从PNG图片中获取
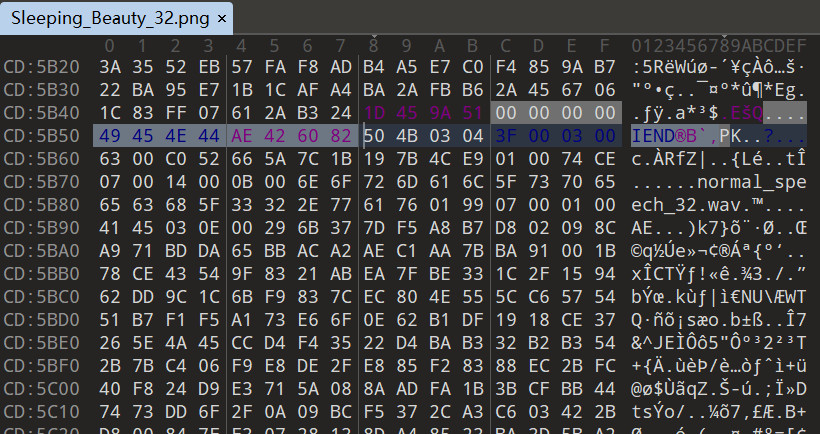
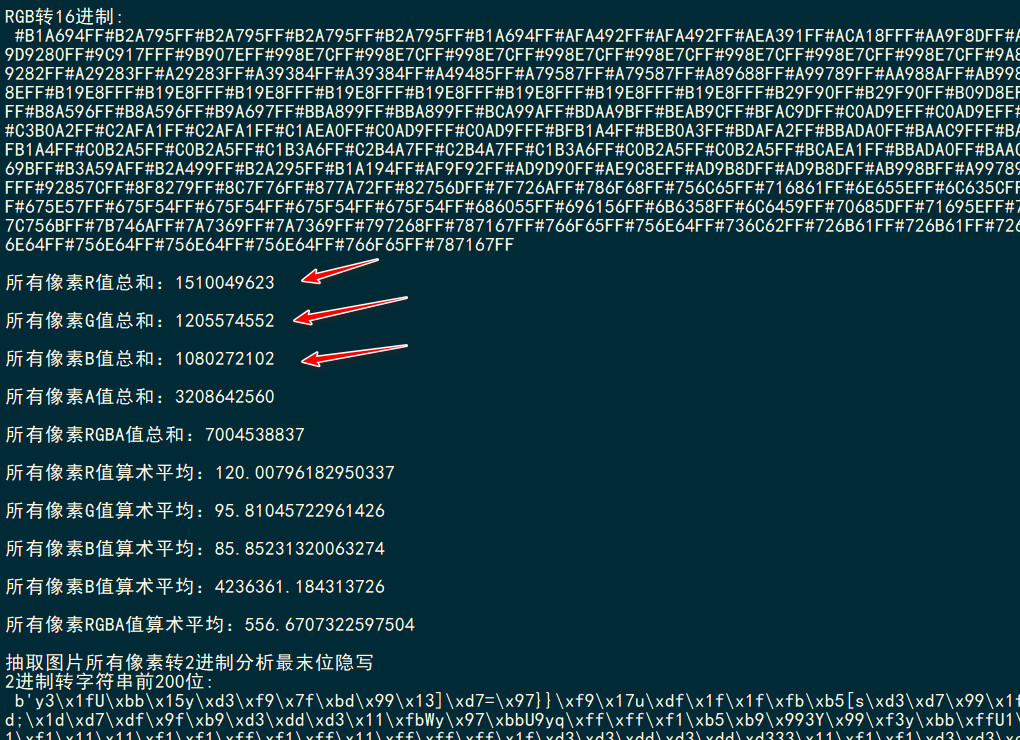
分析图片未发现隐写,此处脑洞,题目提示:红红红红红红绿绿绿蓝,一共10个字,红是60%,绿30%,红10%,计算出所有像素的R、B、A值,然后乘百分值,最后相加,脚本分析

解压缩密码:1375729349.6,解压缩后,得到normal_speech_32.wav文件
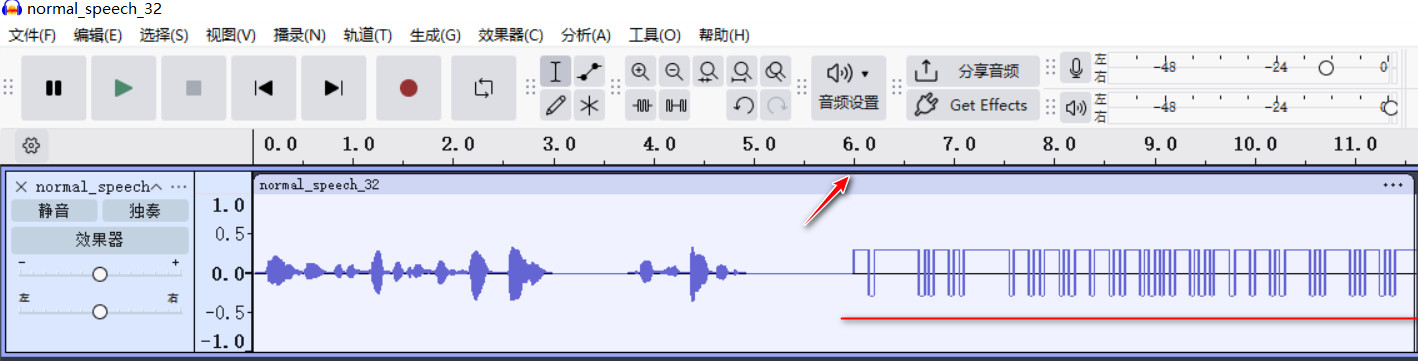
发现WAV分成两部分,第一部分是很正常的语音,提示有隐藏信息,能否找出来,第二部分从第6秒开始,类似于脉冲声音,工具分析
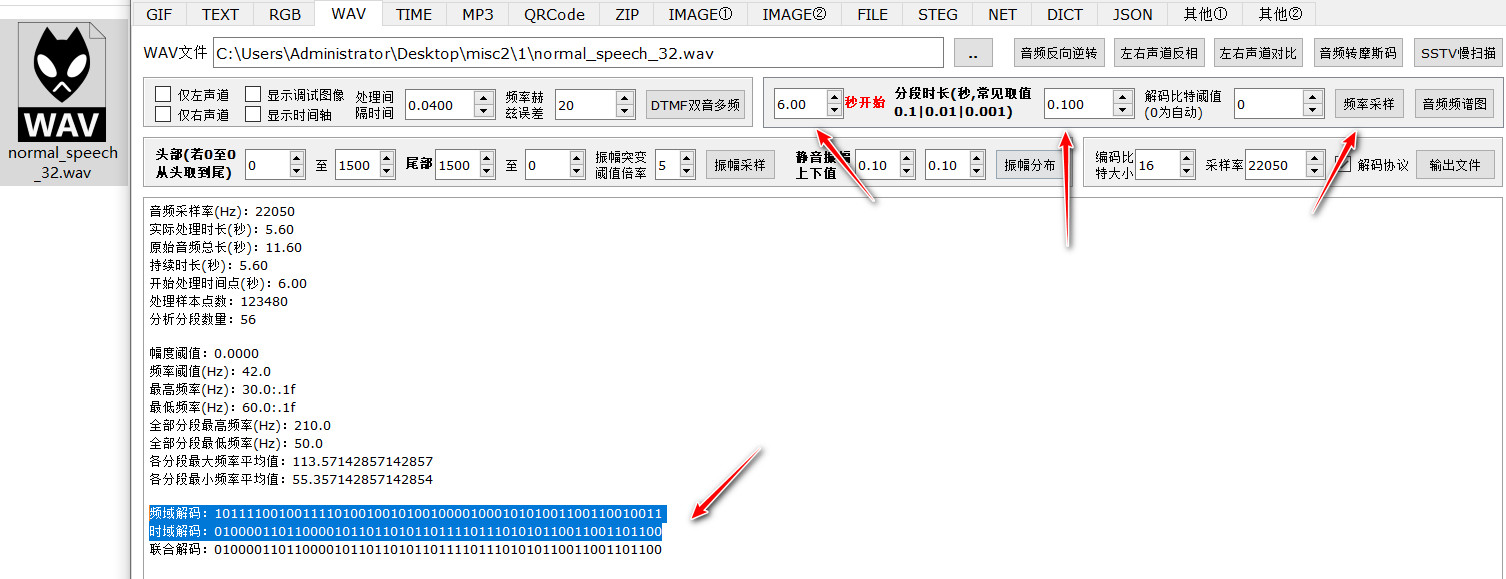
频域解码:10111100100111101001001010010000100010101001100110010011
时域解码:01000011011000010110110101101111011101010110011001101100
联合解码:01000011011000010110110101101111011101010110011001101100
时域解码的比特值可以二进制转可见字符
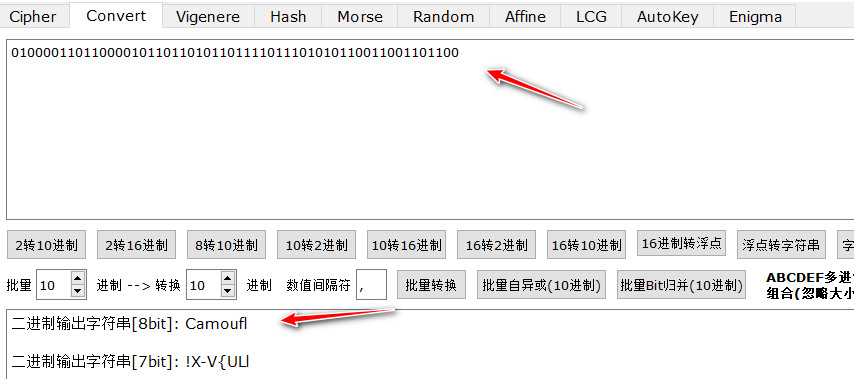
ISCC{Camoufl}
5、神经网络迷踪
import torch
import sys
import re
from libnum import n2s
def analyze_pth_file(pth_file):
# 加载模型文件
try:
state = torch.load(pth_file, map_location="cpu", weights_only=True)
except Exception as e:
print(f"加载文件失败: {e}")
return None
return state
def display_tensor_info(state):
# 显示基本信息
print("\n=== 模型张量概览 ===")
for name in state:
tensor = state[name]
print(f"{name:20} | shape={str(tuple(tensor.shape)):15} | dtype={str(tensor.dtype):10}")
# 显示每个张量的详细数据
print("\n=== 张量详细数据 ===")
for name in state:
tensor = state[name]
print(f"\n【张量名称】:{name}")
# 处理张量数据
t_flat = tensor.flatten()
if t_flat.is_floating_point():
t_flat = t_flat.round()
# 转换为整数列表
ints = []
tensor_ints = t_flat.to(torch.int64)
for i in range(len(tensor_ints)):
ints.append(tensor_ints[i].item())
print(f"整数值:{ints}")
# 转换为字节表示
byte_data = b""
for i in ints:
tmp = n2s(i)
if len(tmp) == 0:
byte_data = byte_data + b"\x00"
else:
byte_data = byte_data + tmp
print(f"Bytes (hex):{byte_data.hex()}")
print(f"Bytes (repr):{repr(byte_data)}")
# 尝试UTF-8解码
try:
decoded = byte_data.decode('utf-8', errors='strict')
print(f"UTF-8解码:{decoded}")
except UnicodeDecodeError:
print("UTF-8解码失败")
except:
print("解码时发生错误")
def extract_potential_flags(state):
print("\n=== 尝试从所有张量中提取数据 ===")
def tensor_to_text(tensor, scale):
"""将张量转换为文本,尝试不同的缩放方法"""
nums = [int(torch.round(v*scale)) & 0xFF for v in tensor.flatten()]
try:
return bytes(nums).decode('utf-8')
except UnicodeDecodeError:
return ''
flag_pattern = re.compile(r'[ -~]{4,20}') # 放宽长度限制
found_flags = False
for tensor_name, tensor in state.items():
print(f"\n检查张量:{tensor_name}")
# 尝试不同的缩放方法
scales = [0.01, 0.1, 1, 100, 255, 500, 1000] # 多种可能的缩放因子
for scale in scales:
text = tensor_to_text(tensor, scale)
if text and flag_pattern.fullmatch(text):
print(f"发现可打印字符 (scale={scale}):{text}")
found_flags = True
# 检查原始整数值
if tensor.dtype in (torch.int32, torch.int64):
try:
int_text = bytes([x & 0xFF for x in tensor.flatten().tolist()]).decode('utf-8')
if int_text and flag_pattern.fullmatch(int_text):
print(f"发现潜在可打印字符 (原始整数值):{int_text}")
found_flags = True
except:
pass
if not found_flags:
print("未在任何张量中发现符合格式的可打印字符")
pth_file = "attachment-38.pth"
state = analyze_pth_file(pth_file)
if state is not None:
display_tensor_info(state)
extract_potential_flags(state)
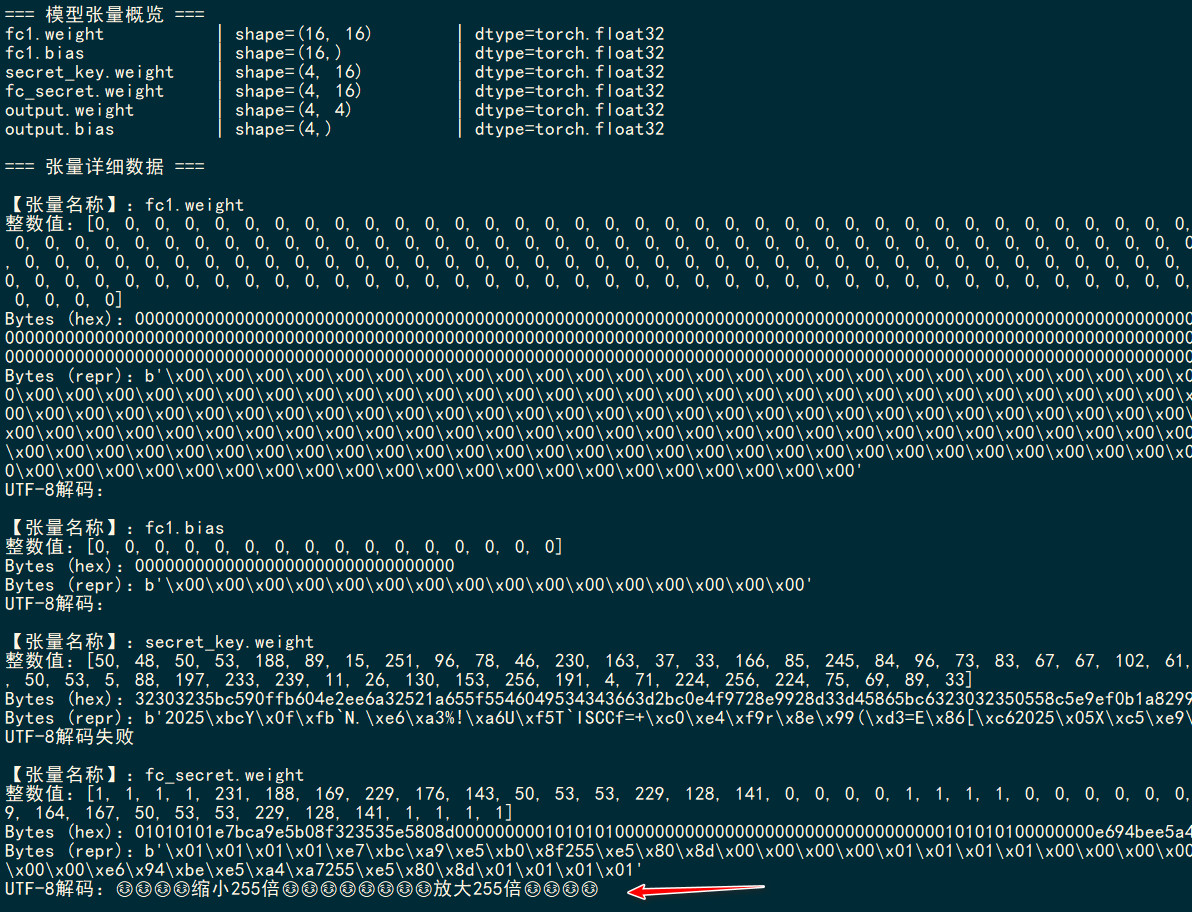
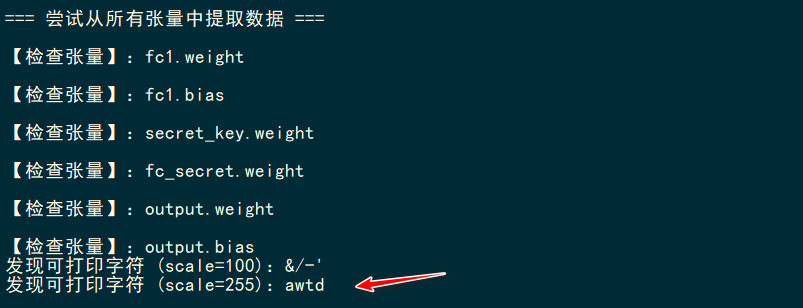
另外有非预期解,就是用7z直接打开pth文件,就能看见model_xxxx的文件夹,xxxx就是对应的flag,后续修复了。
ISCC{awtd}
6、八卦

时序乾坤震巽坎离艮兑
010 Editor查看是GIF文件,添加后缀,尾部还有1个7z文件,直接分离
7z文件解压缩需要密码,盲猜密码从GIF文件获取,工具导出GIF信息
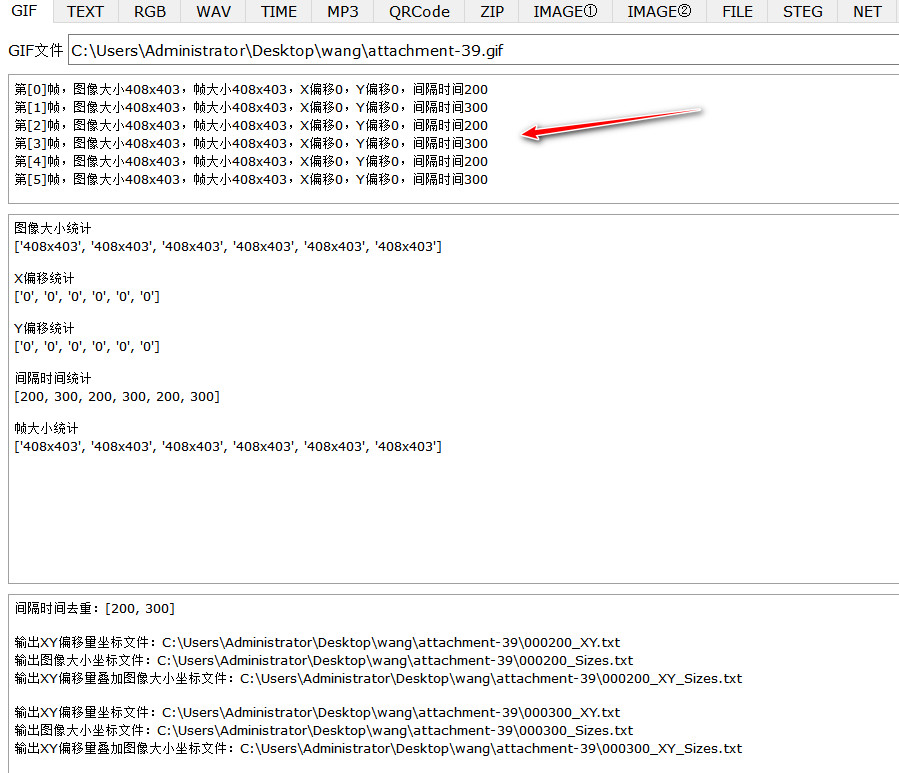
一共导出6帧图像,每帧图像间隔时间不同
第[0]帧,图像大小408x403,帧大小408x403,X偏移0,Y偏移0,间隔时间200
第[1]帧,图像大小408x403,帧大小408x403,X偏移0,Y偏移0,间隔时间300
第[2]帧,图像大小408x403,帧大小408x403,X偏移0,Y偏移0,间隔时间200
第[3]帧,图像大小408x403,帧大小408x403,X偏移0,Y偏移0,间隔时间300
第[4]帧,图像大小408x403,帧大小408x403,X偏移0,Y偏移0,间隔时间200
第[5]帧,图像大小408x403,帧大小408x403,X偏移0,Y偏移0,间隔时间300
200 300 200 300 200 300
0、1、2、4帧图像上存在Base编码
0帧:5Lm+5Li65aSp
乾为天 乾乾
1帧:4WY3DZVQWTUJFGl=
山水蒙 艮坎
2帧:5rC06Zu35bGv
水雷屯 坎震
4帧:42YLJZNEVHUZZAA=
水天需 乾坎
每一帧都存在LSB隐写
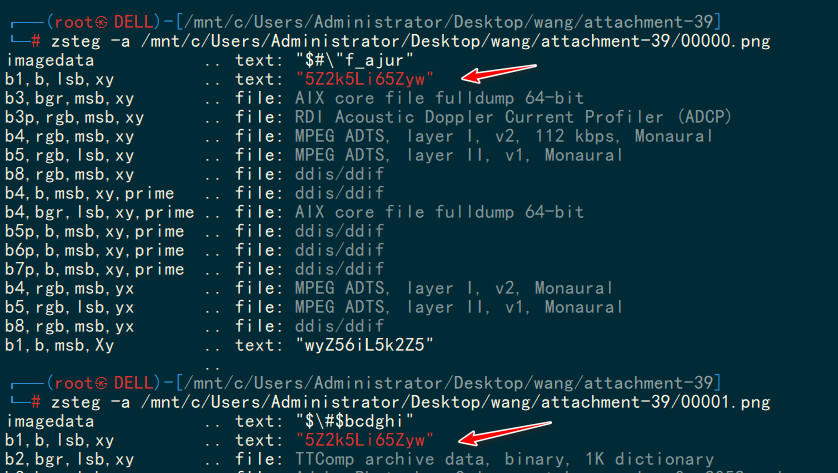
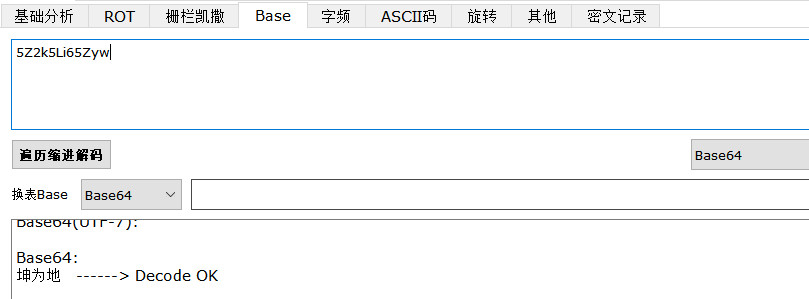
坤为地 坤坤
至此获得了六十四卦中的五卦,且是前五卦
第一卦 乾 乾为天 乾上乾下
第二卦 坤 坤为地 坤上坤下
第三卦 屯 水雷屯 坎上震下
第四卦 蒙 山水蒙 艮上坎下
第五卦 需 水天需 坎上乾下
方法一:根据Hint一共就七卦,穷举所有密码组合
import itertools
bagua = ["乾","兑","离","震","巽","坎","艮","坤"]
pwd = "乾乾坤坤坎震艮坎坎乾"
out = ""
for i in itertools.product(bagua,repeat=4):
out = out + pwd + "".join(i) + "\n"
print(out)
可以得到4096个密码组合,保存成字典,中文字典ANSI编码,直接爆破
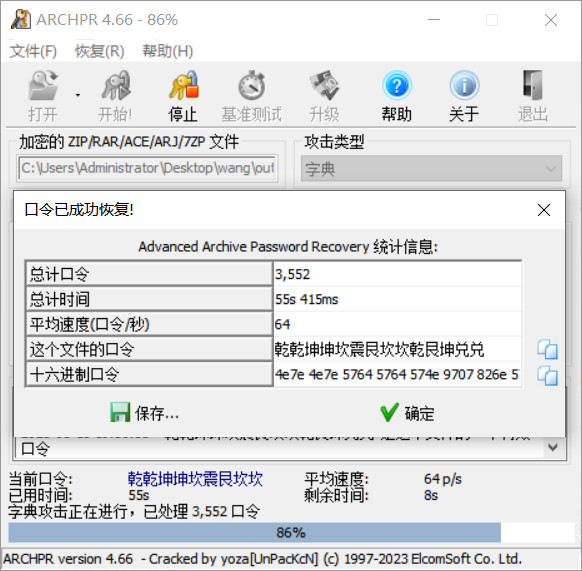
解压缩密码:乾乾坤坤坎震艮坎坎乾艮坤兑兑
方法二:开脑洞,帧时间间隔分析:200 300 200 300 200 300,指的是第二十三卦艮坤;帧内容分析:0、1、2、4帧图像上存在Base编码,111010,二进制转十进制;第五十八卦兑兑
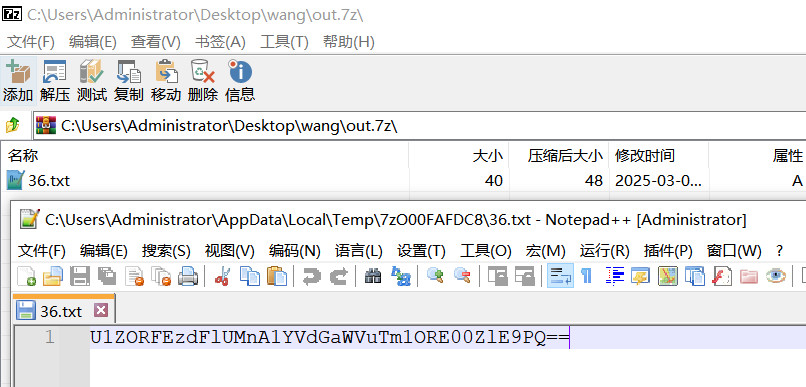
U1ZORFEzdFlUMnA1YVdGaWVuTm1ORE00ZlE9PQ==,连续2次Base64解码
ISCC{XOjyiabzsf438}

















 3333
3333

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









