




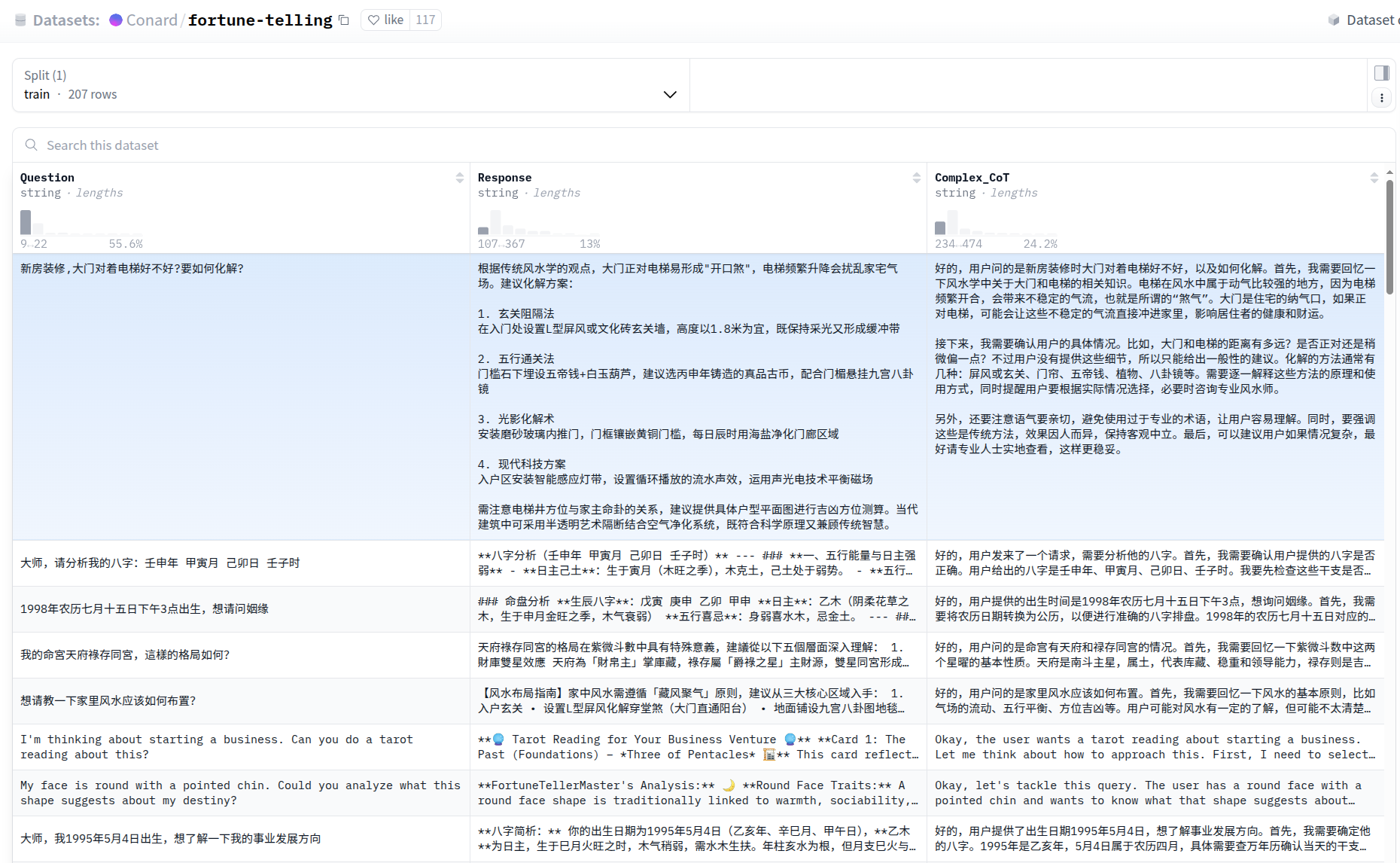
本文基于B站up主 code秘密花园 的代码编写,源码地址 ,并说明有关潜在的坑。如果无法打开也可以在文章后面找到源码。该代码使用unsloth框架微调DeepSeek-R1-Distill-Llama-8B,数据集使用https://huggingface.co/datasets/Conard/fortune-telling, 旨在将模型微调为一个算命大师。
数据集格式:{ Question, Response, Complex_CoT } ,因为微调的是一个推理模型,所以包含思维链。
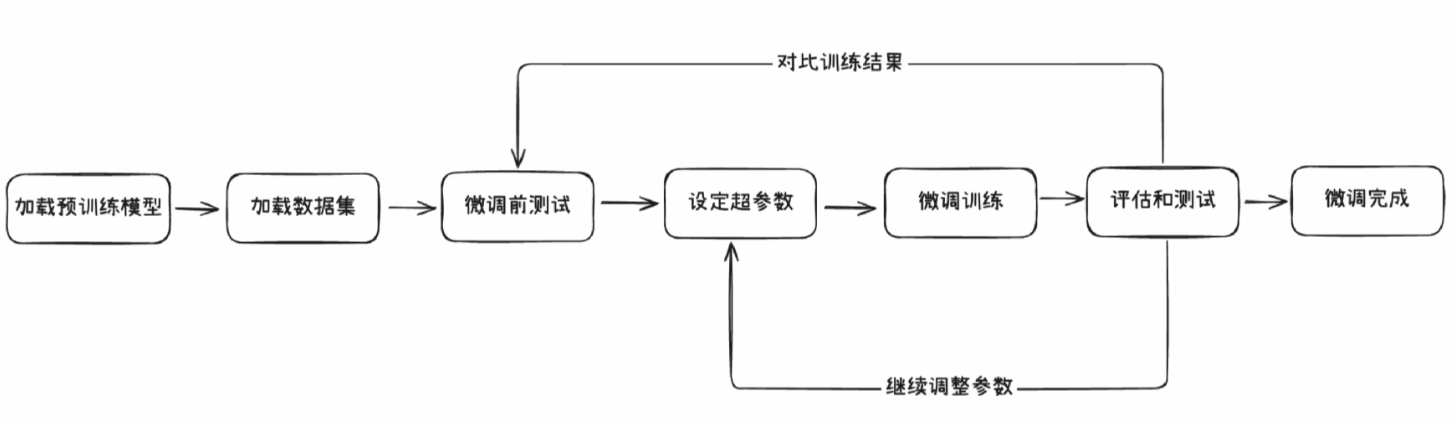
微调的大致流程如下
环境安装
需要安装conda、cuda、unsloth。conda和cuda不赘述了,unsloth可在官方仓库中找到安装方法。
conda create --name unsloth_env \
python=3.11 \
pytorch-cuda=12.1 \
pytorch cudatoolkit xformers -c pytorch -c nvidia -c xformers \
-y
conda activate unsloth_env
pip install unsloth源码
设置代理
这一步不是源码给出的。主要用于设置代码涉及网络请求的时候设置代理,避免下载失败。前提是已经有了代理,比如clash的代理端口是7890,这时就可以直接直接将127.0.0.1:7890作为代理地址。
import os
os.environ["http_proxy"] = "http://127.0.0.1:7890"
os.environ["https_proxy"] = "http://127.0.0.1:7890"加载模型
from unsloth import FastLanguageModel # 导入FastLanguageModel类,用来加载和使用模型
import torch # 导入torch工具,用于处理模型的数学运算
max_seq_length = 2048 # 设置模型处理文本的最大长度,相当于给模型设置一个“最大容量”
dtype = None # 设置数据类型,让模型自动选择最适合的精度
load_in_4bit = True # 使用4位量化来节省内存,就像把大箱子压缩成小箱子
# 加载预训练模型,并获取tokenizer工具
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="unsloth/DeepSeek-R1-Distill-Llama-8B", # 指定要加载的模型名称
max_seq_length=max_seq_length, # 使用前面设置的最大长度
dtype=dtype, # 使用前面设置的数据类型
load_in_4bit=load_in_4bit, # 使用4位量化
token="hf_...", # 如果需要访问授权模型,可以在这里填入密钥
)运行效果如下,这一步是在从huggingface上下载unsloth/DeepSeek-R1-Distill-Llama-8B模型,也就是 https://huggingface.co/unsloth/DeepSeek-R1-Distill-Llama-8B 。其中token参数不需要填写。
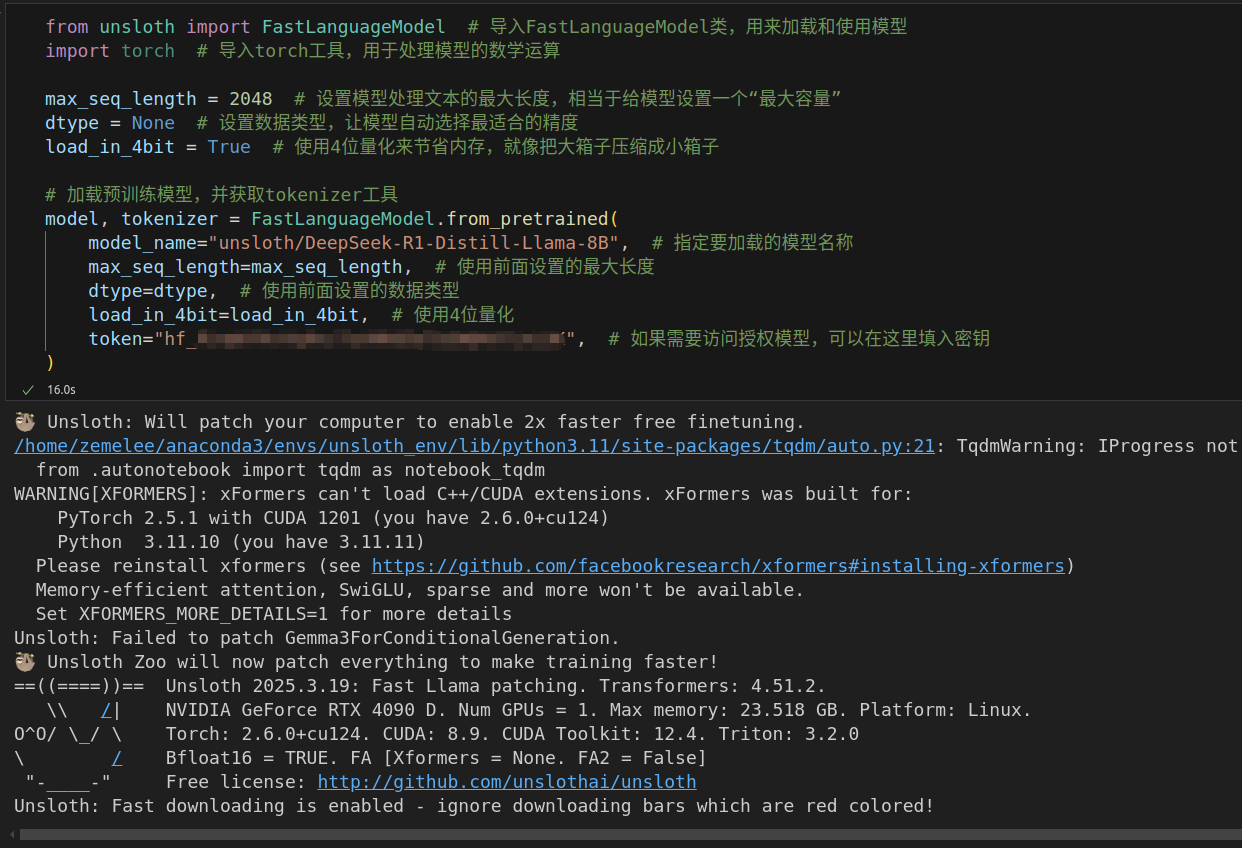
如果下载的时候报错,可以参考下设置代理的步骤。可能不会出现进度条,但是通过clash的显示可以确定,他正在疯狂下载模型。网速飙到了40MB/s...
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9711
9711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









