



微调的难点之一在与数据集。本文介绍一种将文档转换为问答数据集的方法,超级快!
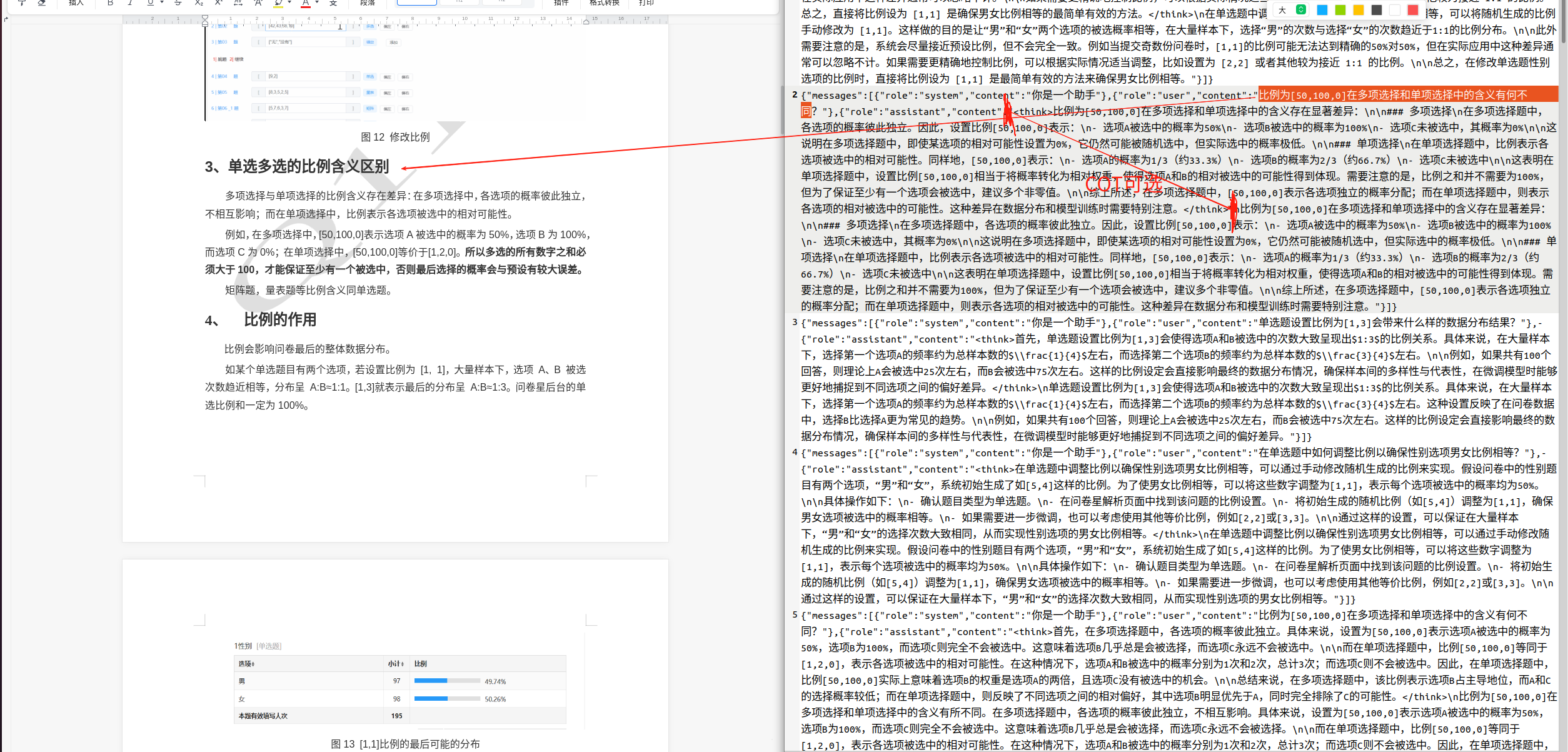
上图左侧是我的原文档,右侧是我基于文档生成的数据集。
原理是通过将文档片段发送给ollama本地模型,然后本地模型生成有关问题,并基于文档片段回答问题。需要用到的工具有ollama,easy-dataset: https://github.com/ConardLi/easy-dataset
ollama安装就不赘述了,easy-dataset是一个前端项目,只需要有nodejs就能运行起来了。
进入easydataset的运行界面,新建项目,会被要求添加模型。如果ollama在运行,easydataset能检测到已安装的模型。

首先需要将文档拆分成md格式,MinerU 可以很好做到这一点。
然后将md文件上传到easydataset,easydataset会将其拆分成若干个片段,并针对每个片段生成若干个问题,最后再对每个问题进行回答,问答对就完成了。
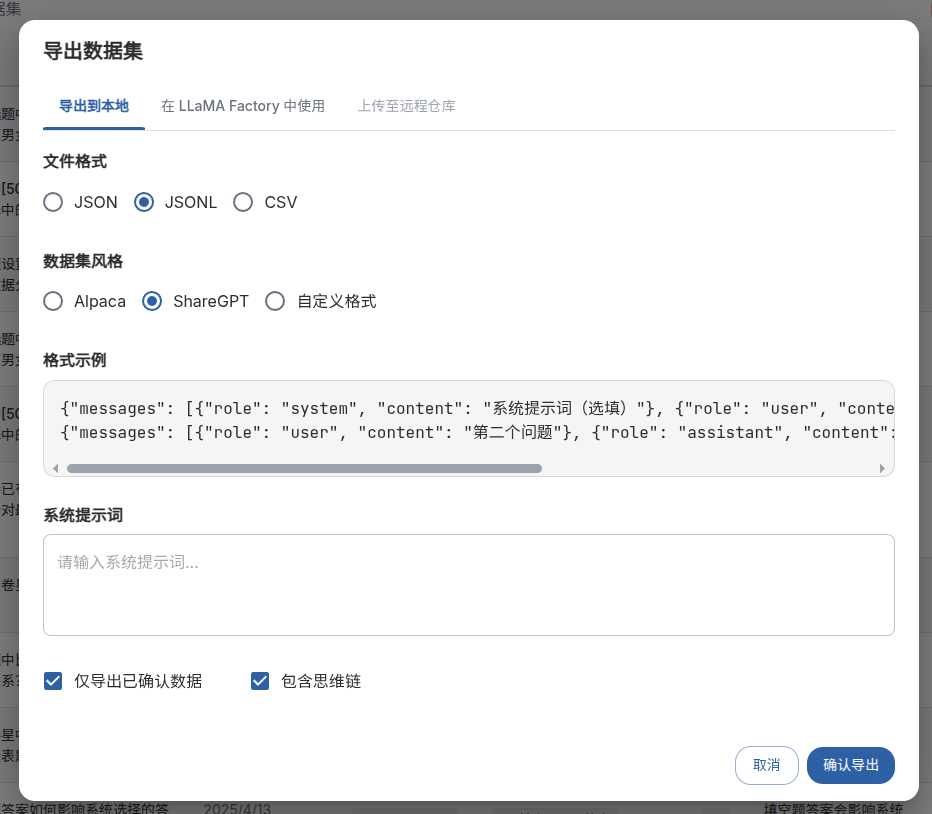
按照需要的格式导出,就能直接作为数据集文件了。
数据集格式介绍可参考Unsloth 基于自己的数据集微调建立专属模型_unsloth微调-优快云博客

















 1428
1428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









