






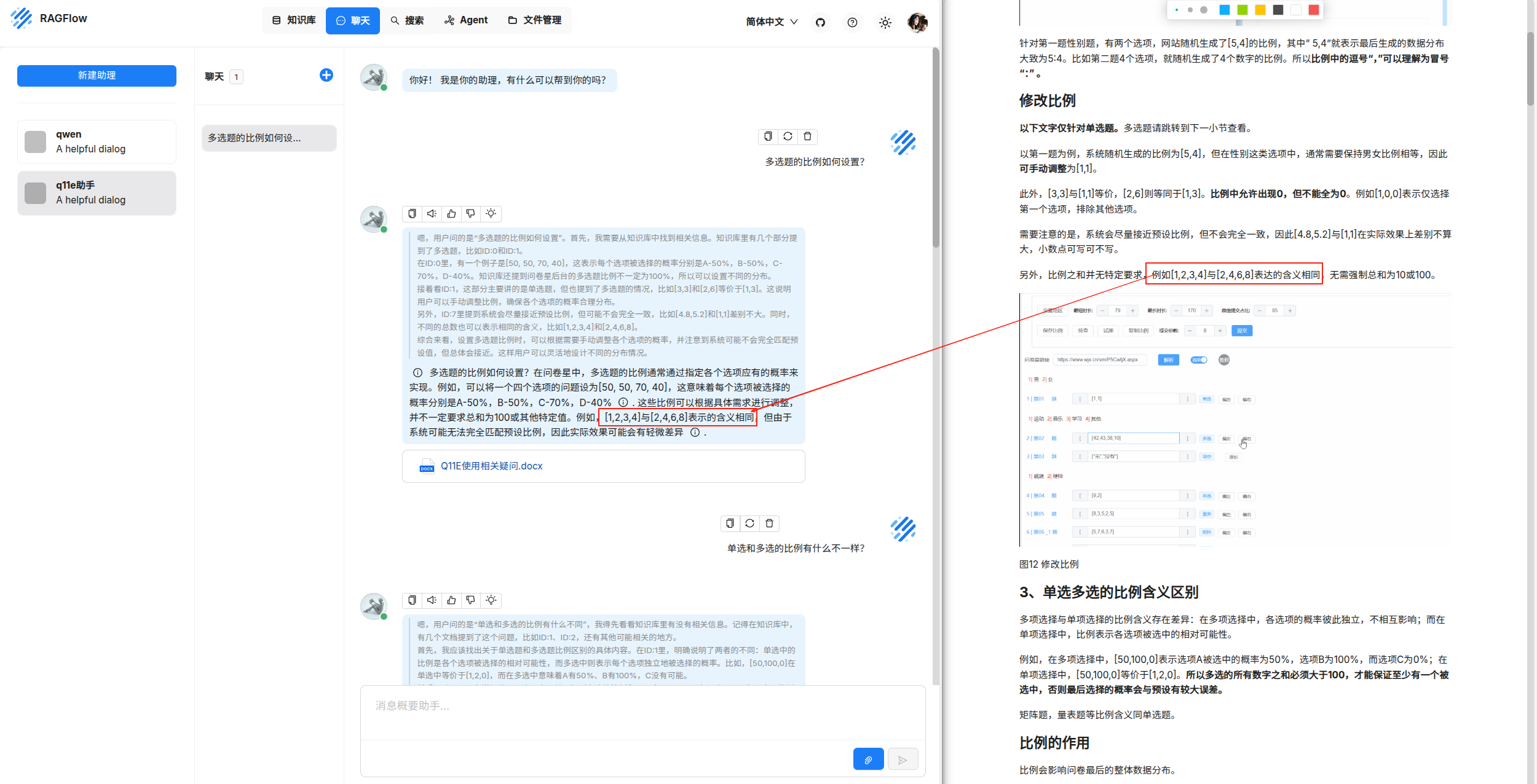
1、最终效果
实现了基于本地文档内容的对话问答
2、环境部署
我的机器配置是ubuntu20+4090d+i7,没有这么高也是可以跑的
2.1安装ollama
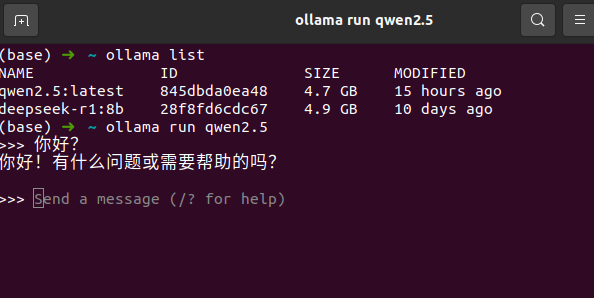
有了ollama,就可以在本地跑一个大模型了。不联网也可以运行,实现了绝对隐私和token自由。
ollama官网:https://ollama.com/download 根据自己系统下载即可。
终端输入ollama不报错说明安装成功了。
然后可以在ollama模型广场下载合适的模型,https://ollama.com/search ,模型太大本地可能带不动,太小可能性能不好,需要权衡。建议先下载个1-10G的试水。
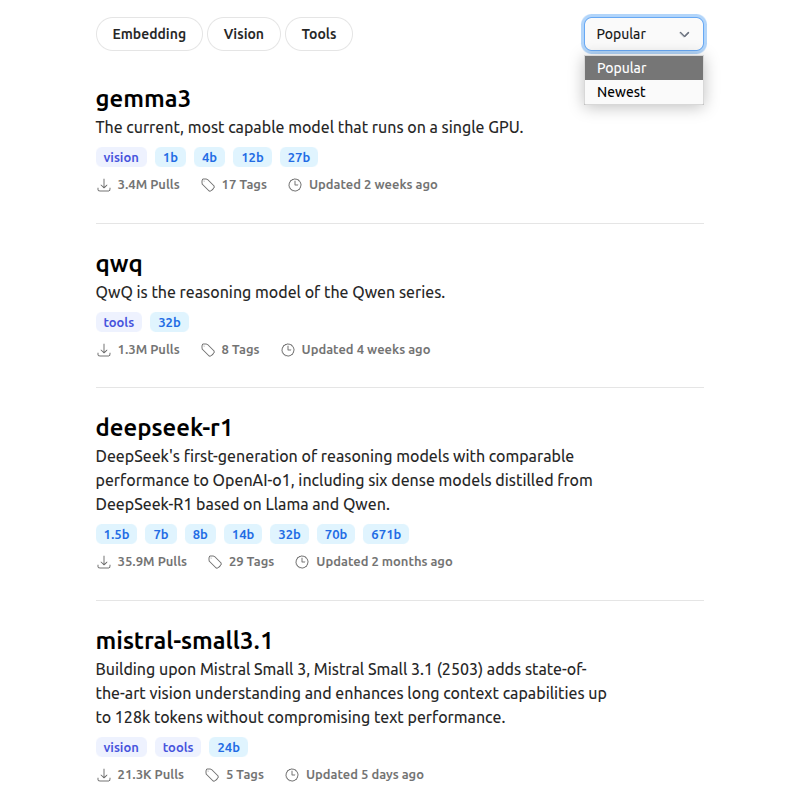
这里有很多主流模型,deepseek、qwen、mistral、谷歌的gemma、meta的llama等等。
以deepseek-r1为例,8b参数量的模型为4.9GB,只需要拷贝右边的命令到终端就可以自动下载了,而且支持断网续传。如果太慢需要挂代理,虚拟机的话可以用clash的7890端口作为代理转发端口。
ollama run deepseek-r1:8b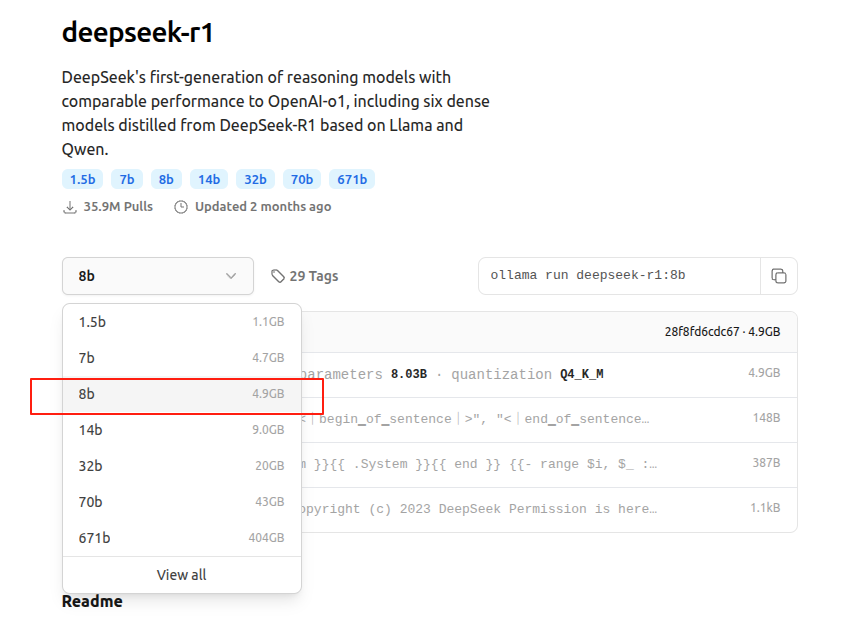
然后输入 ollama list 输出里应该包含deepseek,就说明部署成功了
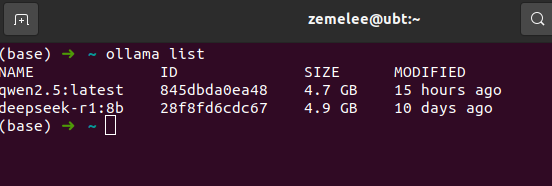
然后再运行一遍 ollama run deepseek-r1:8b 就能直接在终端对话了。如果回复速度比较慢,就需要考虑还一个更小的模型。
2.2 安装ragflow
官方建议配置如下:

ragflow官方仓库: https://github.com/infiniflow/ragflow/blob/main/README_zh.md
首先需要将仓库clone下来。
git clone https://github.com/infiniflow/ragflowragflow以来docker运行。所以环境中需要包含docker,此处不赘述。
由于ragflow默认下载轻量版本的镜像(v0.17.2-slim),slim并不自带embedding模型。要么需要自己再部署一个embedding模型,要么调用在线embedding模型api。这里选择下载完整版本的ragflow,避免再次配置。
为了使得下载完整版镜像,需要修改配置文件。进入ragflow文件夹的docker,修改.env文件(如果没有看到.env需要开启文件系统的“显示隐藏文件”选项)
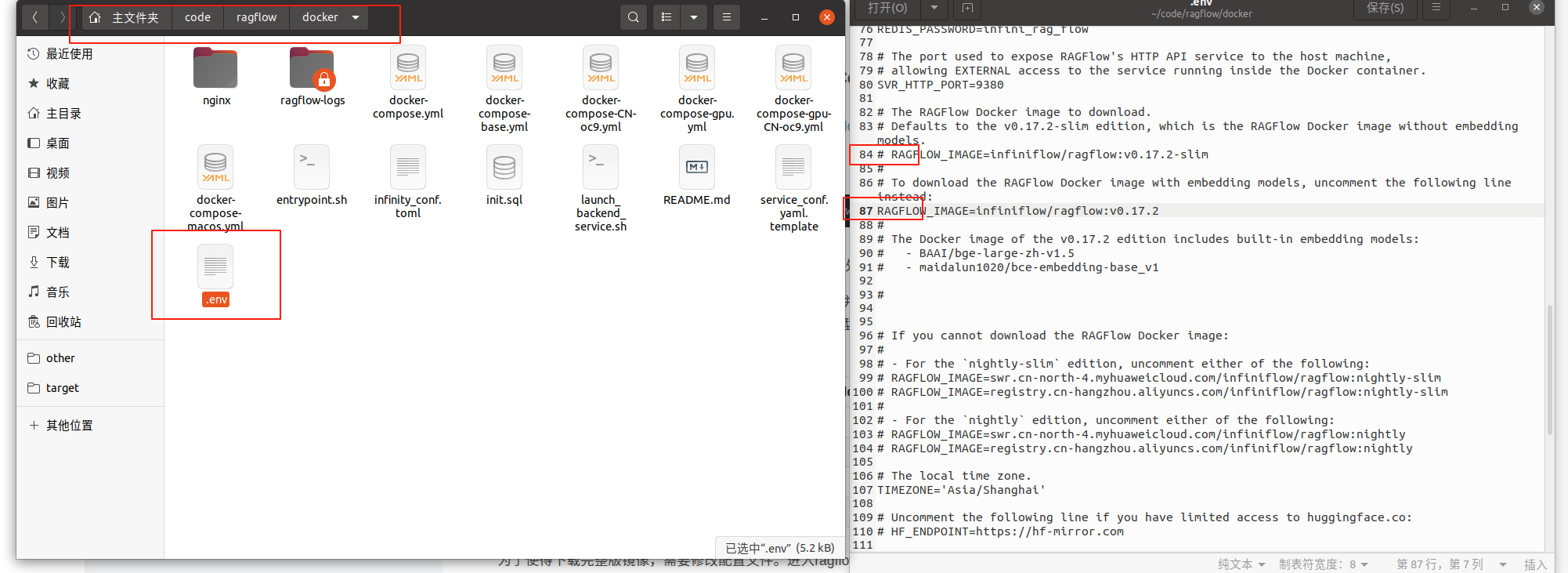
注释84行,取消注释87行,修改成上面的样子。
然后在docker文件夹中打开终端,输入以下代码就可以运行ragflow了。
docker compose -f docker-compose.yml up -d如果报错,可以检查自己的80端口是否被占用,docker使用在运行。
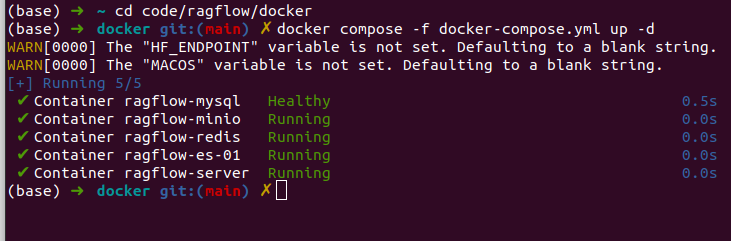
然后就能直接通过浏览器访问localhost:80了,即ragflow的操作界面
3、ragflow配置(构建知识库)
在ragflow登录页注册一个root用户,进入模型提供商页面
3.1添加模型
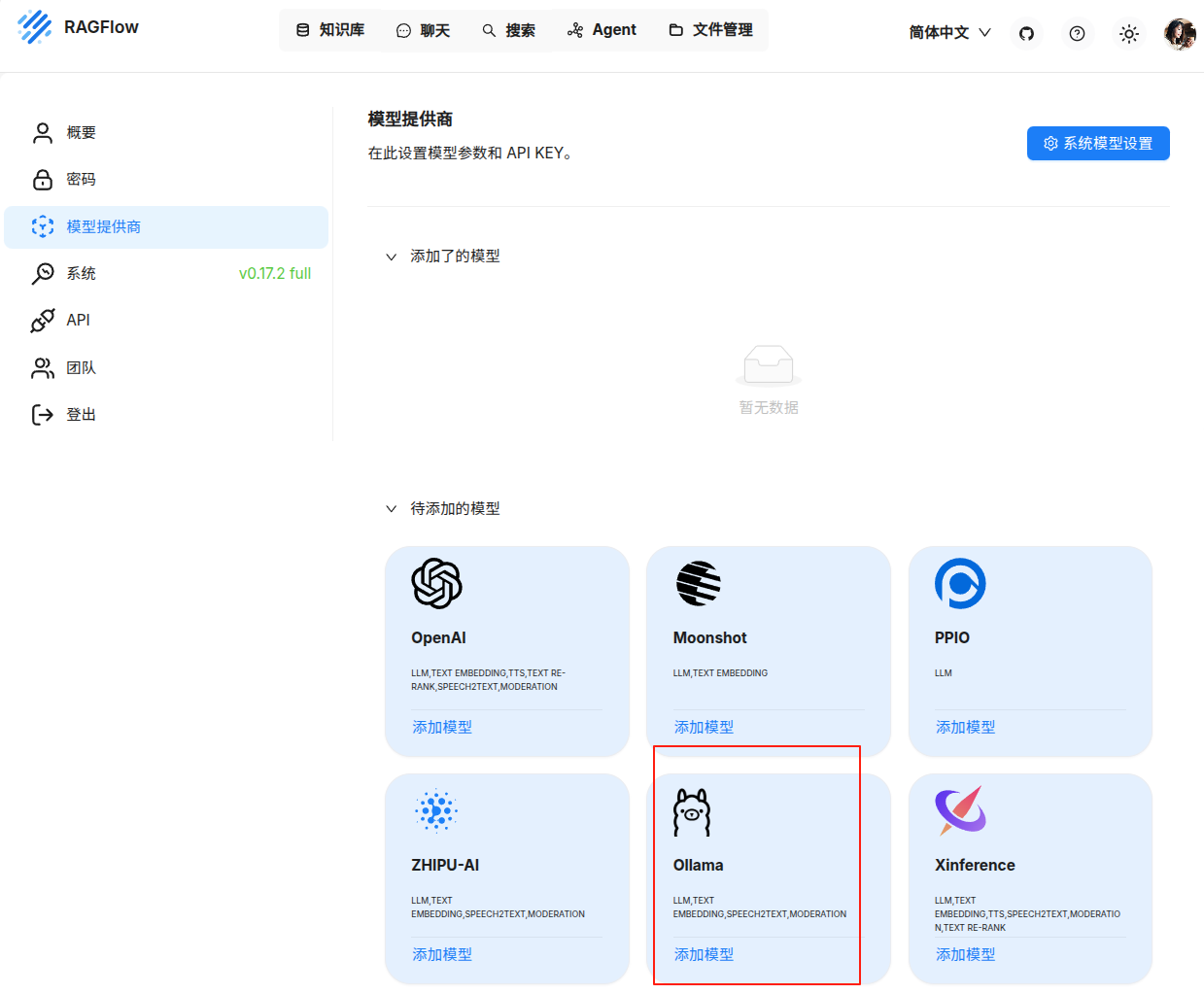
找到ollama,点击添加模型
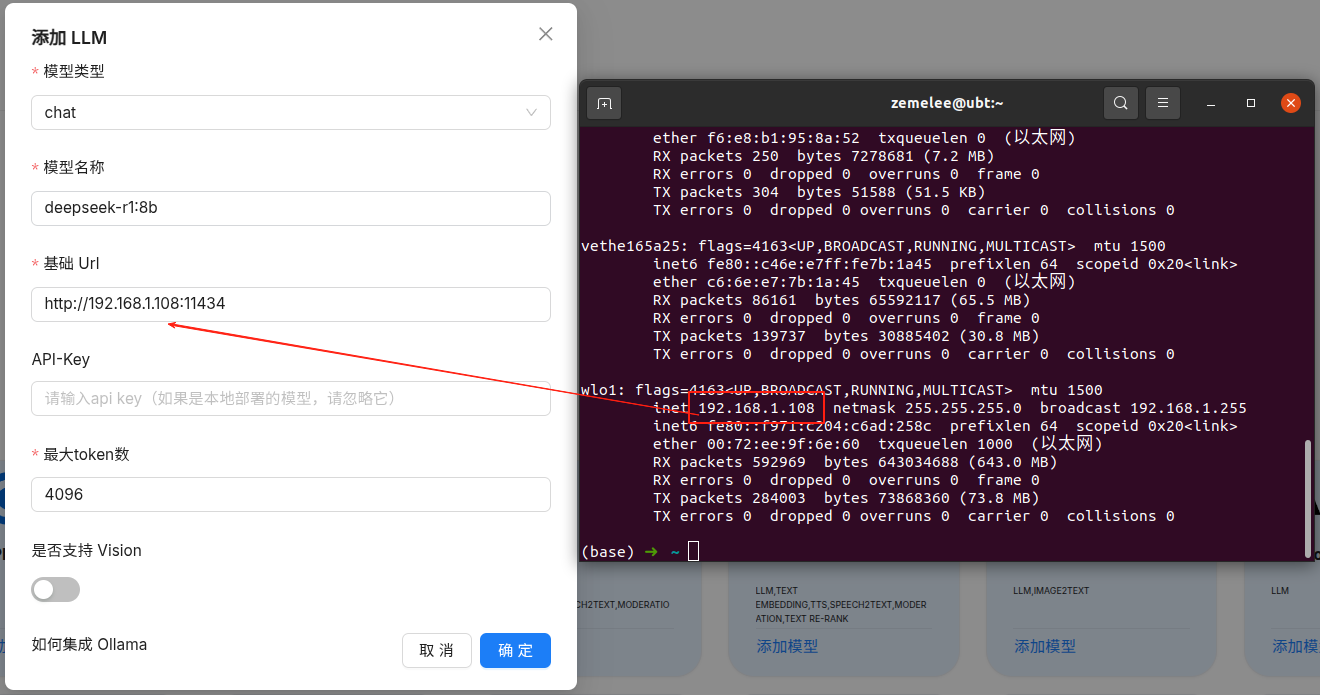
按照以上配置进行,模型名称一定是完整的模型名称,不能只输入deepseek,基础url就是本机ip加上11434(11434ollama的运行端口),ip不能是127.0.0.1。最大token数就是模型输出的最大token数,由于是本地部署所以不需要api-key,r1属于chat模型。
点击系统模型设置,选择嵌入模型(完整版ragflow自带的)

3.2添加助理
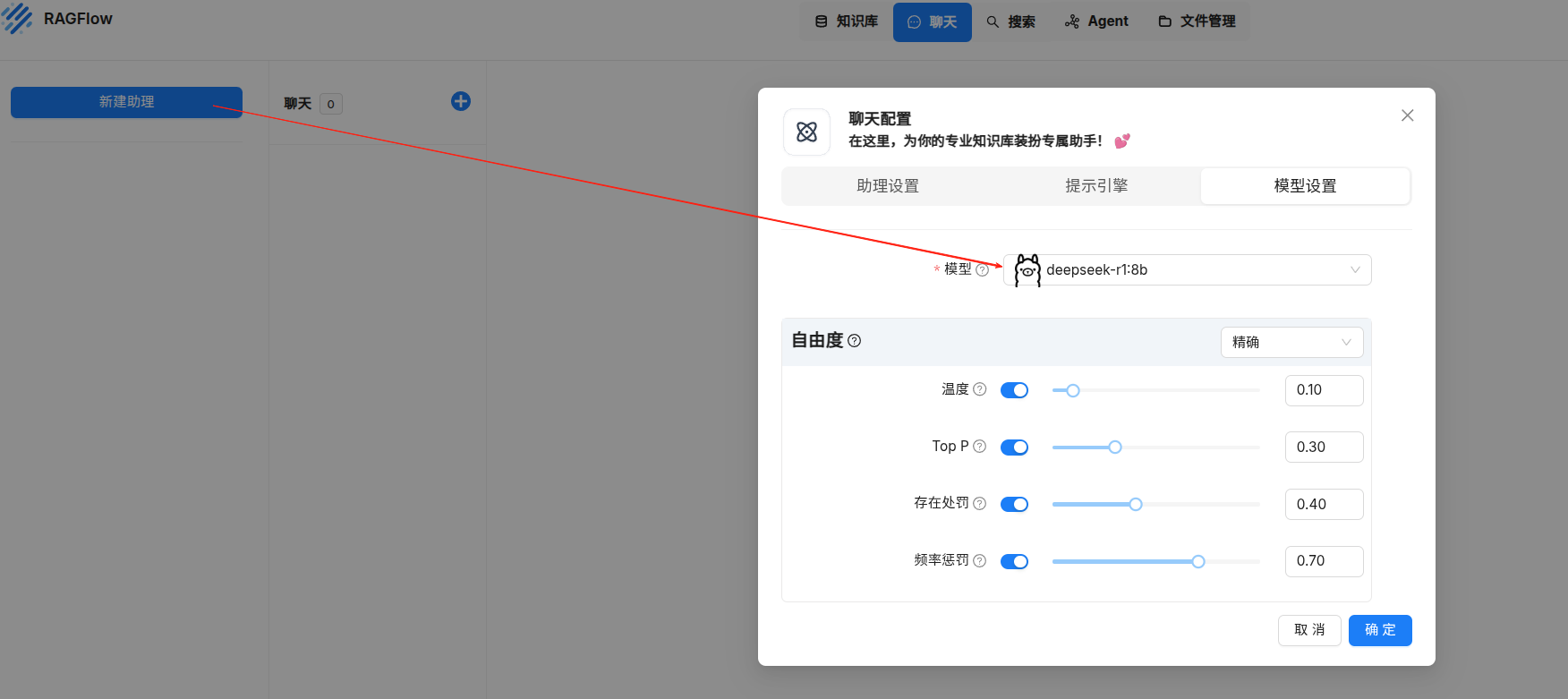
然后就能在ragflow里自由的与ds聊天了,但是现在还没有外接知识库。

3.3构建知识库
新增知识库test后,参数默认即可。选择文档后,还需要点击解析才能被模型检索到。

选择知识库
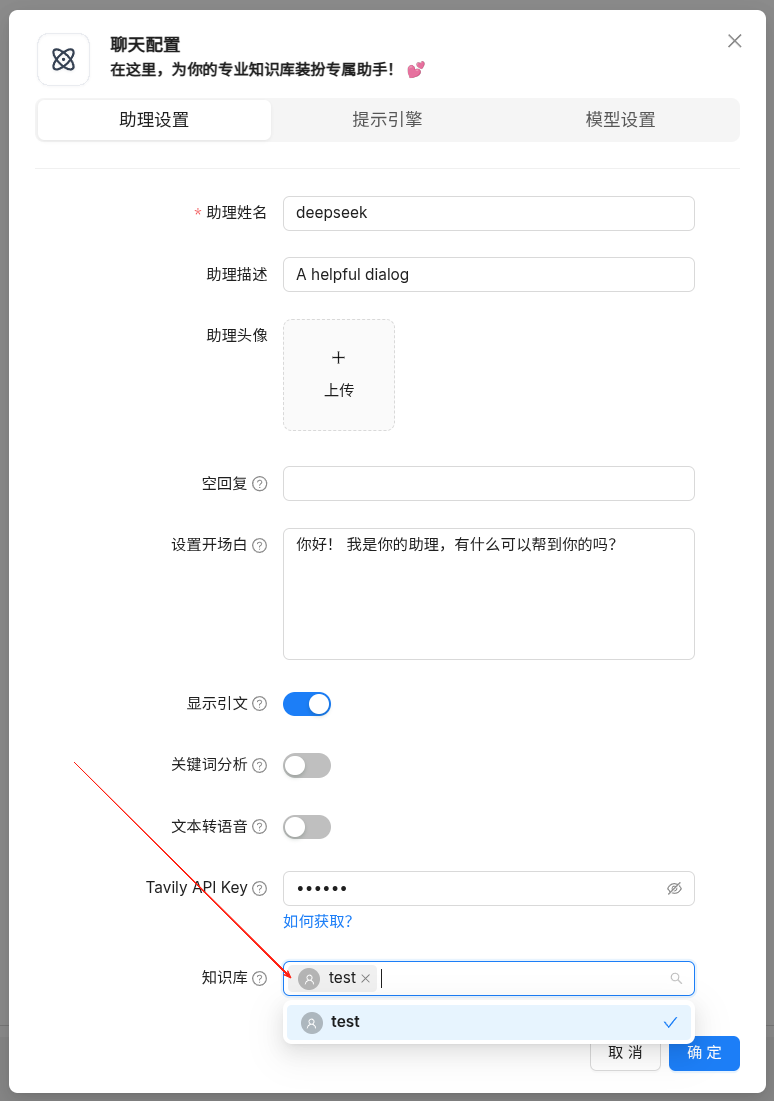
3.4测试

















 9205
9205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









