






一、介绍
本次为大家演示一个实验项目,实验内容是使用k-means聚类算法与层次聚类算法 与机器学习,为一张小狗图片(dog.jpg)的像素点进行聚类,旨在实现图像中相似颜色区域的分割。¶
【重点】在层次聚类算法中 ,使用映射原理!解决内存过大无法跑出结果的问题!!
【注意】此推文比较适合于有python基础与大数据分析技术的人员 与 对大数据分析聚合算法感兴趣的 人员 阅览,我会在文章中给出详细的注释与解释
二、题目相关
dog.jpg图片

将此图片使用k-means聚类算法与层次聚类算法进行颜色划分
三、开始使用python编写算法操作,解决问题
1.需要导入的库
【注意】需要提前配置与安装Batch ,导入库以后,这些代码才有效
import numpy as np
import matplotlib.pyplot as plt
import cv2
from mpl_toolkits.mplot3d import Axes3D
from sklearn.cluster import KMeans, AgglomerativeClustering
from sklearn.neighbors import KNeighborsClassifier2.初始的准备工作
包括:
1. 图像加载与预处理
2. 展示原图与 可视化 展示 RGB三维分布
# -------------------------- 1. 图像加载与预处理 --------------------------
# 读取原图并转RGB
image_original = cv2.imread('dog.jpg')
image_original = cv2.cvtColor(image_original, cv2.COLOR_BGR2RGB)
# 缩小图像(最长边200,进一步降低采样基数)
max_size = 200
h, w = image_original.shape[:2]
scale = max_size / max(h, w)
image = cv2.resize(image_original, (int(w*scale), int(h*scale)))
H, W, C = image.shape
pixel_data = image.reshape(-1, 3) # 全量像素(比如200x200=4万像素)
# -------------------------- 2. 展示原图与RGB三维分布 --------------------------
plt.figure(figsize=(12, 5))
# 原图
plt.subplot(1, 2, 1)
plt.imshow(image_original)
plt.title('Original Image')
plt.axis('off')
# RGB三维散点图(用全量像素,点设小避免卡顿)
ax = plt.subplot(1, 2, 2, projection='3d')
r, g, b = pixel_data[:, 0], pixel_data[:, 1], pixel_data[:, 2]
ax.scatter(r, g, b, c=pixel_data/255.0, alpha=0.4, s=1)
ax.set_xlabel('Red')
ax.set_ylabel('Green')
ax.set_zlabel('Blue')
ax.set_title('3D Color Distribution (RGB Space)')
ax.set_xlim(0, 255)
ax.set_ylim(0, 255)
ax.set_zlim(0, 255)
plt.tight_layout()
plt.show()
3.k-mean的实现
# -------------------------- 3. K-means聚类分割(不变)--------------------------
K = 4
kmeans = KMeans(n_clusters=K, random_state=0)
kmeans_labels = kmeans.fit_predict(pixel_data)
# 处理空聚类
kmeans_means = []
for i in range(K):
mask = (kmeans_labels == i)
kmeans_means.append(np.mean(pixel_data[mask], axis=0) if np.any(mask) else [0, 0, 0])
kmeans_means = np.array(kmeans_means, dtype=np.uint8)
segmented1 = kmeans_means[kmeans_labels].reshape(H, W, C)
【注意】
指定超参数(人为指定的参数),分成4簇类:
K=4
fit和predict(机器学习:自动训练与预测):
kmeans_labels = kmeans.fit_predict(pixel_data) 处理空聚类:
(空聚类:聚类算法预设了要分 M/K 个类别,但最终有一个或多个类别里,一个像素(样本)都没有分配到—— 相当于你准备了 4 个盒子装苹果,结果有 1 个盒子是空的。)
kmeans_means.append(np.mean(pixel_data[mask], axis=0) if np.any(mask) else [0, 0, 0])空聚类有啥影响?
如果不处理空聚类,直接算np.mean(pixel_data[mask], axis=0)(mask 是空的),numpy 会:
- 报
RuntimeWarning: Mean of empty slice警告(提示 “你在算空数组的均值”); - 得到
nan(非数字)结果; - 用
nan去重建图像,会出现黑色 / 异常闪烁的像素,分割图就废了
我的处理:
if np.any(mask) else [0, 0, 0]np.any(mask):检查当前类别有没有像素(mask 里有没有 True);- 有像素:正常算该类所有像素的 RGB 均值;
- 空聚类:直接给个默认颜色
[0,0,0](黑色,也能改成[255,255,255],[0,0,0]表示白色等);这样就避免了警告和异常像素,分割图能正常生成~
4. 层次聚类算法
(先总体预览代码)
# -------------------------- 4. 采样层次聚类(核心改进)--------------------------
M = 4
sample_ratio = 0.05 # 只取5%的像素做层次聚类(比如4万像素取2000个)
n_samples = max(1000, int(pixel_data.shape[0] * sample_ratio)) # 最少取1000个样本
# 1. 随机采样像素
np.random.seed(42) # 固定种子,结果可重复
sample_indices = np.random.choice(pixel_data.shape[0], n_samples, replace=False)
pixel_sample = pixel_data[sample_indices] # 采样后的像素(小数据集)
# 2. 对采样像素做层次聚类(内存压力极小)
reg = AgglomerativeClustering(n_clusters=M, linkage="complete")
sample_labels = reg.fit_predict(pixel_sample) # 此时n=2000,距离矩阵仅2000*1999/2=200万元素
# 3. 用KNN把采样标签映射到全量像素(让所有像素都有类别)
knn = KNeighborsClassifier(n_neighbors=5) # 找最近的5个采样点投票
knn.fit(pixel_sample, sample_labels)
hier_label = knn.predict(pixel_data) # 全量像素的层次聚类标签
# 4. 计算聚类均值,重建分割图
hier_means = []
for i in range(M):
mask = (hier_label == i)
hier_means.append(np.mean(pixel_data[mask], axis=0) if np.any(mask) else [0, 0, 0])
hier_means = np.array(hier_means, dtype=np.uint8)
segmented2 = hier_means[hier_label].reshape(H, W, C)
【注意】M=4的意思是最后的结束时会被分成四簇!!
这里并非传统意义上的层次聚类算法:
【附】传统意义的层次聚类算法原理是:将所有点进行层次聚类划分。会有弊端:
层次聚类(如AgglomerativeClustering)的致命弱点是:它需要计算所有样本之间的距离(构建距离矩阵),而距离矩阵的大小是n*(n-1)/2(n是样本数)。
- 当
n=4万(比如 200x200 的图像),距离矩阵有4万*3.9999万/2 ≈ 8亿个元素,按 float64 类型算,需要约 6.4GB 内存(直接撑爆普通电脑);
所以,我们得将传统算法进行改进:
也就是:
只取 全部像素中的 5% 的像素做层次聚类!!!
- 当
n=2000(4 万的 5%),距离矩阵只有2000*1999/2 ≈ 200万个元素,仅需约 16MB 内存(普通电脑轻松承载)。
简单说:通过减少参与层次聚类的像素数量,能把内存需求从 “GB 级” 压降到 “MB 级”,避免内存溢出。(空间复杂度降低)
为什么是 “5%”?
5% 是一个经验值,核心是 “在保证聚类效果的前提下,尽可能减少样本数”:
- 比例太高(比如 30%):样本数依然较多(4 万像素取 1.2 万),距离矩阵还是很大(约 7.2 亿元素,5.8GB),可能仍会内存不足;
- 比例太低(比如 0.5%):样本数太少(4 万取 200),可能无法代表原图的颜色分布,导致聚类结果失真(比如漏了重要颜色类别)。
5% 左右的比例,既能让样本数足够少(内存可控),又能基本保留原图的颜色分布特征(聚类结果和全量像素的层次聚类接近)。
接下来,我们看KNN算法是如何处理好没有归类好的点 (95%)其中的已经归类好的点的关系的(5%)
简要原理!推广!
总结:推广的本质
“推广到全图” 不是凭空猜类别,而是基于 “颜色相似性” 的合理推导:
- 用少量采样像素跑层次聚类,得到 “颜色 - 类别” 的对应关系;
- 用 KNN 算法,把这种 “颜色 - 类别” 关系,复制到全图所有像素上;
- 最后统一替换成类平均色,完成全图分割。
推广的 3 个核心步骤(对应代码)
1. 给 KNN 算法 “喂素材”(学习阶段)
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(pixel_sample, sample_labels)这一步是让 KNN “记住” 所有采样像素的 “特征(颜色)” 和 “类别(标签)”。可以理解为:给 KNN 一本 “字典”,里面记着 2000 个 “样板”—— 每个样板都写着 “我的颜色是 XXX,我的类别是 YYY”。KNN 学完后,就知道 “什么样的颜色,大概率属于哪个类别” 了。
2. 给全图像素 “贴标签”(推广阶段)
hier_label = knn.predict(pixel_data)这一步是推广的核心,对全图每个像素逐个处理,逻辑如下:
- 拿全图某个像素 A(比如颜色
(120,40,60)); - KNN 在 “字典” 里,找和 A 颜色最像的 5 个采样像素(
n_neighbors=5,也就是 5 个 “邻居”); - 看这 5 个邻居的类别:比如 3 个属于类别 0,2 个属于类别 1;
- 投票决定:哪个类别占比最高(这里是类别 0),就给像素 A 贴上个 “类别 0” 的标签;
- 重复这个过程,给全图所有像素都贴好标签。
这里的关键是 “颜色像 = 类别同”—— 我们默认:RGB 颜色接近的像素,语义上也属于同一类(比如都是狗的毛发、都是背景天空),所以可以直接继承类别。
3. 重建全图分割结果(收尾阶段)
# 先算每个类的平均颜色(处理空聚类)
hier_means = []
for i in range(M):
mask = (hier_label == i)
hier_means.append(np.mean(pixel_data[mask], axis=0) if np.any(mask) else [0,0,0])
hier_means = np.array(hier_means, dtype=np.uint8)
# 用标签替换颜色,重建全图
segmented2 = hier_means[hier_label].reshape(H, W, C)- 先根据全图所有像素的标签(包括采样和未采样的),计算每个类的平均颜色(比如类别 0 的所有像素,RGB 平均是
(110,50,65)); - 再把全图每个像素的颜色,替换成它所属类的平均颜色;
- 最后把展平的像素数组,恢复成图像的宽高形状 —— 这样就得到了全图的分割结果。
整个过程没有增加新的聚类逻辑,只是把采样像素的聚类结果 “扩散” 到全图,既省内存,又能保证分割效果和全量层次聚类接近。
【重点】knn算法优化与原方法
上述是正确的代码,使用knn算法优化,在本人第一次尝试的代码中,我使用全部像素点聚合的方式,结果空间复杂度过于高,使得程序无法运行。
本推文的目的不仅是展示基本的k-means与层次聚类算法解决具体问题的案例,还是要注意 在样本点过多(此处体现为像素点过多的时候),使用层次聚类需使用knn优化。
展示一下我第一次尝试写的层次聚类算法的代码:
# -------------------------- 4. 层次聚类分割--------------------------
M = 4
# 定义层次聚类模型(用缩小图的pixel_data,像素数少)
reg = AgglomerativeClustering(n_clusters=M, linkage="complete")
hier_label = reg.fit_predict(pixel_data) # 无内存溢出
# 计算聚类均值(处理空聚类)
hier_means = []
for i in range(M):
mask = (hier_label == i)
hier_means.append(np.mean(pixel_data[mask], axis=0) if np.any(mask) else [0, 0, 0])
hier_means = np.array(hier_means, dtype=np.uint8)
segmented2 = hier_means[hier_label].reshape(H, W, C) # 分割结果(缩小图尺寸)这是在此 ,执行不了的,因为空间复杂度过大
但退一万步来说,我们放眼这次实验的聚合图像的可视化结果,k-means确实效果优于层次聚类
下面是jupyter的可视化结果:
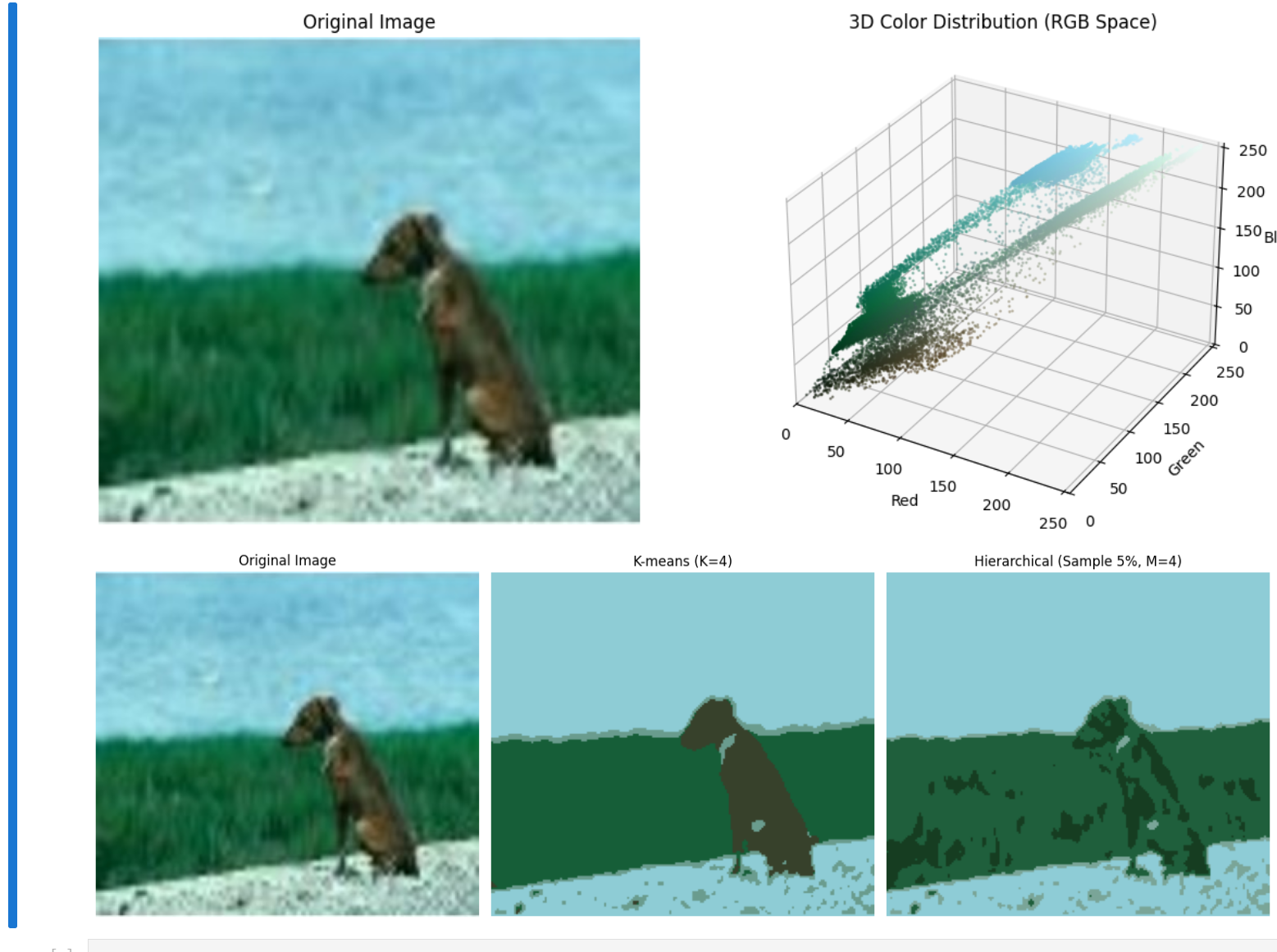
第一行第一个与第二行第一个是原图(dog.jpg) ,第一行第二个是RGB三维颜色分解可视化效果图,第二行第二个是k-means效果图,右边是层次聚类效果图!显然 k-means在这个案例中较优。
实际上来说,k-means适合处理传统意义上“团状”的图像
四、总结
我们在选取聚合机器学习算法的时候,应该依据经验 和结果 要选取最优算法,选取和填写最优超参数,综合考虑时间复杂度与空间复杂度,选取优化方案。
感谢大家的观看!点关注,不迷路!下次为大家选取更好的案例与讲解不同的算法。如果你觉得我的分享还不错,记得点上收藏和小心心哦!!!!谢谢大家的支持

















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}