







4.CRNN原理介绍
本文主要是根据论文《An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition》翻译总结而来。CRNN可以识别不同大小,不同长度的图片文字。论文还识别了乐谱,理论上该模型也可以有效的识别中文,不区分语言。
4.1.1.CRNN摘要
Convolutional Recurrent Neural Network (CRNN), 顾名思义,它是 CNN 和 RNN的结合体。最后又加了CTC。
4.1.2.CRNN模型结构
如下图所示,包括三层,从下到上分别是卷积层、RNN层、翻译层。卷积层提取图片特征。RNN层采用的是LSTM。在卷积层和RNN层中间创建了一个Map-to-Sequence层。翻译层包括两种,一种基于字典的,一种不基于字典的。翻译层把RNN特征转换成结果标签。模型结构如下图。
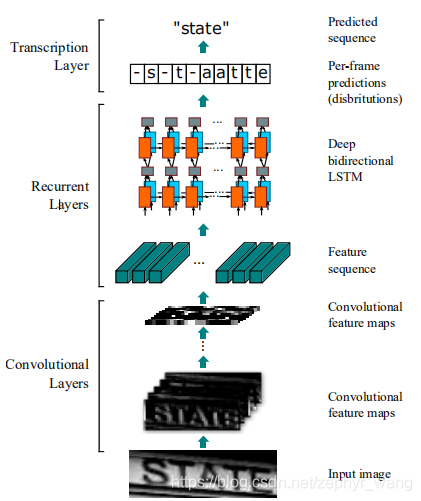

在第3、4层使用1*2的windows代替正方形的windows,这个微小的调整增加了特征的长度,因此产生更长的特征序列。
使用了batch normalization 技术。
CRNN的所有层使用权重共享连接,同时没有全连接层,所以参数较少,占用内存较小。
4.1.3.特征提取CNN
1.全连接层被去掉了。
2.所有图片需相同高度输入,该模型是100*32,来提升训练效率。
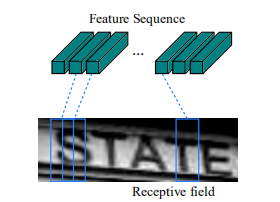
3.按1像素宽度的列读取图片特征。如下图,是一系列特征的拼接。
4.1.4.Transcription层,CTC
Transcription层是将lstm层的输出与label对应,采用的技术是CTC。
CTC,Connectionist Temporal Classification,用来解决输入序列和输出序列难以一一对应的问题。
对于一对输入输出(X,Y)来说,CTC的目标是将下式概率最大化
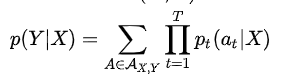
解释一下,对于RNN+CTC模型来说,RNN输出的就是Pt概率,t表示的是RNN里面的时间的概念。乘法表示一条路径的所有字符概率相乘,加法表示多条路径。因为上面说过CTC对齐输入输出是多对一的,例如he-l-lo-与hee-l-lo对应的都是“hello”,这就是输出的其中两条路径,要将所有的路径相加才是输出的条件概率.
基于字典的模式,其实是就是上面CTC的基础上,在获得结果时,又从字典查了一遍,来更加提高准确率,而没有字典的就只能取高概率的结果,少了从字典查这一步。
4.1.5.模型训练
模型输入(I,I),I代表输入的图片,I代表实际的文字结果。训练结果就是最小化下面的函数。
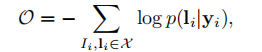
其中y是cnn和rnn输出的结果,上面的函数没有任何的人工处理,相当于是直接的对输入和输出进行计算,故是端到端的模型(end-to-end)。
使用的是随机梯度下降(SGD)进行训练的。
使用ADADELTA来自动调整学习率。
4.1.6.乐谱识别
因为训练样本较少,对模型的进行了修剪。删除了第4和第6层的卷积层,2层的双向LSTM变成了2层单向的LSTM.
该模型在乐谱识别上也取得了优秀的结果。


















 2万+
2万+




 到【灌水乐园】发言
到【灌水乐园】发言









