









 研究发现,无偏置神经网络(BF-CNN)在图像降噪任务中表现出更好的泛化性能,尤其是在训练噪声水平之外。通过去除网络中的加性偏置,BF-CNN能自适应于图像结构和噪声水平,形成局部线性滤波器,降低对噪声水平的过拟合。BF-CNN的降噪机制包括局部自适应滤波和自适应低维子空间投影,有效保留清晰图像信息。实验结果表明,即使在小范围噪声训练下,BF-CNN也能保持良好的去噪效果,且其均方误差与输入PSNR呈线性关系。
研究发现,无偏置神经网络(BF-CNN)在图像降噪任务中表现出更好的泛化性能,尤其是在训练噪声水平之外。通过去除网络中的加性偏置,BF-CNN能自适应于图像结构和噪声水平,形成局部线性滤波器,降低对噪声水平的过拟合。BF-CNN的降噪机制包括局部自适应滤波和自适应低维子空间投影,有效保留清晰图像信息。实验结果表明,即使在小范围噪声训练下,BF-CNN也能保持良好的去噪效果,且其均方误差与输入PSNR呈线性关系。
这是ICLR 2020的一篇文章,单位为纽约大学。其主要讨论了通过将网络结构中的所有加性参数去掉,得到无偏置网络(bias-free network)可以在不同的噪声水平下有更好的泛化性能,即使其只在一个非常小的的噪声水平上做训练。对于无偏置网络来说,每个局部位置都可以将网络权重看做是一个滤波器,其自适应于图像结构和噪声水平。
NETWORK BIAS IMPAIRS GENERALIZATION
假设噪声图像包含加性噪声:y=x+ny=x+ny=x+n,而且噪声nnn是独立同分布的高斯白噪声,方差为σ2\sigma^2σ2。
当使用神经网络进行降噪时,由于σ\sigmaσ未知(盲去噪),因而网络需要对噪声水平有一定的泛化性能,特别是当测试的噪声水平不包含在训练集中时。
使用ReLUs的前馈神经网络是分段仿射的(piecewise affine)。对于一个固定的噪声输入yyy,神经网络拟合的降噪函数f(⋅)f(\cdot)f(⋅)可以表示为:
f(y)=WLR(WL−1...R(W1y+b1)+...bL−1)+BL=Ayy+byf(y)=W_LR(W_{L-1}...R(W_1 y+b_1)+...b_{L-1})+B_L=A_y y+b_yf(y)=WLR(WL−1...R(W1y+b1)+...bL−1)+BL=Ayy+by
其中,WkW_kWk表示线性变换(卷积或全连接层,kkks是网络层数),bkb_kbk表示加性偏置,RRR表示固定的激活图样。
AyA_yAy是f(⋅)f(\cdot)f(⋅)相对于输入yyy的雅可比矩阵(Jacobian),byb_yby表示网络偏置(net bias)。他们都依赖于ReLU的激活图样,从而依赖于输入yyy。
下图展示了使用不同噪声水平范围的训练集得到的结果。CNN使用DnCNN结构。
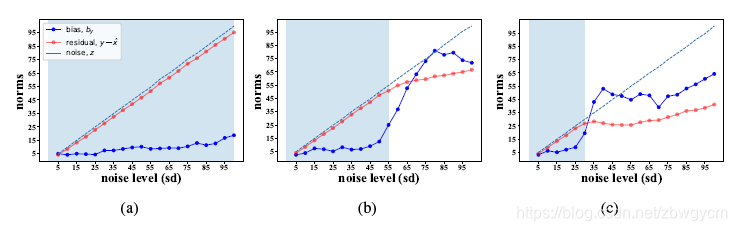
可以看到,当网络在整个噪声水平范围上做训练时,网络偏置整体都是比较小的,随着噪声增加略微有增长。这说明了线性项(WkW_kWk)在降噪中起到更大的作用。当网络在一个更小的噪声范围内做训练时,网络偏置会在噪声水平超出训练范围后突然增大。这说明此时网络已经出现过拟合了,因而对超出训练范围的噪声水平泛化性能下降。
PROPOSED METHODOLOGY: BIAS-FREE NETWORKS
通过上面的观察,可以通过去除加性偏置项来改善网络的过拟合,提升泛化性能。因而文章提出了无偏执CNN(bias-free CNN,BF-CNN),就是将网络中各个阶段的偏置项(包括BN层中的偏置项)全部去掉。而这会使得使用ReLU的前馈神经网络具有缩放不变性,即输入经过一个常数缩放等于网络输出经过相同常数的缩放。
引理 1. 令fBF:RN→RNf_{BF}:R^N \rightarrow R^NfBF:RN→RN是一个使用ReLU作为激活函数的前馈神经网络,且在任何层中都没有加性常数项。对于任意输入y∈Ry\in Ry∈R和任意非负常数α\alphaα,都有
fBF(αy)=αfBF(y)f_{BF}(\alpha y)=\alpha f_{BF}(y)fBF(αy)=αfBF(y)。
上述引理对于有并联或加性跳跃连接的网络同样适用,他们都是线性操作。
下图展示了BF-CNN和传统CNN的降噪性能的比较。两者使用了相同的网络结构(DnCNN)。可以看到BF-CNN在训练范围外有更好的泛化性能。
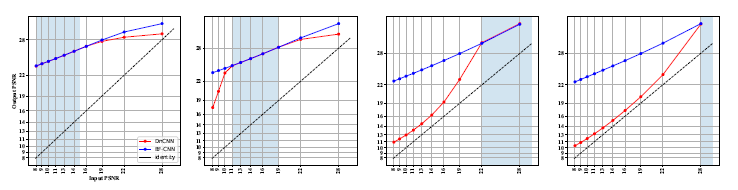
文章测试了包括DnCNN,Recurrent CNN,UNet,Simplified DenseNet四种网络结构。不同的网络结构都能得到相似的现象,原始有偏置的CNN都在训练范围内取得好的性能,但是在新的噪声水平上出现明显下降。而对应的BF-CNN都在不同的噪声范围中体现了好的泛化性能。
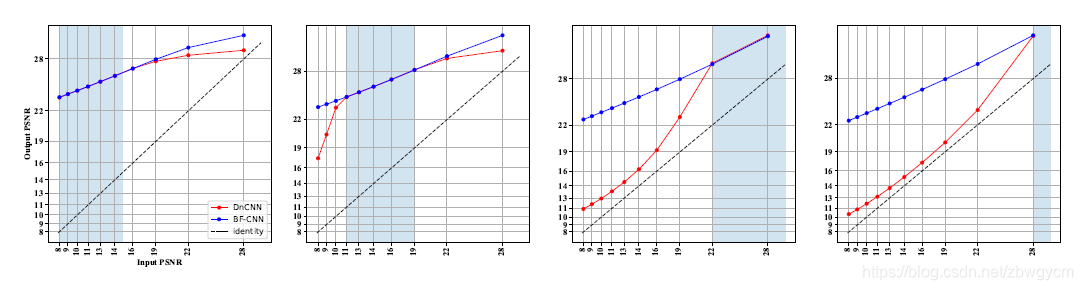
REVEALING THE DENOISING MECHANISMS LEARNED BY BF-CNNS
一个无偏置网络是局部线性的,可以表示为
fBF(y)=WLR(WL−1...R(W1y))=Ayyf_{BF}(y)=W_LR(W_{L-1}...R(W_1 y))=A_y yfBF(y)=WLR(WL−1...R(W1y))=Ayy
对于固定输入的雅可比矩阵AyA_yAy展示了去噪图的局部特性。
局部自适应滤波
输出图像的第iii个像素可以使用AyA_yAy第iii行(ay(i)a_y(i)ay(i))与输入图像的内积计算得到:
fBF(y)(i)=∑j=1NAy(i,j)y(j)=ay(i)Tyf_{BF}(y)(i)=\sum^N_{j=1}A_y(i,j)y(j)=a_y(i)^TyfBF(y)(i)=∑j=1NAy(i,j)y(j)=ay(i)Ty
向量ay(i)a_y(i)ay(i)可以解释为自适应滤波器,其通过对噪声像素进行加权平均得到去噪像素。
下图展示了一个BF-CNN中线性加权函数(向量ay(i)a_y(i)ay(i))的可视化结果。

可以看出这些权重是自适应于图像的局部特征,只对均质区域进行加权平均而避免模糊边缘。而且可以看到,随着噪声水平σ\sigmaσ增大,权重函数的空间延伸也在增大。不同像素位置的权重函数大不相同。
自适应低维子空间的投影
对一个给定的输入yyy,计算雅克比矩阵的SVD分解Ay=USVTA_y=USV^TAy=USVT,可得到
fBF(y)=Ayy=USVTy=∑i=1Nsi(ViTy)Uif_{BF}(y)=A_y y=USV^Ty=\sum^N_{i=1}s_i(V^T_iy)U_ifBF(y)=Ayy=USVTy=∑i=1Nsi(ViTy)Ui
输出是左奇异向量的线性组合。每个向量的权重由输入在对应右奇异向量的投影给出,并由对应的奇异值进行放缩。下图给出了对雅克比均值SVD的分析。
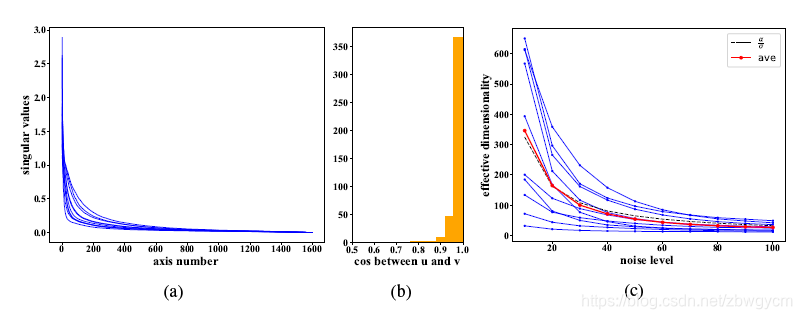
从图5(a)可以看到,大多数的奇异值都是非常接近于0,说明网络将输入图像的的大多数成分都抛弃了,只保留了一个非常低维的部分。从图5(b)可以看到对应于同一个不可忽略的奇异值(奇异值比较大)的左右奇异向量是近似相同的。这说明雅克比矩阵是近似对称的,可以将其解释为网络将噪声信号投影到了一个低维子空间,正如小波阈值降噪法一样。下图展示了左特征向量(UiU_iUi)的可视化结果,从左到右依次对应于不同的奇异值(奇异值递减)。从下图可以看出,对应于较大奇异值的奇异向量捕捉了输入图像的特征。而对应于接近于0的奇异值的奇异向量是非结构化的。

定义信号空间的有效维度(effective dimensionality)为,将方差为σ2\sigma^2σ2的N维高斯噪声向量做线性映射得到的方差经过噪声方差做归一化后的值,d:=En∥Ayn∥2/σ2=∑i=1Nsi2d:=E_n\|A_yn\|^2/\sigma^2=\sum^N_{i=1}s^2_id:=En∥Ayn∥2/σ2=∑i=1Nsi2。
当对保留的信号子空间进行测试时,发现清晰图像几乎完整地包含在内。对于输入y:=x+ny:=x+ny:=x+n,由维度ddd以内的奇异向量张成的子空间几乎完整包含了清晰图像xxx,这意味着将xxx投影于子空间可以保持大部分能量。
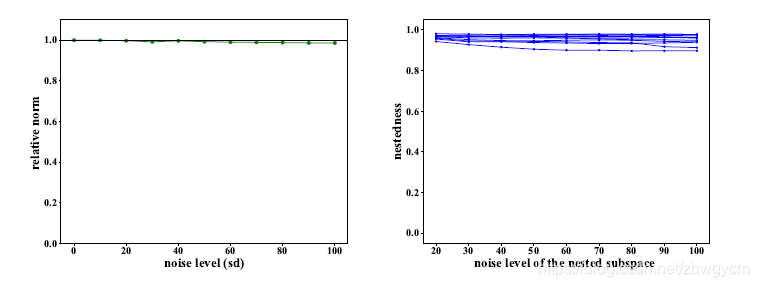
从下左图可以看到,投影于子空间所保留下的相对范数比例在噪声方差从10变到100时都接近于1。说明在每个特定的噪声水平下,信号子空间都几乎包含了清晰图像的信息。从下右图可以看到,不同噪声水平的信号子空间是嵌套的。更高的噪声水平的子空间坐标轴很大程度上位于最低噪声水平(σ=10\sigma=10σ=10)的子空间内。
同时,从图5(c)可以看出,对于任意给定的清晰图像,信号子空间的有效维度ddd随着噪声水平同步下降。在更低的噪声水平下,网络检测到更丰富的图像特征,构建一个更大的信号子空间来捕捉和保存这些图像特征。另外还可以看到平均来说,ddd近似正比于1σ\frac{1}{\sigma}σ1。
最后,信号子空间维度的这些特性,以及其包含清晰图像信息这个事实,解释了观察到的在不同信号水平下的降噪性能。假设d≈α/σd\approx \alpha/\sigmad≈α/σ,均方误差正比于σ\sigmaσ:
MSE=En∥Ay(x+n)−x∥2≈En∥Ayn∥2≈σ2d≈ασMSE=E_n\|A_y(x+n)-x\|^2\approx E_n\|A_yn\|^2\approx \sigma^2d \approx \alpha\sigmaMSE=En∥Ay(x+n)−x∥2≈En∥Ayn∥2≈σ2d≈ασ
这也说明了如图2所示,去噪图像的PSNR与输入PSNR呈线性关系,而且即使网络在一个较小噪声范围内进行训练,上述关系依然保持。
Conclusion
作者只在高斯噪声上测试了无偏置网络的有效性,对于该模型是否适用于真实噪声和其他图像复原任务还待验证。从目前作者的实验来看,对于图像去模糊任务中的不同大小模糊核,该模型是不充分的,无法复现去噪的结论。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









