







近年来,大语言模型(LLM)的爆发让“对话式BI”(ChatBI)成为行业热点。然而,许多企业发现,尽管技术Demo令人惊艳,实际落地却困难重重——用户提问率低、回答准确度不稳定、使用场景模糊。
衡石科技在ChatBI的实践中发现:技术能力只是基础,真正的产品价值取决于形态是否匹配用户场景。本文将深入探讨:
为什么ChatBI的形态不能单纯由技术驱动?
衡石如何通过场景适配设计提升ChatBI的可用性?
技术实现上如何支撑多形态灵活部署?
一、技术优先的ChatBI为何容易失败?
1. 孤立对话框模式的局限性
许多ChatBI产品模仿ChatGPT,提供独立搜索框界面,但企业用户面临:
-
缺乏上下文:用户需要手动输入完整业务背景(如“请分析2024年Q1华东区销售额”),而实际场景中需求往往产生于具体看板或业务流程中。
-
使用门槛高:非技术人员不熟悉数据术语,难以构建有效提问。
技术视角:纯LLM方案依赖提示词工程(Prompt Engineering),但企业查询需要结合数据模型、权限等上下文。
2. 通用大模型与垂直场景的鸿沟
-
数据口径问题:LLM可能混淆“销售额”(财务口径)与“GMV”(运营口径)。
-
业务逻辑缺失:例如“高价值客户”需关联企业自定义的RFM模型。
衡石方案:通过智能数据模型(IDM)将自然语言映射到结构化查询,而非依赖LLM自由生成。
二、衡石ChatBI的场景适配设计
1. 三类核心场景与形态匹配
| 场景 | 用户需求 | 传统BI方案 | 衡石ChatBI形态 |
|---|---|---|---|
| 监控业务进展 | 快速获取标准化指标 | 固定报表/看板 | 嵌入式Dashboard助手 |
| 业务决策支持 | 实时分析辅助操作 | 嵌入式图表 | 业务系统内AI分析按钮 |
| 团队协同沟通 | 即时数据问答与分享 | Excel/人工查询 | IM工具智能机器人 |
技术实现差异
-
Dashboard助手:需与可视化组件联动(如点击图表后提问“为什么此指标异常”)。
-
IM机器人:需支持短文本意图识别(如“上季度营收”需自动关联企业财年定义)。
2. 场景化适配的技术关键点
(1) 上下文感知架构
-
业务系统嵌入:通过微前端(Micro Frontend)技术注入ChatBI模块,共享当前页面数据上下文(如CRM中的客户ID)。
-
IM集成:解析聊天记录中的实体(如“@财务 2024预算”),自动过滤敏感数据。
(2) 混合式查询引擎
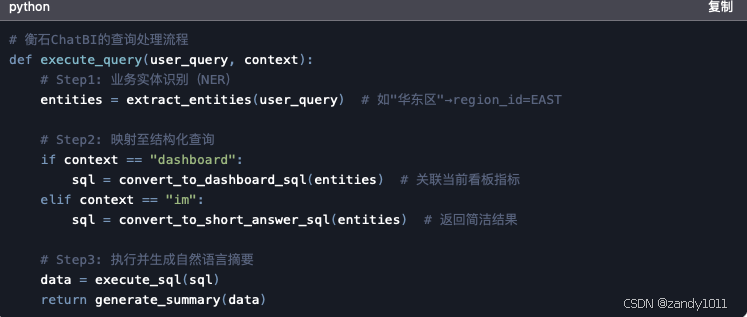
(3) 权限与数据治理
动态数据脱敏:根据用户角色限制AI回答范围(如销售仅能查看所属区域数据)。
审计日志:记录所有AI生成查询,满足合规要求。
三、技术架构如何支撑场景灵活性?
1. 插件化部署模型
衡石ChatBI采用模块化设计,支持快速适配不同场景:
业务系统集成:提供轻量级JS SDK,支持一键嵌入。
IM机器人:通过Webhook对接企微/飞书API。
2. 场景优化的模型微调
看板场景:训练模型优先识别指标术语(如“DAU”“转化率”)。
IM场景:优化短文本理解(如“营收怎么样?”→“请确认需要2024年Q1的全球营收吗?”)。
3. 性能与成本平衡
冷热查询分离:高频问题(如“今日销售额”)缓存结果,复杂分析走实时计算。
LLM分级调用:简单查询用轻量模型(如FastChat),深度分析调用GPT-4。
技术为场景服务,才是ChatBI的破局点
衡石ChatBI的核心洞察在于:企业不需要“全能AI”,而是需要“恰到好处的智能”。通过场景化形态设计、混合式技术架构、严格的数据治理,衡石让ChatBI从技术噱头转化为真实的生产力工具。
未来方向:随着AI Agent技术的发展,ChatBI或将进一步实现“自主分析-行动建议-业务执行”的闭环,但场景适配性仍将是技术演进的北极星指标。

















 1993
1993

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









