




今天先把昨天欠下的热力图和子图的任务完成一下
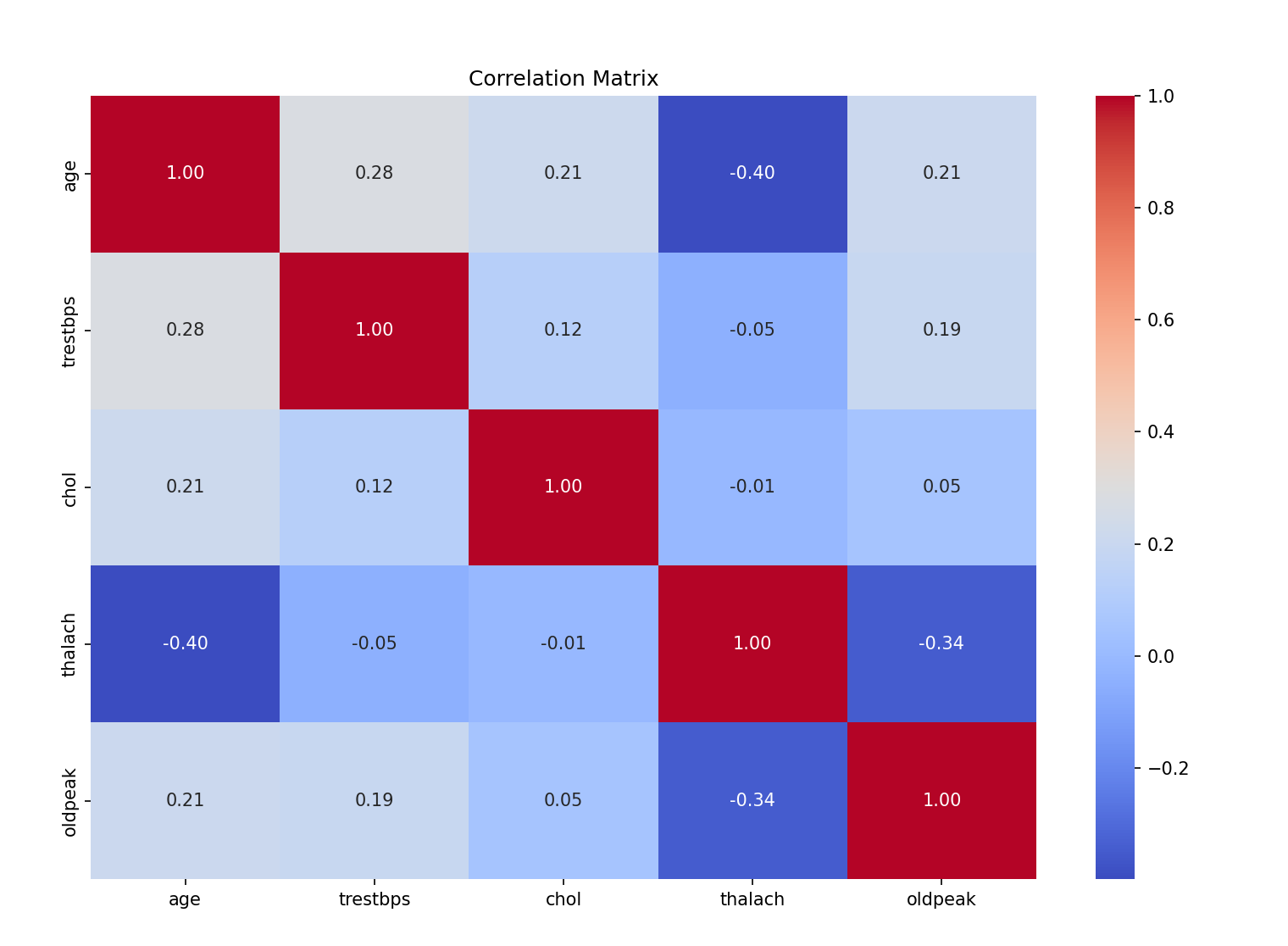
心脏病的特征相关性热力图
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
data = pd.read_csv('heart.csv')
print(data.info())
# 将object类型转化为数字
# 先了解每类出现的次数去确定一个特征分布的情况
# 提取连续特征,计算相关系数,绘图
continue_feature = []
for feature in data.columns:
unique_count = data[feature].nunique()
if unique_count > 5:
continue_feature.append(feature)
# 计算相关系数
corr_matrix = data[continue_feature].corr()
# 绘制相关系数矩阵的热力图
plt.figure(figsize=(12, 8))
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', fmt=".2f")
plt.title("Correlation Matrix")
plt.show()
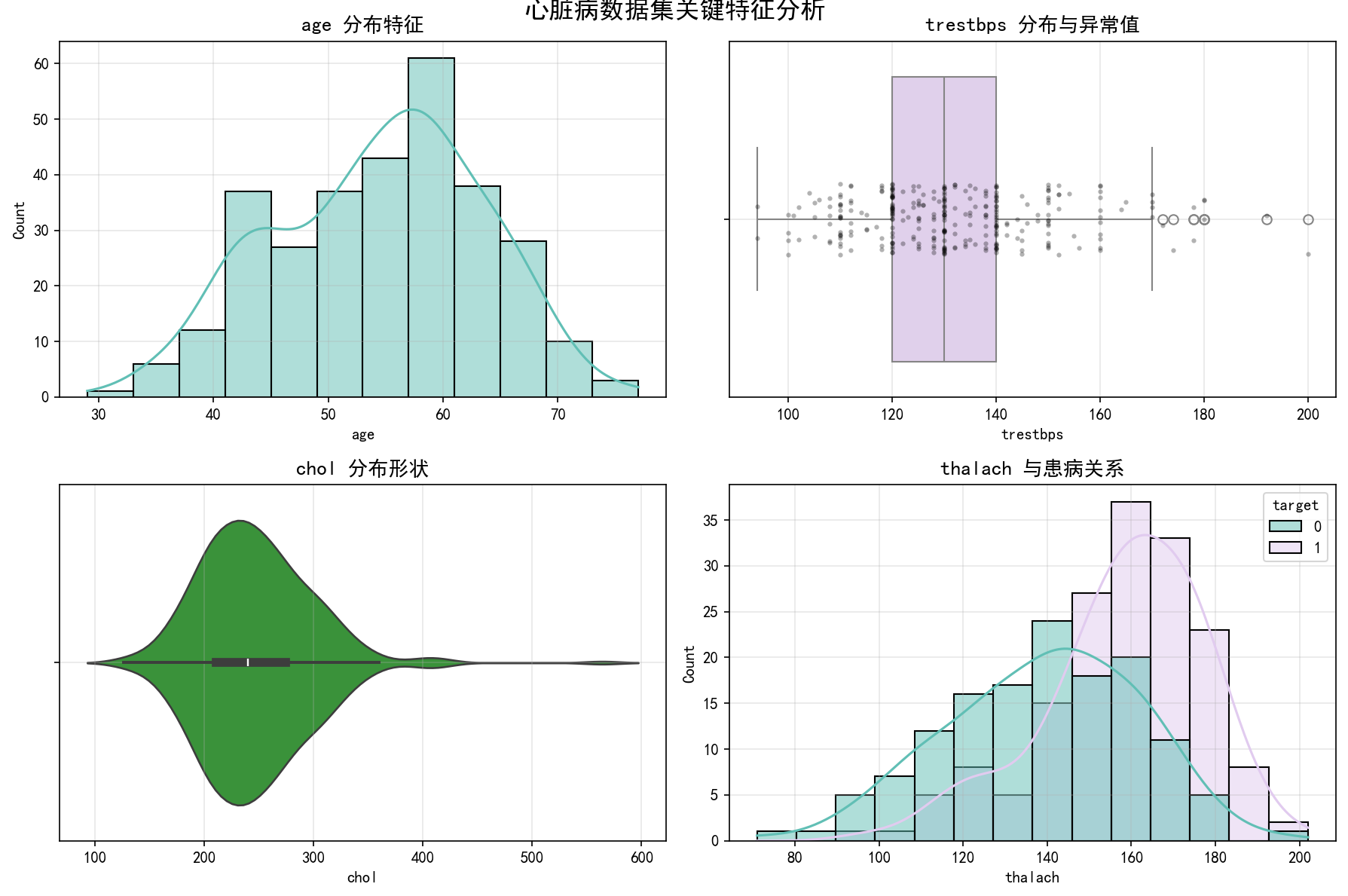
子图
features = ['age','trestbps','chol','thalach']
plt.rcParams.update({'font.family':'SimHei','axes.unicode_minus':False})
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
axes = axes.flatten()
# 展平为一维数组便于循环
for i, feature in enumerate(features):
# eumerate 函数返回索引和元素
ax = axes[i]
if i == 0:
sns.histplot(data[feature].dropna(),kde=True,ax=ax,color='#61BFB5')
ax.set_title(f'{feature} 分布特征',fontsize=13,fontweight='bold')
elif i ==1:
sns.boxplot(data=data,x=feature,ax=ax,color='#E1CBEF')
sns.stripplot(data=data,x=feature,ax=ax,color='black',alpha=0.3,size=3)
ax.set_title(f'{feature} 分布与异常值',fontsize=13,fontweight="bold")
elif i ==2:
sns.violinplot(data=data,x=feature,ax=ax,color='#2ca02c')
ax.set_title(f'{feature} 分布形状',fontsize=13,fontweight='bold')
else:
sns.histplot(data=data,x=feature,hue='target',kde=True,ax=ax,palette=['#61BFB5','#E1CBEF'])
ax.set_title(f'{feature} 与患病关系',fontsize=13,fontweight='bold')
ax.grid(alpha=0.3)
plt.tight_layout()
plt.suptitle('心脏病数据集关键特征分析',fontsize=16,y=1,fontweight='bold')
plt.show()
今天的内容:
- 数据集的划分
- 机器学习模型建模的三行代码
- 机器学习模型分类问题的评估
好好理解下这几个评估指标。
一、先读取数据,数据概况分析,根据特征选择合适的预处理方式
import pandas as pd #用于数据处理和分析,可处理表格数据。
import numpy as np #用于数值计算,提供了高效的数组操作。
import matplotlib.pyplot as plt #用于绘制各种类型的图表
import seaborn as sns #基于matplotlib的高级绘图库,能绘制更美观的统计图形。
# 设置中文字体(解决中文显示问题)
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows系统常用黑体字体
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
data = pd.read_csv('heart.csv') #读取数据
print("数据基本信息:")
print(data.info())
print("\n数据前5行预览:")
print(data.head())数据基本信息:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 303 entries, 0 to 302
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 age 303 non-null int64
1 sex 303 non-null int64
2 cp 303 non-null int64
3 trestbps 303 non-null int64
4 chol 303 non-null int64
5 fbs 303 non-null int64
6 restecg 303 non-null int64
7 thalach 303 non-null int64
8 exang 303 non-null int64
9 oldpeak 303 non-null float64
10 slope 303 non-null int64
11 ca 303 non-null int64
12 thal 303 non-null int64
13 target 303 non-null int64
dtypes: float64(1), int64(13)
memory usage: 33.3 KB
None
数据前5行预览:
age sex cp trestbps chol fbs ... exang oldpeak slope ca thal target
0 63 1 3 145 233 1 ... 0 2.3 0 0 1 1
1 37 1 2 130 250 0 ... 0 3.5 0 0 2 1
2 41 0 1 130 204 0 ... 0 1.4 2 0 2 1
3 56 1 1 120 236 0 ... 0 0.8 2 0 2 1
4 57 0 0 120 354 0 ... 1 0.6 2 0 2 1
二、进行特征分类,处理异常值,对离散特征独热编码,连续特征进行标准化
discrete_feature=[]
continue_feature=[]
# 定义标签列名称
TARGET_COLUMN = 'target'
for feature in data.columns:
# 跳过标签列
if feature == TARGET_COLUMN:
continue
if data[feature].dtype =='object':
discrete_feature.append(feature)
else:
unique_count = data[feature].nunique()
if unique_count<=5:
discrete_feature.append(feature)
else:
continue_feature.append(feature)
print("离散特征:", discrete_feature)
print("连续特征:", continue_feature)
# 新增:单独提取标签列
target = data[TARGET_COLUMN]
print("标签列名称:", TARGET_COLUMN)
print("标签分布:", target.value_counts())
# 数值特征异常值处理
# 新增:异常值检测与处理(IQR方法)
# 1. 可视化异常值(箱线图)
plt.figure(figsize=(15, 5))
for i, feature in enumerate(continue_feature):
plt.subplot(1, len(continue_feature), i+1)
sns.boxplot(x=data[feature])
plt.title(f'{feature} 异常值检测')
plt.tight_layout()
plt.show()
# 2. IQR方法处理异常值
# 创建副本避免修改原数据
data_clean = data.copy()
for feature in continue_feature:
Q1 = data_clean[feature].quantile(0.25)
Q3 = data_clean[feature].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
# 截断异常值(医学数据推荐,避免数据丢失)
data_clean[feature] = data_clean[feature].clip(lower_bound, upper_bound)
# 统计异常值数量
outliers = data[(data[feature] < lower_bound) | (data[feature] > upper_bound)]
print(f'{feature}: 检测到{len(outliers)}个异常值,已截断处理')
# 分类特征编码(独热编码)
data_encoded = pd.get_dummies(data_clean, columns=discrete_feature, drop_first=True)
print("\n独热编码后的特征数量:", data_encoded.shape[1])
data_encoded = data_encoded.astype(int)
# 数值特征标准化
scaler = StandardScaler()
data_encoded[continue_feature] = scaler.fit_transform(data_encoded[continue_feature])
# 查看处理后的数据
print("\n预处理后的数据预览:")
print(data_encoded.head())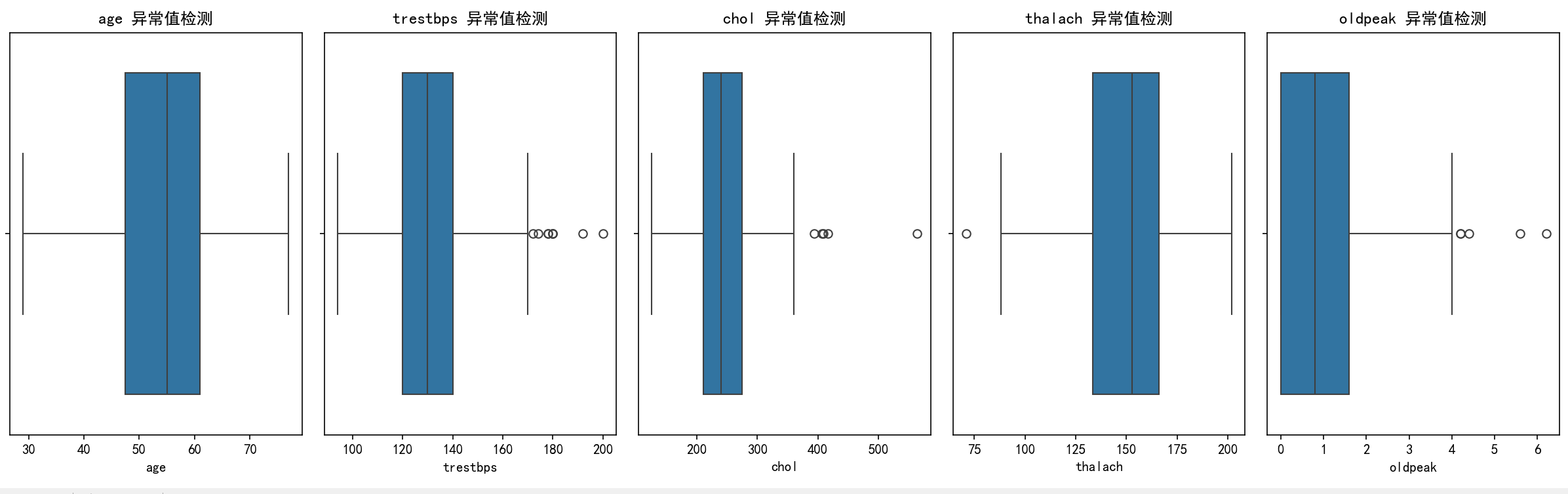
[5 rows x 14 columns]
离散特征: ['sex', 'cp', 'fbs', 'restecg', 'exang', 'slope', 'ca', 'thal']
连续特征: ['age', 'trestbps', 'chol', 'thalach', 'oldpeak']
标签列名称: target
标签分布: target
1 165
0 138
Name: count, dtype: int64
age: 检测到0个异常值,已截断处理
trestbps: 检测到9个异常值,已截断处理
chol: 检测到5个异常值,已截断处理
thalach: 检测到1个异常值,已截断处理
oldpeak: 检测到5个异常值,已截断处理
独热编码后的特征数量: 23
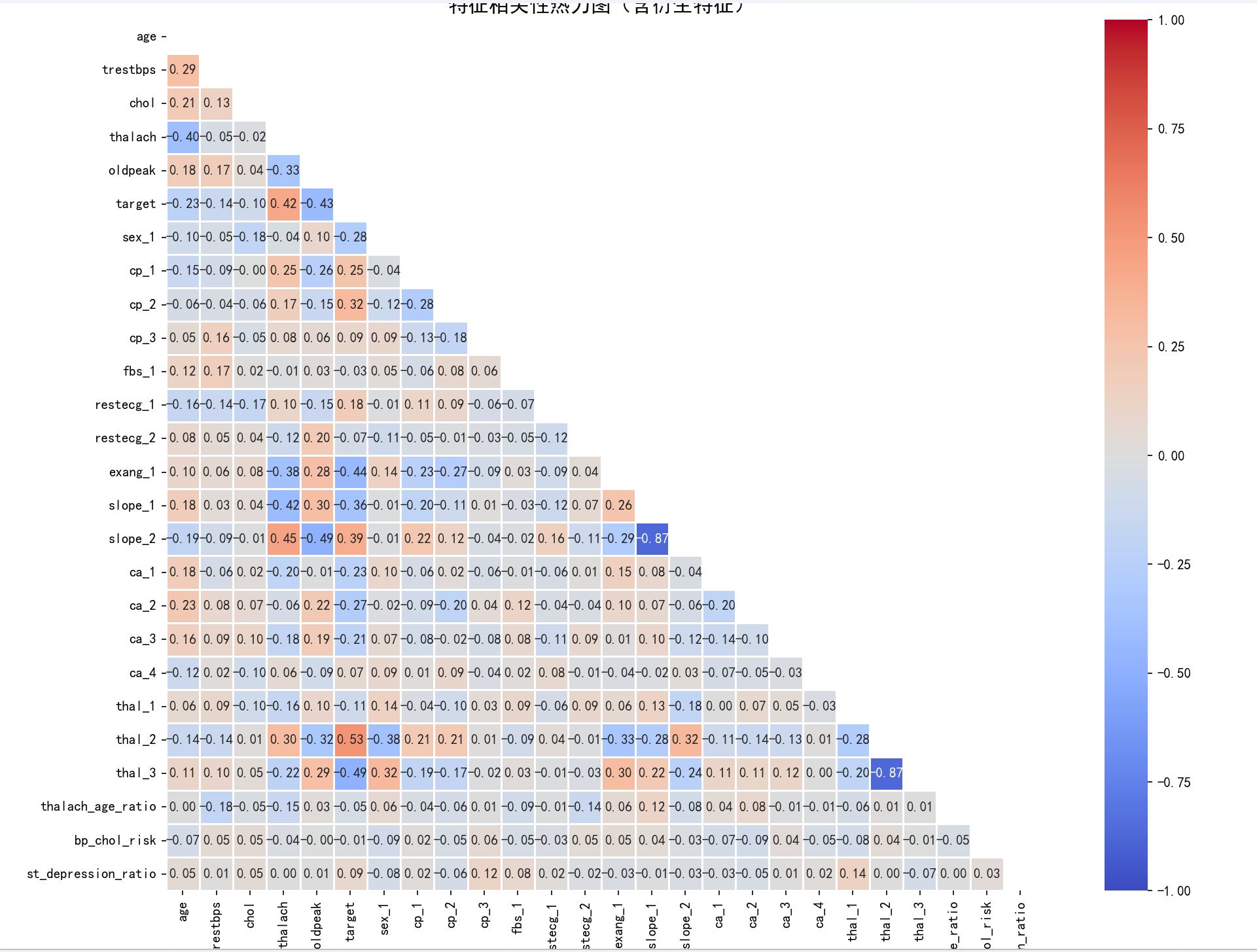
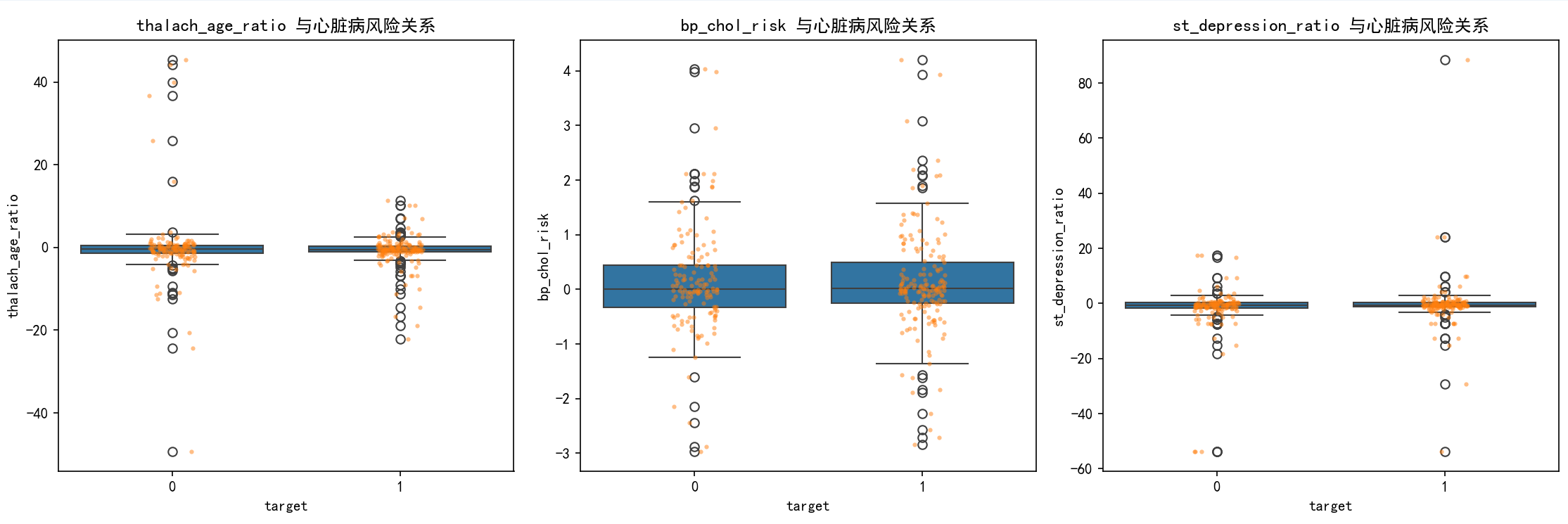
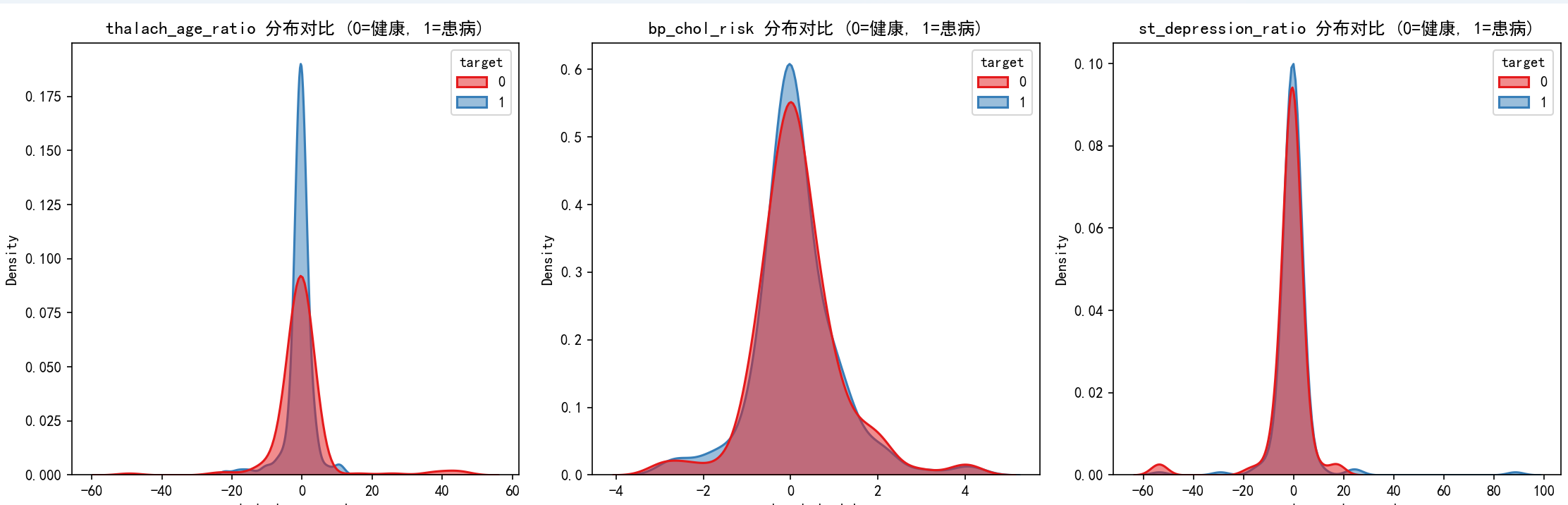
新增衍生特征后连续特征集: ['age', 'trestbps', 'chol', 'thalach', 'oldpeak', 'thalach_age_ratio', 'bp_chol_risk', 'st_depression_ratio']
预处理后的数据预览:
age trestbps chol thalach ... thal_3 thalach_age_ratio bp_chol_risk st_depression_ratio
0 0.952197 0.828728 -0.255515 0.013648 ... 0 0.014333 -0.211752 88.447268
1 -1.915313 -0.077351 0.102818 1.641343 ... 0 -0.856958 -0.007953 1.326506
2 -1.474158 -0.077351 -0.866788 0.981467 ... 0 -0.665781 0.067047 0.241410
3 0.180175 -0.681403 -0.192279 1.245417 ... 0 6.912271 0.131020 -0.588736
4 0.290464 -0.681403 2.294970 0.585541 ... 0 2.015883 -1.563799 -1.252213
[5 rows x 26 columns]来不及了,今天就先到这吧,开始的晚了,明天一定早早开始啊啊啊啊啊啊啊啊啊。先预处理好

















 955
955

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









