




近日, CVPR 2025(IEEE/CVF Conferenceon on Computer Vision and Pattern Recognition)论文录用结果揭晓,本次大会共2878篇被录用,录用率为22.1%。CVPR是计算机视觉领域的顶级国际会议,CCF A类会议,每年举办一次。CVPR 2025将于6月11日-15日,在美国田纳西州纳什维尔音乐城市中心召开。
今年,腾讯优图实验室共有22篇论文入选,内容涵盖深度伪造检测、自回归视觉生成、多模态大语言模型等研究方向,展现了优图在人工智能领域的技术能力与创新突破。
以下为入选论文概览:
基于视频混合增强和时空适配器的深度伪造视频检测方法
Generalizing Deepfake Video Detection with Plug-and-Play: Video-Level Blending and Spatiotemporal Adapter Tuning
Zhiyuan Yan (北大), Yandan Zhao, Shen Chen, Mingyi Guo (北大), Xinghe Fu, Taiping Yao, Shouhong Ding, Li Yuan (北大)
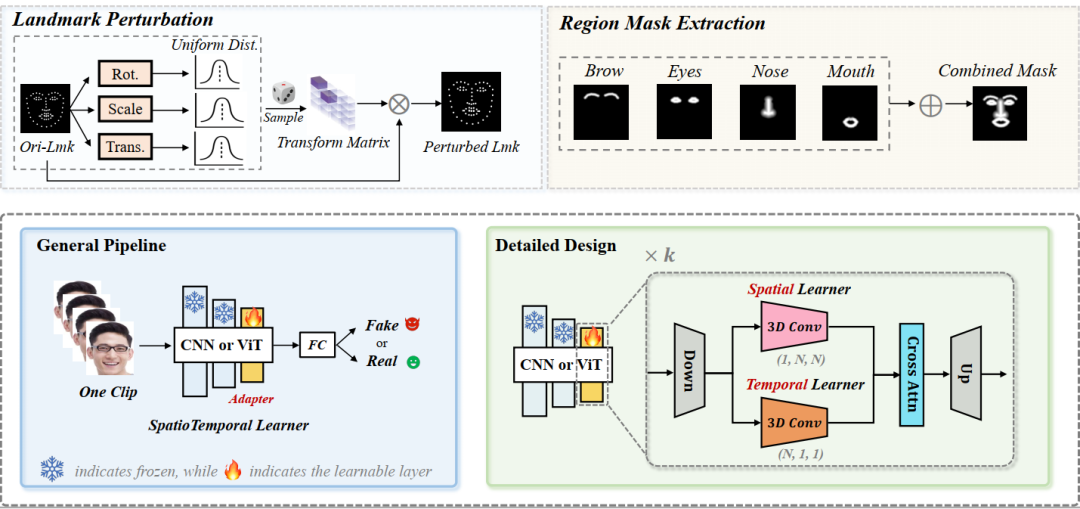
当前深度伪造视频检测的发展面临三大关键挑战:(1)时间特征可能复杂且多样:如何识别通用的时间伪影以增强模型的泛化能力?(2)时空模型往往过度依赖一种类型的伪影而忽视另一种:如何确保从两者中平衡学习?(3)视频处理自然需要大量资源:如何在保证准确性的前提下提升效率?本文尝试同时解决这三个挑战。首先,受图像伪造检测中使用图像级混合数据的显著泛化性启发,我们探讨了视频级混合在视频检测中的有效性。随后,我们进行了深入分析,发现了一种先前未被充分研究的时间伪造伪影:面部特征漂移(FFD),这种伪影在不同伪造视频中普遍存在。为了重现FFD,我们提出了一种新颖的视频级混合数据(VB),通过逐帧混合原始图像及其扰动版本,作为挖掘更通用伪影的困难负样本。其次,我们精心设计了一个轻量级的时空适配器(StA),使预训练的图像模型能够高效地同时捕捉空间和时间特征。StA采用双流3D卷积设计,具有不同大小的卷积核,使其能够分别处理空间和时间特征。大量实验验证了所提方法的有效性,并表明我们的方法能够很好地泛化到之前未见过的伪造视频,即使是针对最新一代的伪造方法。
论文链接:
https://arxiv.org/pdf/2408.17065
TIMotion:高效双人动作生成的时序与交互框架
TIMotion: Temporal and Interactive Framework for Efficient Human-Human Motion Generation
Yabiao Wang, Shuo Wang, Jiangning Zhang, Ke Fan(上交), Jiafu Wu, Zhucun Xue(浙大), Yong Liu(浙大)
双人动作生成对于理解人类的行为至关重要。当前的方法主要分为两大类:基于单人的方法和基于独立建模的方法。为了深入研究这一领域,我们将整个生成过程抽象为一个通用框架MetaMotion,它包括两个阶段:时序建模和交互混合。在时序建模中,基于单人的方法直接将两个人连接成一个人,而基于独立建模的方法则跳过了交互序列的建模。然而,上述不充分的建模导致了次优的性能和冗余的模型参数。在本文中,我们提出了TIMotion(时序与交互建模),这是一个高效且有效的人-人动作生成框架。具体来说,我们首先提出因果交互注入(CII),利用时序和因果属性将两个独立序列建模为一个因果序列。然后,我们提出角色演变扫描(RES),以适应交互过程中主动和被动角色的变化。最后,为了生成更平滑、更合理的动作,我们设计了局部模式放大(LPR)来捕捉短期动作模式。在InterHuman和Inter-X的实验表明,相比其它方法,我们的方法取得了更好的性能。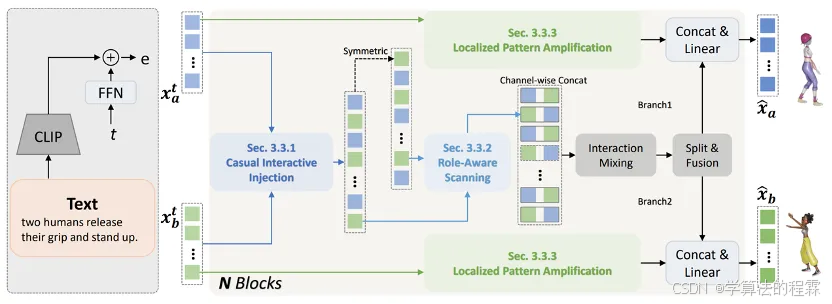
论文链接:https://aigc-explorer.github.io/TIMotion-page/
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 584
584

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









