



openmp
一、OpenMP基本概念
OpenMP是一种用于共享内存并行系统的多线程程序设计方案,支持的编程语言包括C、C++和Fortran。OpenMP提供了对并行算法的高层抽象描述,特别适合在多核CPU机器上的并行程序设计。编译器根据程序中添加的pragma指令,自动将程序并行处理,使用OpenMP降低了并行编程的难度和复杂度。当编译器不支持OpenMP时,程序会退化成普通(串行)程序。程序中已有的OpenMP指令不会影响程序的正常编译运行。在VS中启用OpenMP很简单,很多主流的编译环境都内置了OpenMP。(具体介绍可以参考OpenMP总结)
二、OpenMP执行模式
OpenMP采用fork-join的执行模式。开始的时候只存在一个主线程,当需要进行并行计算的时候,派生出若干个分支线程来执行并行任务。当并行代码执行完成之后,分支线程会合,并把控制流程交给单独的主线程。
一个典型的fork-join执行模型的示意图如下:

OpenMP编程模型以线程为基础,通过编译制导指令制导并行化,有三种编程要素可以实现并行化控制,他们分别是编译制导、API函数集和环境变量。
三、编译制导
编译制导指令以#pragma omp 开始,后边跟具体的功能指令,格式如:#pragma omp 指令[子句[,子句] …]。
3.1 常用的功能指令
| 功能指令 | 解析 |
| parallel | 用在一个结构块之前,表示这段代码将被多个线程并行执行 |
| for | 用于for循环语句之前,表示将循环计算任务分配到多个线程中并行执行,以实现任务分担,必须由编程人员自己保证每次循环之间无数据相关性 |
| sections | 用在可被并行执行的代码段之前,用于实现多个结构块语句的任务分担,可并行执行的代码段各自用section指令标出(注意区分sections和section) |
| parallel sections | parallel和sections两个语句的结合,类似于parallel for |
| single | 用在并行域内,表示一段只被单个线程执行的代码 |
| critical | 用在一段代码临界区之前,保证每次只有一个OpenMP线程进入 |
| flush | 保证各个OpenMP线程的数据影像的一致性 |
| barrier | 用于并行域内代码的线程同步,线程执行到barrier时要停下等待,直到所有线程都执行到barrier时才继续往下执行 |
| atomic | 用于指定一个数据操作需要原子性地完成 |
| master | 用于指定一段代码由主线程执行 |
| threadprivate | 用于指定一个或多个变量是线程专用,后面会解释线程专有和私有的区别 |
3.2 相应的OpenMP子句
| OpenMP子句 | 解析 |
| private | 指定一个或多个变量在每个线程中都有它自己的私有副本 |
| firstprivate | 指定一个或多个变量在每个线程都有它自己的私有副本,并且私有变量要在进入并行域或任务分担域时,继承主线程中的同名变量的值作为初值 |
| lastprivate | 是用来指定将线程中的一个或多个私有变量的值在并行处理结束后复制到主线程中的同名变量中,负责拷贝的线程是for或sections任务分担中的最后一个线程 |
| reduction | 用来指定一个或多个变量是私有的,并且在并行处理结束后这些变量要执行指定的归约运算,并将结果返回给主线程同名变量 |
| nowait | 指出并发线程可以忽略其他制导指令暗含的路障同步 |
| num_threads | 指定并行域内的线程的数目 |
| schedule | 指定for任务分担中的任务分配调度类型 |
| shared | 指定一个或多个变量为多个线程间的共享变量 |
| ordered | 用来指定for任务分担域内指定代码段需要按照串行循环次序执行 |
| copyprivate | 配合single指令,将指定线程的专有变量广播到并行域内其他线程的同名变量中 |
| copyinn | 用来指定一个threadprivate类型的变量需要用主线程同名变量进行初始化 |
| default | 用来指定并行域内的变量的使用方式,缺省是shared |
四、API函数
除上述编译制导指令之外,OpenMP还提供了一组API函数用于控制并发线程的某些行为,下面是一些常用的OpenMP API函数以及说明
函数名 作用
omp_in_parallel 判断当前是否在并行域中
omp_get_thread_num 返回线程号
omp_set_num_thread 设置后续并行域中的线程格式
omp_get_num_threads 返回当前并行域中的线程数
omp_get_max_threads 返回并行域可用的最大线程数目
omp_get_num_prpces 返回系统中处理器的数目
omp_get_dynamic 判断是否支持动态改变线程数目
omp_set_dynamic 启用或关闭线程数目的动态改变
omp_get_nested 判断系统是否支持并行嵌套
omp_set_nested 启用或关闭并行嵌套
五、环境变量
OpenMP中定义一些环境变量,可以通过这些环境变量控制OpenMP程序的行为,常用环境变量:
环境变量 解析
OMP_SCHEDULE 用于for循环并行化后的调度,它的值就是循环调度的类型
OMP_NUM_THREADS 用于设置并行域中的线程数
OMP_DYNAMIC 通过设定变量值,来确定是否允许动态设定并行域内的线程数
OMP_NESTED 指出是否可以并行嵌套
六、简单示例
示例中要知道的是 用到OpenMP时c程序开头都要#include"omp.h"
还有 以下c命令都在用g++命令编译
linux centos要用g++命令 先sudo yum install gcc-c++ 下载g++
6.0 提一下编译是什么 有什么用 g++/gcc命令编译
------写c++都知道,写完程序要编译才能形成可执行文件
如编译:g++ -fopenmp /home/hadoop/test.cpp -o test
实际上,执行g++ -o这个命令,是进行了非常多的步骤的,包括预处理、编译、汇编、链接
.cpp -->.i --> .s -->最终代码

预处理
预处理过程主要是处理那些以#开头的预编译指令,包括#include或者#define
可以执行g++ -E生成预处理后的文件,后缀为-i
g++ -E helloworld.cpp -o helloworld.i
查看生成的-i就可以知道将头文件等进行了预编译展开
主要过程如下:
- 将所有的#define删除,并展开所有的宏定义
- 处理所有条件预编译指令,包括#if、#ifdef、#else等
- 处理#include预编译指令,将被包含的文件插入到预编译指令的位置(递归进行)
- 过滤注释
- 添加行号和文件名标识
- 保留所有的#pragma指令
故如果想查看对应的宏编译是否正确展开时,可以查看预编译后的文件

编译与汇编
编译的过程是进行词法分析、语法分析、语义分析以及优化后产生相应的汇编代码文件。
g++ -S helloworld.i -o helloworld.s

整个编译过程,就是将高级语言翻译为机器语言的过程:通常将其分为6步,包括扫描、词法分析、语义分析、源代码优化、代码生成、目标代码优化。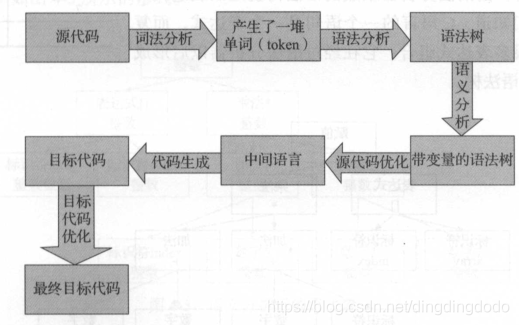
编译完成后生成了汇编代码,然后编译器将汇编代码转化为机器码,即产生二进制文件
链接
链接的主要任务是将编译好的各个模块进行一个组合,使得各个模块之间能够进行正确衔接。链接的过程主要是:地址和空间的重分配、符号决议、重定位等步骤。
链接分为静态链接和动态链接:
静态链接:对函数库的链接是放在编译时完成的,所有相关的目标文件与牵涉到的函数库被链接合成到一个可执行文件,故函数执行时与库函数再无瓜葛,所有需要的函数都复制到了相关的位置。也就是说,静态链接将所有用到的函数全部链接到exe文件中
动态链接:把对库函数的链接载入推迟到程序运行时期。在生成可执行文件时不将所有程序用到的函数链接到一个文件,因为有许多函数在操作系统带的dll文件中,当程序运行时直接从操作系统中找。某个程序在运行中要调用某个动态链接库函数的时候,操作系统首先会查看所有正在运行的程序,看在内存里是否已有此库函数的拷贝了。如果有,则让其共享那一个拷贝;只有没有才链接载入。
相比之下,静态链接库和动态链接库的特点:
动态链接库更有利于进程间的资源共享
动态链接库让程序的升级变得简单。静态库的升级必须重新编译,而动态库的话只要提供给程序的接口没变,则直接用新生成的动态库替代静态库就行
动态链接库更加节省内存
由于静态库在编译时就将库函数装载到程序中了,动态库是运行时装载,因此用静态库程序运行时速度可能快一些
原文链接:https://blog.youkuaiyun.com/dingdingdodo/article/details/107747509
6.1 parallel使用
parallel制导指令用来创建并行域,后边要跟一个大括号将要并行执行的代码放在一起
parallel 用于结构块之前,表明这个代码块 将有多个线程执行
test_para.cpp
#include<iostream>
#include"omp.h"
using namespace std;
int main()
{
#pragma omp parallel
{
cout << "Test" << endl;
}
return 0;
}
编译:g++ -fopenmp /home/hadoop/test.cpp -o test
运行:./op_test
结果:打印了3个Test(我用了linux centos虚拟机 设置了处理器为3,即3核,所以打印3个,但不知道为什么没列成一列 无伤大雅)
6.2 paraller for使用
使用parallel制导指令只是产生了并行域,让多个线程分别执行相同的任务,并没有实际的使用价值。parallel for用于生成一个并行域,并将计算任务在多个线程之间分配,从而加快计算运行的速度。可以让系统默认分配线程个数,也可以使用num_threads子句指定线程个数。
test_parafor.c
#include<stdio.h>
#include <stdlib.h>
#include<omp.h>
int main(int argc,char** argv)
{
#pragma omp parallel for num_threads(6)
for (int i = 0; i < 12; i++) //这里我的报错让把int i;这一声明提到循环外了
{
printf("OpenMP Test, 线程编号为: %d\n", omp_get_thread_num());
}
return 0;
}
编译:gcc -fopenmp test_parafor.c -o test_parafor
运行:./test_parafor
结果:如下图
上边程序指定了6个线程,迭代量为12,从输出可以看到每个线程都分到了12/6=2次的迭代量。
6.3 OpenMP效率提升以及不同线程数效率对比
diff_threads.c
#include <stdlib.h>
#include <stdio.h>
#include "omp.h"
void test()
{
for (int i = 0; i < 80000; i++)
{
//do something
}
}
int main(int argc, char **argv)
{
float startTime = omp_get_wtime();
//指定2个线程
#pragma omp parallel for num_threads(2)
for (int i = 0; i < 80000; i++)
{
test();
}
float endTime = omp_get_wtime();
printf("指定 2 个线程,执行时间: %f\n", endTime - startTime);
startTime = endTime;
//指定4个线程
#pragma omp parallel for num_threads(4)
for (int i = 0; i < 80000; i++)
{
test();
}
endTime = omp_get_wtime();
printf("指定 4 个线程,执行时间: %f\n", endTime - startTime);
startTime = endTime;
//指定8个线程
#pragma omp parallel for num_threads(8)
for (int i = 0; i < 80000; i++)
{
test();
}
endTime = omp_get_wtime();
printf("指定 8 个线程,执行时间: %f\n", endTime - startTime);
startTime = endTime;
//指定12个线程
#pragma omp parallel for num_threads(12)
for (int i = 0; i < 80000; i++)
{
test();
}
endTime = omp_get_wtime();
printf("指定 12 个线程,执行时间: %f\n", endTime - startTime);
startTime = endTime;
//不使用OpenMP
for (int i = 0; i < 80000; i++)
{
test();
}
endTime = omp_get_wtime();
printf("不使用OpenMP多线程,执行时间: %f\n", endTime - startTime);
startTime = endTime;
return 0;
}
编译:gcc -fopenmp diff_threads.c -o diff_threads
运行:./diff_threads
结果:如下图

可见,使用OpenMP优化后的程序执行时间是原来的1/4左右,并且并不是线程数使用越多效率越高,一般线程数达到4~8个的时候,不能简单通过提高线程数来进一步提高效率。
6.4 API使用
API.c
#include <omp.h>
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char *argv[])
{
printf("ID: %d, Max threads: %d, Num threads: %d \n", omp_get_thread_num(), omp_get_max_threads(), omp_get_num_threads());
omp_set_num_threads(5);
printf("ID: %d, Max threads: %d, Num threads: %d \n", omp_get_thread_num(), omp_get_max_threads(), omp_get_num_threads());
#pragma omp parallel num_threads(5)
{
// omp_set_num_threads(6); // Do not call it in parallel region
printf("ID: %d, Max threads: %d, Num threads: %d \n", omp_get_thread_num(), omp_get_max_threads(), omp_get_num_threads());
}
printf("ID: %d, Max threads: %d, Num threads: %d \n", omp_get_thread_num(), omp_get_max_threads(), omp_get_num_threads());
omp_set_num_threads(6);
printf("ID: %d, Max threads: %d, Num threads: %d \n", omp_get_thread_num(), omp_get_max_threads(), omp_get_num_threads());
return 0;
}
编译:gcc -fopenmp API.c -o api
运行:./api

MPI(Message Passing Interface)
0、 定义:
1、MPI是一个库,而不是一门语言。许多人认为,MPI就是一种并行语言,这是不准确的。但是,按照并行语言的分类,可以把FORTRAN+MPI或C+MPI看作是一种在原来串行语言基础之上扩展后得到的,并行语言MPI库可以被FORTRAN77/C/Fortran90/C++调用,从语法上说,它遵守所有对库函数/过程的调用规则,和一般的函数/过程没有什么区别;
2、MPI是一种标准或规范的代表
3、MPI是一种消息传递编程模型
安装OpenMPI或者MPICH去实现我们所学的MPI的信息传递标准。
-
MPI 是 Message Passing Interface 的简称
-
MPI 是一套标准,而实际的实现有许多
- 包括但不限于 OpenMPI(conv 集群上使用的)和 MPICH(教程中使用的)
-
MPI 为包括 Fortran77, C, Fortran90 和 C++ 在内的一系列编程语言提供了并行函数库
-
MPI 是进程 (process) 级并行,process 间内存不共享,与线程 (thread) 级并行不同!!!
MPI --mpich的下载安装及配置 略
一、MPI几个常用函数
| MPI_Init | 只需在MPI程序开始时调用即可(必须保证程序中第一个调用的MPI函数是这个函数)。 | call MPI_INIT() # Fortran MPI_Init(&argc, &argv) //C++ & C |
| MPI_Finalize | 任何MPI程序结束时,都需要调用该函数。切记Fortran在调用MPI_Finalize的时候,需要加个参数ierr来接收返回的值,否则计算结果可能会出问题甚至编译报错。在Fortran中ierr为integer型变量。 该函数同第一个函数,都不必深究,只需要求格式去写即可 | call MPI_Finalize(ierr)# Fortran MPI_Finalize() //C++ |
| MPI_COMM_RANK | 该函数是获得当前进程的进程标识,如进程0在执行该函数时,可以获得返回值0。可以看出该函数接口有两个参数,前者为进程所在的通信域,后者为返回的进程号。通信域可以理解为给进程分组,比如有0-5这六个进程。可以通过定义通信域,来将比如[0,1,5]这三个进程分为一组,这样就可以针对该组进行“组”操作,比如规约之类的操作。 是MPMPI_COMM_WORLDI已经预定义好的通信域,是一个包含所有进程的通信域,目前只需要用该通信域即可。 在调用该函数时,需要先定义一个整型变量如myid,不需要赋值。将该变量传入函数中,会将该进程号存入myid变量中并返回。 | call MPI_COMM_RANK(comm, rank) #F
int MPI_Comm_Rank(MPI_Comm comm, int *rank) //c |
| MPI_COMM_SIZE | 该函数是获取该通信域内的总进程数,如果通信域为MP_COMM_WORLD,即获取总进程数,使用方法和MPI_COMM_RANK相近 | MPI_COMM_SIZE(comm, size) #F int MPI_Comm_Size(MPI_Comm, int *size) //c |
| MPI_SEND | 该函数为发送函数,用于进程间发送消息,如进程0计算得到的结果A,需要传给进程1,就需要调用该函数。 | call MPI_SEND(buf, count, datatype, dest, tag, comm)#F
int MPI_Send(type* buf, int count, MPI_Datatype, int dest, int tag, MPI_Comm comm) //c
|
| MPI_RECV | 该函数为MPI的接收函数,需要和MPI_SEND成对出现。类似Qt中的send和recieive了 | call MPI_RECV(buf, count, datatype, source, tag, comm,status) #F int MPI_Recv(type* buf, int count, MPI_Datatype, int source, int tag, MPI_Comm comm, MPI_Status *status) //c |
如:
int main(int *argc,char* argv[])
{
MPI_Init(&argc,&argv);
}
比如,让进程0输出Hello,让进程1输出Hi就可以写成如下方式。
| fortran | c/c++ |
Program main
use mpi
implicit none
integer :: myid
MPI_INIT()
call MPI_COMM_RANK(MPI_COMM_WOLRD,myid)
if (myid==0) then
print *, "Hello!"
end if
if (myid==1)
print *, "Hi!"
end if
MPI_FINALIZE()
end Program | #include "mpi.h"
int main(int *argc,char* argv[])
{
int myid;
MPI_Init(&argc,&argv);
MPI_Comm_Rank(MPI_COMM_WORLD,&myid);
if(myid==0)
{
printf("Hello!");
}
if(myid==1)
{
printf("Hi!");
}
MPI_Finalize();
} |
| int MPI_Send(type* buf, int count, MPI_Datatype, int dest, int tag, MPI_Comm comm) //c |
该函数参数过多,不过这些参数都很有必要存在。这些参数均为传入的参数,
- buf为你需要传递的数据的起始地址,比如你要传递一个数组A,长度是5,则buf为数组A的首地址。
- count即为长度,从首地址之后count个变量。
- datatype为变量类型,注意该位置的变量类型是MPI预定义的变量类型,比如需要传递的是C++的int型,则在此处需要传入的参数是MPI_INT,其余同理。
- dest为接收的进程号,即被传递信息进程的进程号。
- tag为信息标志,同为整型变量,发送和接收需要tag一致,这将可以区分同一目的地的不同消息。比如进程0给进程1分别发送了数据A和数据B,tag可分别定义成0和1,这样在进程1接收时同样设置tag0和1去接收,避免接收混乱。
call MPI_RECV(buf, count, datatype, source, tag, comm,status) 参数和MPI_SEND大体相同,不同的是source这一参数,这一参数标明从哪个进程接收消息。最后多一个用于返回状态信息的参数status。
- 在C和C++中,status的变量类型为MPI_Status,分别有三个域,可以通过status.MPI_SOURCE,status.MPI_TAG和status.MPI_ERROR的方式调用这三个信息。这三个信息分别返回的值是所收到数据发送源的进程号,该消息的tag值和接收操作的错误代码。
- 在Fortran中,status的变量类型为长度是MPI_STATUS_SIZE的整形数组。通过status(MPI_SOURCE),status(MPI_TAG)和status(MPI_ERROR)来调用。
- SEND和RECV需要成对出现,若两进程需要相互发送消息时,对调用的顺序也有要求,不然可能会出现死锁或内存溢出等比较严重的问题,具体在之后的对等模式这一章中详细介绍。
//j举例
MPI_Init(&argc,&argv);
MPI_Comm_rank(MPI_COMM_WORLD,&myid); //得到的变量myid即为当前的进程号
//假设要求和的数组为A={[1,1,1,1],[2,2,2,2]}
if(myid==0)
{
memset(A,1,sizeof(int)); //将数组A全赋值为1
}
else if (myid==1)
{
memset(A,2,sizeof(int)); //将数组A全赋值为2
}
//以上部分是将数组的两行分别存储到进程0和进程1上
for(int i=0;i<4;i++)
{
s=s+A[i];
}
if(myid==1)
{
MPI_Send(s,1,MPI_INT,0,99,MPI_COMM_WORLD);
//将求和结果s发送到进程0
}
if(myid==0)
{
MPI_Recv(s1,1,MPI_INT,1,99,MPI_COMM_WORLD,&status);
//用s1这个变量来存储从进程1发送来的求和结果
s=s+s1;
}
printf("%d",&s);
//本代码只是用于讲解MPI如何实现数据通信,真正的并行程序是不会这么写的,在之后的章节会介绍对等模式和主从模式。在用MPI进行计算时,消息通信的时间成本是比较大的,所以通常会采用重复计算来避免不必要的通信,使总运行时间变短。在具体优化代码时,是需要分析通信时间和计算时间,使其达到一个最优平衡。不过,下面这个程序可以看出MPI程序的基本写法和几个基本操作。MPI与并行计算01:基础知识 - Link Blog | 凌的博客 【原文链接】
CUDA
CUDA(Compute Unified Device Architecture),显卡厂商NVidia推出的运算平台。
【有点像MapReduce都是计算平台】【这个是并行 MapReduce是分布式也算并行 若是数据级并行 都不能有数据i相关性】
CUDA™是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。它包含了CUDA指令集架构(ISA)以及GPU内部的并行计算引擎。开发人员现在可以使用C语言来为CUDA™架构编写程序,C语言是应用最广泛的一种高级编程语言。所编写出的程序于是就可以在支持CUDA™的处理器上以超高性能运行。还支持其它语言,包括FORTRAN以及C++。
CPU(中央处理器)和GPU(图形处理器)是计算机硬件中的两个重要组成部分,它们在设计目的、结构、功能以及并行计算能力方面存在显著差异。以下是关于CPU和GPU的区别、各自的优点以及与并行计算关系的详细分析:
一、CPU与GPU的区别
- 设计目的:
- CPU:设计用于高效地处理各种不同的任务,包括操作系统、应用程序、网络通信等的运行,以及处理顺序执行的代码和复杂的逻辑判断。
- GPU:最初是为了快速渲染图像和视频而设计的,它专长于处理图形和视觉效果相关的计算,以及大量并行处理相同的计算任务。
- 结构:
- CPU:通常具有较少的核心数量,但每个核心都很强大,具备较高的单线程性能和灵活性。
- GPU:则拥有大量的小型核心(流处理器),这些核心专为执行大量相同的计算任务并行操作而优化。
- 功能:
- CPU:是系统的核心(就是电脑自带的处理核心数吧),负责执行各种计算和控制任务,能够处理复杂的逻辑和多种数据类型。
- GPU:除了图形渲染外,还广泛应用于科学计算、深度学习、加密货币挖掘等领域,处理大量的矩阵运算和并行数据处理。
二、CPU GPU各自的优点
- CPU的优点:
- 通用性强:能够执行各种类型的任务,包括数据运算、程序控制等。
- 逻辑判断能力强:适合处理复杂的逻辑判断和顺序执行的任务。
- 功耗和散热相对较低:由于核心数量较少,功耗和散热设计相对简单。
- GPU的优点:
- 并行处理能力强:拥有大量的处理核心和专门的并行计算架构,能够同时处理多个任务。
- 浮点运算性能高:在处理浮点数运算时性能较高,适合于科学计算、深度学习和人工智能等领域的应用。
- 加速图形渲染:能够快速渲染图像和视频,提供高质量的图形输出。
三、与并行计算的关系
- CPU的并行计算能力:
- CPU虽然也支持并行计算,但通常是通过多线程技术(如openMP?)来实现的,其并行计算能力相对有限。
- CPU更适合处理顺序计算和复杂的控制任务,以及需要频繁切换和调度的任务。
- GPU的并行计算能力:
- GPU的并行计算能力非常强大,能够同时处理大量的并行任务。
- GPU的并行计算架构使其在处理大规模数据集和复杂计算任务时具有显著优势。
- 在深度学习、科学计算等领域,GPU已经成为不可或缺的加速工具。
- CPU与GPU的协同工作:
- 在现代计算机系统中,CPU和GPU常常配合使用,以发挥各自的优势。
- 许多应用程序和框架(如深度学习框架TensorFlow、PyTorch等)都利用了CPU和GPU的协同工作,将适合并行计算的任务交给GPU来处理(通过.cuda()实现?),从而提高了计算效率和性能。
四、GPU与CUDA关系
-
GPU:
- 定义:GPU(Graphics Processing Unit)即图形处理器,是显卡的核心,专门用于处理图形和图像数据。电脑自带的?
- 功能:GPU具有更多的计算单元和更高的并行计算能力,因此在处理大量数据时具有更高的性能。随着技术的发展,GPU已经不仅仅局限于图形处理,而是广泛应用于各种需要大量并行计算的场景,如科学计算、深度学习等。
-
CUDA:
- 定义:CUDA(Compute Unified Device Architecture)是由NVIDIA公司开发的一种通用并行计算架构和编程模型。
- 功能:CUDA允许开发者使用C、C++、Python等高级语言进行编程,并能加速GPU的运算和处理。它提供了一套完整的软件开发工具包,包括编译器、调试器、库函数等,帮助开发人员更容易地将应用程序移植到GPU上运行。
二、CUDA与GPU的协同工作
- 编程模型:CUDA为开发人员提供了一个统一的编程模型,使得他们可以使用C语言和CUDA C/C++编写程序,并将这些程序部署到GPU上运行。
- 硬件加速:通过CUDA,开发者可以深入探索GPU的深层能力,实现高效计算和加速任务。GPU的并行处理能力远远超过CPU,CUDA利用这一优势,可以在很多应用中提供显著的性能提升。
- 生态系统:CUDA拥有一个庞大的生态系统,包括各种库(如cuDNN for deep learning)、工具和社区支持。这使得CUDA成为科学计算和工程应用的首选平台之一。
三、CUDA与GPU的应用领域
- 图形处理:GPU是图形处理的核心,而CUDA使得GPU能够更高效地处理图形渲染任务。
- 科学计算:CUDA使得GPU可以用于各种非图形计算任务,如科学模拟、数据分析等。
- 深度学习:cuDNN是基于CUDA的深度学习库,为深度学习框架(如TensorFlow、PyTorch等)提供了高效的卷积、池化、归一化等基本操作的实现。通过使用cuDNN,开发人员可以在GPU上实现高速的深度学习模型训练和推理。
除了上述叙述之外,我们通过资料得到CUDA 4.0架构版本还包含大量其它特性与功能,其中包括:
1、MPI与CUDA应用程序相结合——当应用程序发出MPI收发调用指令时,例如OpenMPI等改编的MPI软件可通过Infiniband与显卡显存自动收发数据。
2、GPU多线程共享——多个CPU主线程能够在一颗GPU上共享运行环境,从而使多线程应用程序共享一颗GPU变得更加轻松。
3、单CPU线程共享多GPU——一个CPU主线程可以访问系统内的所有GPU。 开发人员能够轻而易举地协调多颗GPU上的工作负荷,满足应用程序中“halo”交换等任务的需要。
原文链接:https://blog.youkuaiyun.com/weixin_42819452/article/details/102807147
原文链接:https://blog.youkuaiyun.com/weixin_42819452/article/details/102816640


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









