 Makefile、gdb、pdb与cmake学习笔记
Makefile、gdb、pdb与cmake学习笔记




Makefile
1.什么是Makefile脚本?
Makefile脚本集合了程序的编译指令的文件,make是一个命令工具,当执行make命令时,它会自动读取Makefile中的编译指令并执行,会自动完成整个项目的自动化编译工作.
2.为什么需要Makefile脚本:
项目中如果有很多.c文件,它们的编译指令会有很多,需要的编译时间比较长,依赖关系非常复杂。
当项目中的.h文件被修改时,对应的.c文件需要重新编译,但是我们无法人为的分辨出哪些文件需要重新编译,只能全部重新编译一下,这项操作非常耗时。此时Makefile便发挥了用场.
所以make/Makefile又叫自动化的构建项目.
Makefile简单的编写
Makefile主要由两部分组成:a.依赖关系,b.依赖方法
我们直接 vim Makefile 此时便会创建一个Makefile文件并且打开.
依赖关系:
mytest:test.c
其中mytest称作目标文件,test.c称作依赖文件.
依赖方法:
必须第依赖关系的下一行,以Tab键为空开始写.
编译源文件,需要用到gcc,之前所讲过的.
gcc test.c -o mytest 【或gcc -o mytest test.c -std=c99】
注:-std=c99表示以c99的标准来编译代码
这样一个简单的Makefile文件便写好了
1 mytest:test.c
2 gcc -o mytest test.c -std=c99 //注意缩进要用制表符tab
3 .PHONY:clean
4 clean:
5 rm -rf mytest这段Makefile的代码定义了一个名为clean的伪目标(phony target),其目的是删除名为mytest的文件或目录(包括其下的所有文件和子目录)。下面是这段代码的详细解释:
-
.PHONY: clean:这一行告诉make工具clean是一个伪目标,即它不是一个实际要生成的文件名。这很重要,因为有时候文件名和目标名可能会冲突,使用.PHONY可以确保无论是否存在名为clean的文件,make clean命令都会执行下面的命令。
-
还有一个作用就是总是被执行.
- 什么叫总是被执行呢?先来看如果我们一直make会发生什么呢?

- 可以发现这里的意思是说mytest已经是最新了.但是我就是想让它每次都执行,这个时候你在前面加上.PHONY即可:

然后退出,便可以每次都被执行了.

当你在命令行中运行make clean时,这条命令会删除当前目录下名为mytest的文件或目录及其所有内容。这在清理编译生成的文件或进行项目清理时非常有用
怎么知道我的可执行程序是最新的呢?
根据文件的最近修改时间!
这里有一条命令stat,它可以查看一个文件的重要的三个时间!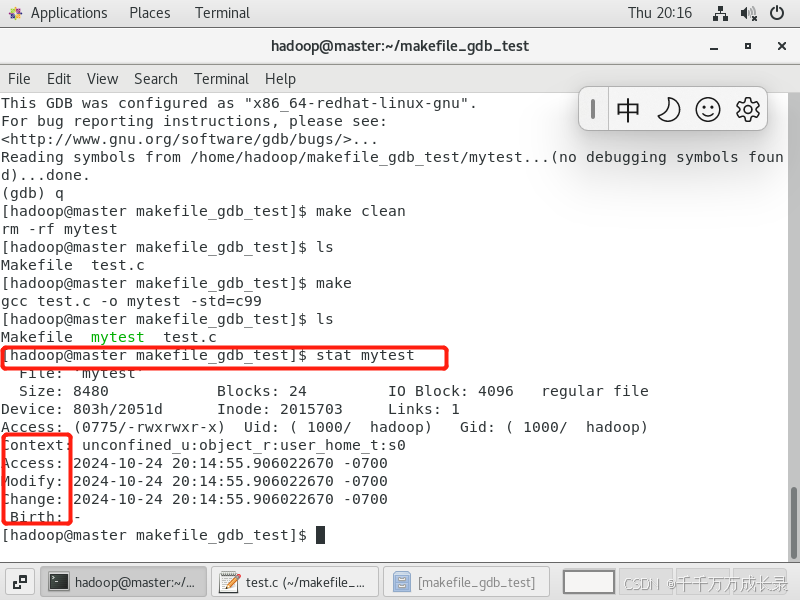
gdb
一、概述
- 如果要进入gdb开始调试,那直接
gdb + 可执行程序即可
- 不过进去之后发现似乎有一些奇怪的内容,【no debugging symbols found】,翻译过来就是没有调试信息。
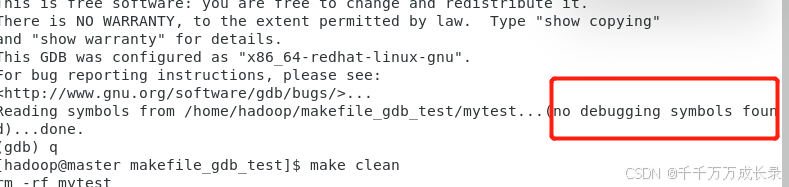
是因为我们现在是在默认的release版本下
- 只有在【DeBug】的环境下才会有我们想要的调试信息,所以可以初步推断这可能不是一个【DeBug】版本的可执行程序
- 先使用
q(quit)退出gdb
【Debug版本】与【Release版本】的区别
📚【Debug】—— 调试版本
📚【Release】—— 发布版本
- 我们程序员在编写代码后运行一般是使用【DeBug】环境进行运行。因为在企业里写软件项目,将代码写完后程序员自己要做简单的测试,保证代码没有问题
- 下面是vs界面
当程序员自己测试完没有问题之后,就会将这个可执行程序给到测试人员进行测试,而且会给出自己的单元测试报告。对于测试人员来说所处的模式是【Release】,也就是将来客户要使用的这款软件的发布版本
当测试在测的过程中,一定会发现一些问题。此时测试人员就会把报告再打回研发部。研发部做修改重新生成Release版本的可行性程序给到测试人员继续测试
最后只有当测试通过了,再将生成的【单元测试报告】与产品经理进行核对之后没有问题,那这个软件才可以真正地面向市场👉
牛牛牛哇!!!!!⚡ :程序的发布方式有两种,debug模式和release模式
⚡ :Linux gcc/g++出来的二进制程序,默认是release模式
⚡ :要使用gdb调试,必须在源代码生成二进制程序的时候, 加上-g选项
原文链接:https://blog.youkuaiyun.com/weixin_45031801/article/details/134399664

二、使用GDB调试代码----指令学习
1.指令列表 对应含义
注:()括号里面是该指令的全称
| | 显示对应的code,每次10行 |
r(run) —— F5(快捷键) | 【无断点直接运行、有断点从第一个断点处开始运行】 |
b(breakpoint) + 行号 | 在那一行打断点 |
b 源文件:函数名 | 在该函数的第一行打上断点 |
b 源文件:行号 | 在该源文件中的这行加上一个断点吧 |
info b | 查看断点的信息 如breakpoint already hit 1 time【此断点被命中一次】 |
d(delete) + 当前要删除断点的编号 | 删除一个断点【不可以d + 行号】 若当前没有跳出过gdb,则断点的编号会持续累加 |
d + breakpoints | 删除所有的断点 |
disable b(breakpoints) | 使所有断点无效【默认缺省】 |
enable b(breakpoints) | 使所有断点有效【默认缺省】 |
disable b(breakpoint) + 编号 | 使一个断点无效【禁用断点】 |
|
| 使一个断点有效【开启断点】 与disable相对 相当于VS中的空断点 |
n(next) ---快捷键F10 | 逐过程【相当于F10,为了查找是哪个函数出错了】 |
s(step) ---快捷键F11 | 逐语句【相当于F11,】 |
bt | 看到底层函数调用的过程【函数压栈】 |
set var | 修改变量的值 |
p(print) 变量名 | 打印变量值 |
display | 跟踪查看一个变量,每次停下来都显示它的值【变量/结构体…】 |
undisplay + 变量名编号 | 取消对先前设置的那些变量的跟踪 |
until + 行号 | 进行指定位置跳转,执行完区间代码 |
finish | 在一个函数内部,执行到当前函数返回,然后停下来等待命令 |
c(continue) | 从一个断点处,直接运行至下一个断点处【VS下不断按F5】 |
2.指令运行实操
行号显示
- 首先我们进入到gdb,然后它会等待我们输入指令
- l 随机显示10行内容
(list) 行号/函数名
- 若是【L 0】或者是【L 1】的话那就是从第一行开始往下列10行的内容
- 注意这里的L是小写,而且与数字之间要有一个空格
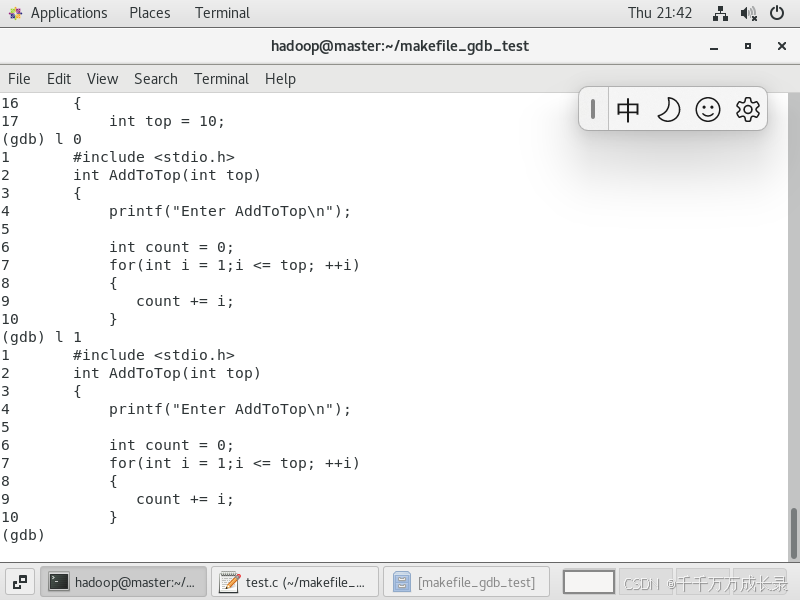
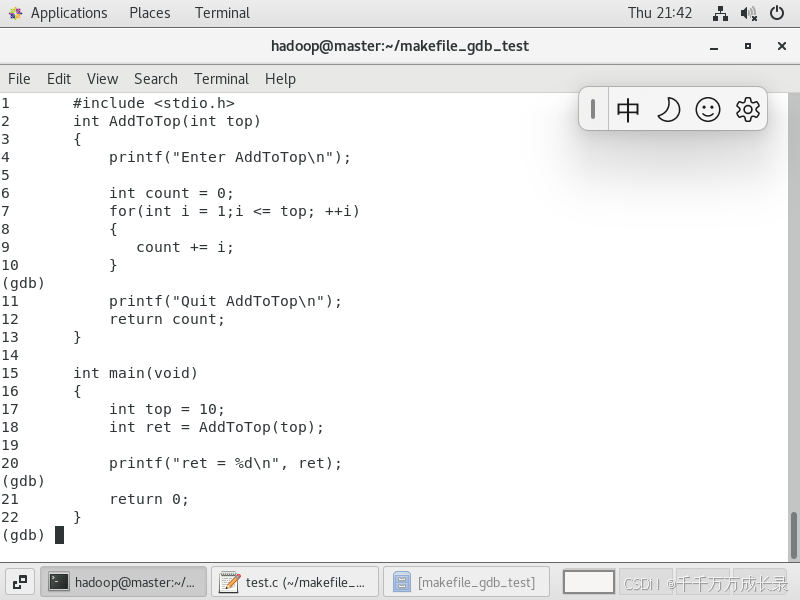
- 接下去若是想要看到我们所写的全部代码,只需要多
Enter几次就可以了,gdb会自动记忆你上次敲入的指令
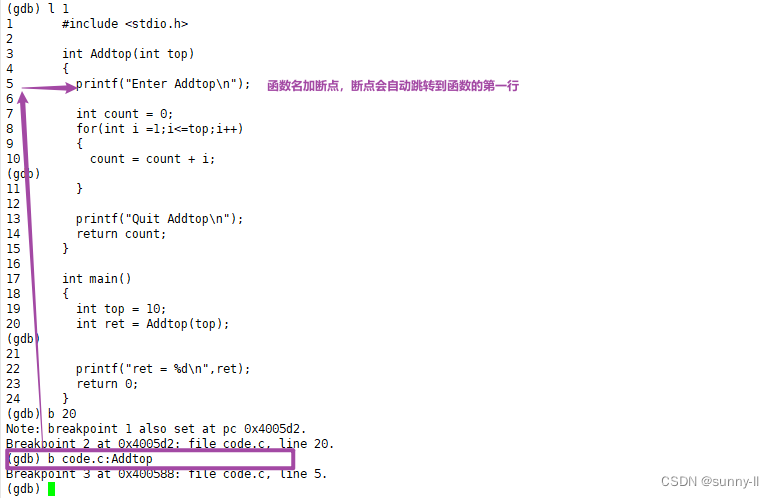
✨断点设置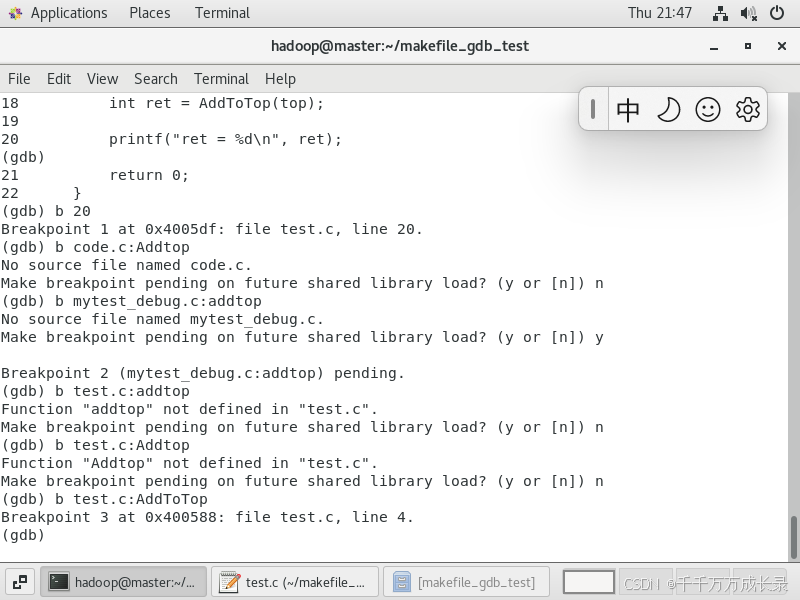
b + 行号—— 在那一行打断点
b 源文件:函数名—— 在该函数的第一行打上断点
b 源文件:行号—— 在该源文件中的这行加上一个断点


查看断点信息
info b —— 查看断点的信息
若是直接执行【info】的话,出来的就是所有的调试信息
但若是我们只想查看一下所打的断点的信息,那就在后面加个b/breakpoint
接下来简要介绍一下断点的一些字段信息
- Num —— 编号
- Type —— 类型 如breakpoint
- Disp —— 状态 如keep
- Enb —— 是否可用 y/n/..
- Address —— 地址
- What —— 在此文件的哪个函数的第几行
最后的话就是每个断点信息的下面这块breakpoint already hit 1 time即此断点被命中1次
删除断点
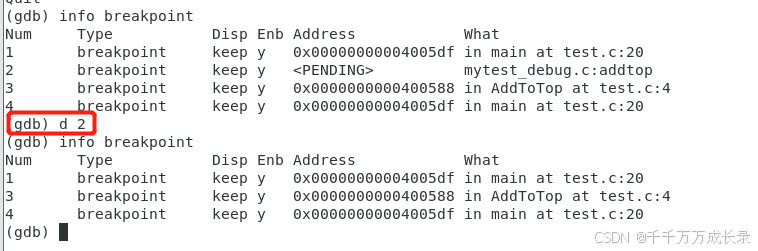
d + breakpoints —— 删除所有的断点

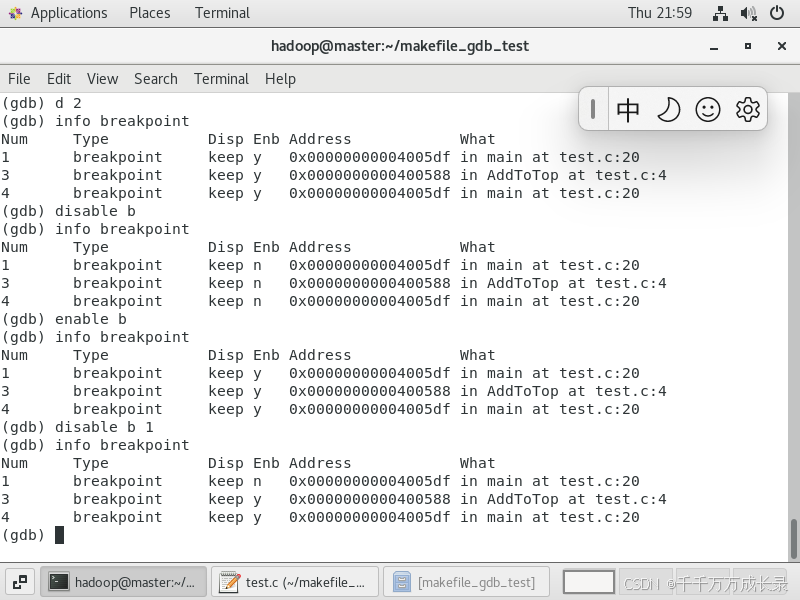
开启 / 禁用断点
disable b(breakpoints) —— 使所有断点无效【默认缺省】
enable b(breakpoints) —— 使所有断点有效【默认缺省】
disable b(breakpoint) + 编号 —— 使一个断点无效【禁用断点】
enable b(breakpoint) + 编号 —— 使一个断点有效【开启断点】
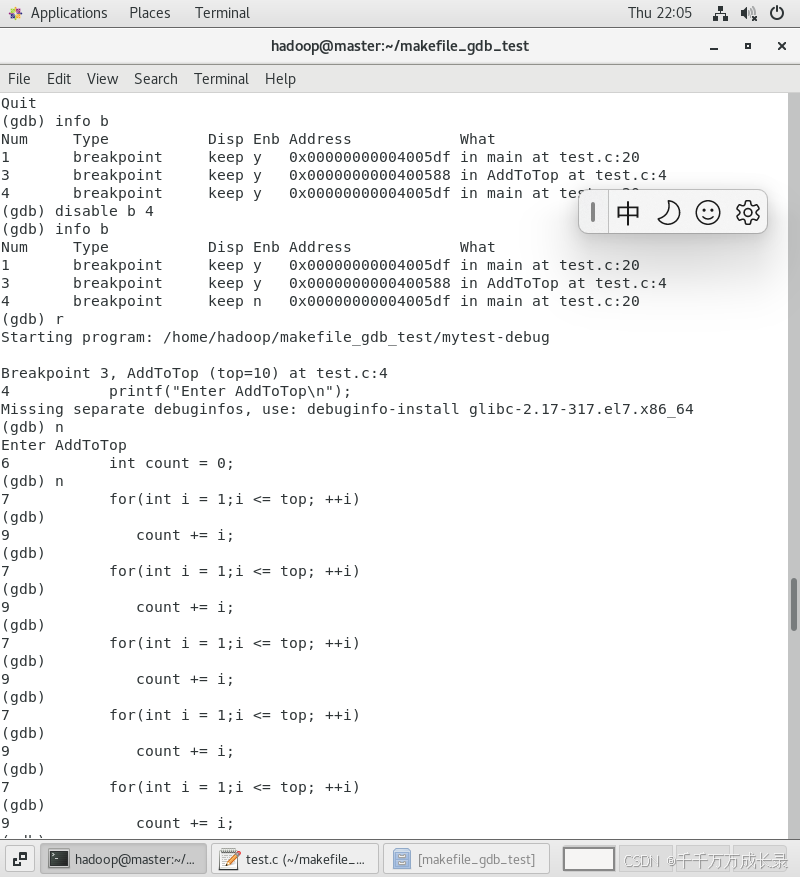
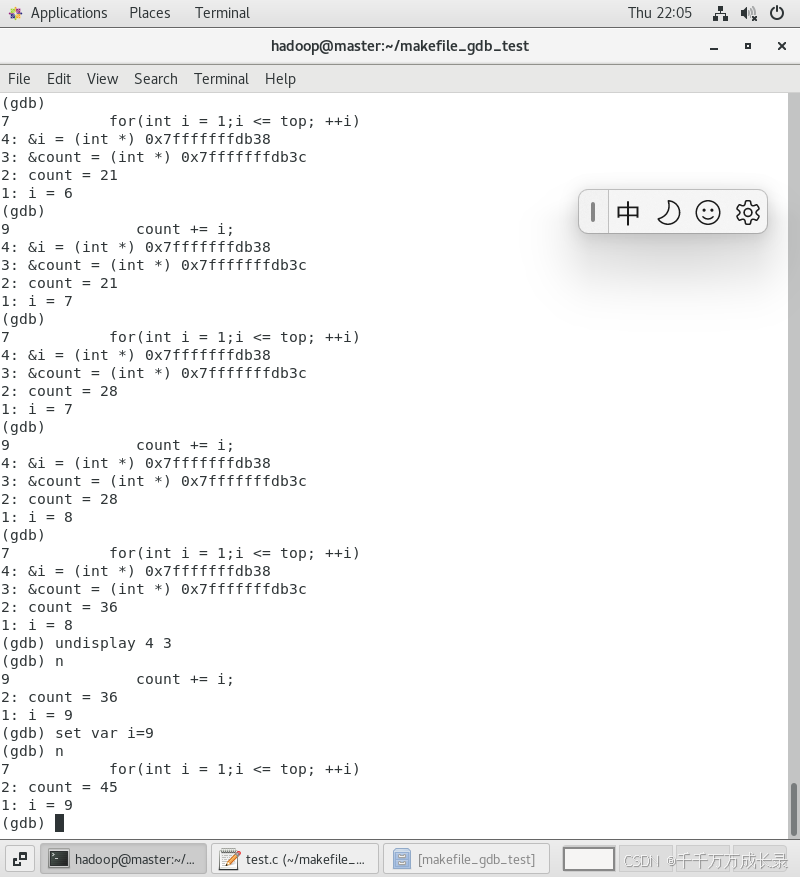
打印 / 追踪变量
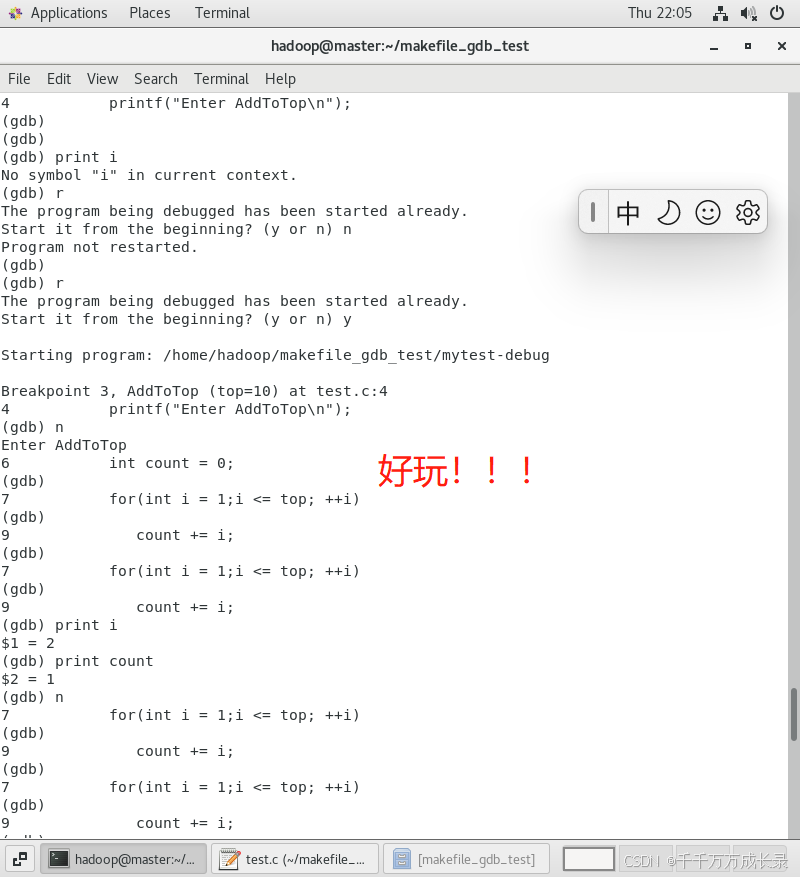
p(print) 变量名 —— 打印变量值
都执行了那么多次了,不知道【i】和【count】发生了怎样的变化,将它们打印出来看看吧💻
通过继续执行【n】,然后再去打印就可以发现i的值和count的值发生了变化
但是你不觉得这样每次去打印会显得很繁琐吗,那一定会的,所以我们有更好的办法💡
display —— 跟踪查看一个变量,每次停下来都显示它的值【变量/结构体…】
我们也可以去追踪一下这两个变量的地址,不过可以看到对于地址来说是不会发生改变的
undisplay + 变量名编号 —— 取消对先前设置的那些变量的跟踪
但是呢,每次都追踪打印这么多内容又太多了,我想把它们取消了可以吗?答:当然是可以的
既然有display,那就有undisplay
查看函数调用
bt —— 看到底层函数调用的过程【函数压栈】
通过仔细观察刚才追踪的4个变量最左侧的编号,就可以看到它们的排列的顺序是倒着的。因为变量i和变量count是我们先追踪的,它们的地址是我们后追踪的,所以可以看出这很像是一个压栈的过程

其实不仅是对于它们,AddToTop函数和main函数也呈现这样的关系。此时我们就可以通过【bt】这个指令来查看函数压栈的过程,此时便可以看到因为
压栈 顾名思义把运行了的函数以栈的形式保存? 先进后出原则 先有main函数 所以main函数在底下
修改变量的值
set var—— 修改变量的值
- 对于这个修改变量的值,很像是在VS里调试之前设置的那种条件断点,可以使调试开始后直接运行到此断点处。不过对于【set var】而言是在调试过程中进行设置
最常用指令(指令三剑客)
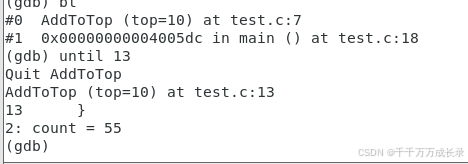
指定行号跳转
until + 行号 —— 进行指定位置跳转,执行完区间代码
可以看到,当前在for循环内容执行累加的逻辑,但若是我们一直这么执行下去,就没有时间排错了,除了上面的哪一种【set var】之外,还有一种方法其实起到直接结束当前循环的作用,那就是进行指定行号跳转
通过观察下图可以看到,当我们运行了until 13之后,程序直接就给出了我们最终的结果count,而且即将要执行最后的打印语句,说明我们跳转成功了
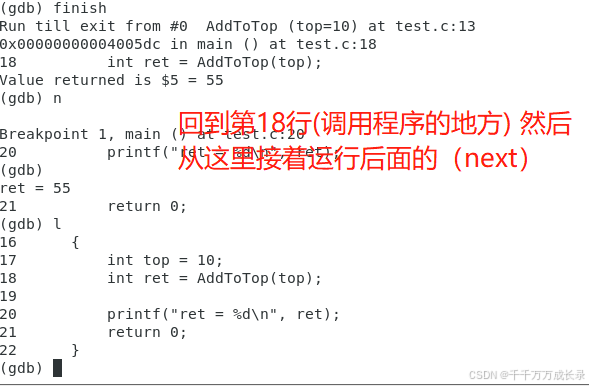
强制执行函数
finish —— 在一个函数内部,执行到当前函数返回,然后停下来等待命令
有时候我们会有这样的需求,在初步排查的时候推断可能是某个函数内部的逻辑出了问题,但是呢又不想一步步地进到函数内部进行调试,在VS中其实很简单,只需要在函数下方设个断点,然后F5直接运行到断点处即可
但是在Linux下的gdb中,我们可以使用【finsh】指令来直接使一个函数执行完毕。从下图我们可以看到,首先【s】进到函数内部,接下去我直接使用finish,可以看到它直接回到了调用函数的位置,returned了一个返回值

跳转到下一断点
c(continue) —— 从一个断点处,直接运行至下一个断点处【VS下不断按F5】
这点也是我刚才在上面有提到过的,在VS中,我们要直接跳转到下一个断点处只修要按下F5即可,那在gdb中该如何操作呢,你需要敲个【c】就可以了
从下图我们可以看出,对于这个指令的用处可谓是非常大,当我处于第一个断点也就是20行的时候,直接敲下【c】,就可以运行到第二个断点处也就是第10行。之后若反复敲【c】,因为这是一个单语句的循环,所以循环的下一次还是会执行到此处。上面的这两个功能就和我们在VS中用的F5是一个道理
一些指针命令的实操
pdb
原文链接:https://blog.youkuaiyun.com/qq_43799400/article/details/122582895
一、pdb 有2种用法
pdb:python debugger
1、非侵入式方法 (不用额外修改源代码,在命令行下直接运行就能调试)
python3 -m pdb filename.py
2、侵入式方法 (需要在被调试的代码中添加以下代码然后再正常运行代码)
import pdb
pdb.set_trace()
当你在命令行看到下面这个提示符时,说明已经正确打开了pdb
(Pdb)
pdb.set_trace()
pdb.set_trace()常见的放置位置:
在程序的开始处:
如果你想从头开始调试整个程序,可以在程序的开头(如紧跟在导入模块之后)放置 pdb.set_trace()。这样,程序会在开始执行任何主要功能之前暂停,你可以逐步跟踪整个程序的执行。
在感兴趣的代码段之前:
如果你只对程序的某一部分感兴趣,可以在该部分代码之前放置 pdb.set_trace()。例如,如果你怀疑某个函数中的错误,可以在调用该函数之前设置断点。
在错误发生的地方:
如果你已经知道程序在某个特定位置出错(例如,通过错误日志或之前的调试),可以在该位置前设置 pdb.set_trace()。这可以帮助你理解出错时的上下文环境。
在循环或条件语句中:
对于复杂的循环或条件语句,你可能希望在循环的每次迭代或条件分支的开始处设置断点,以便检查每次迭代或分支的状态。
在函数定义中:
你也可以在函数定义的开始处放置 pdb.set_trace(),这样每次调用该函数时都会进入调试模式3.1 在本文件中的指定位置设置断点
比如,要想进入到模型的 forward() 方法中查看前向传播过程中的数据处理过程,只能在 forward() 的第一行(即26行)设置断点,pdb.set_trace()
但有时候模型很复杂,用这种方法会导致程序报错直接退出(我也不知道是什么原因),那么我们就可以考虑用 break 命令在这一行插入断点,使得程序运行到 forward() 时就会停下来。
二、pdb 基本命令
与gdb基本相同,不列表格了
break 或 b 设置断点
continue 或 c 继续执行程序 【下一个断点?】
list 或 l 查看当前行的代码段
step 或 s 进入函数(进入 for 循环用 next 而不是用 step)
return 或 r 执行代码直到从当前函数返回
next 或 n 执行下一行
up 或 u 返回到上个调用点(不是上一行)
p x 打印变量x的值
exit 或 q 中止调试,退出程序
help 帮助
cmake
cmake使用详细教程(日常使用这一篇就足够了)_cmake教程-优快云博客
详细见上面链接博客
一、我需新记:
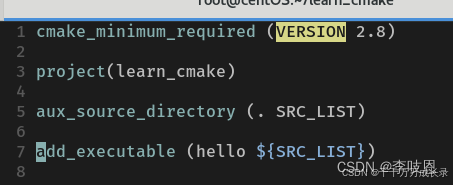
CMakeLists.txt (注意CMakeLists大小写,不要写错了)内容:
cmake_minimum_required (VERSION 2.8)
project (learn_cmake)
add_executable(hello hello.cpp)- 第一行意思是cmake最低版本要求2.8,
- 第二行是本项目的工程名
- 第三行:第一个变量:要生成的可执行文件名为hello,后面的参数是需要的依赖。
接着在当前目录下执行 cmake . 会发现目录下多生成了一些文件,例如Makefile
#cmake .
然后使用GNU make来编译程序 会发现已生成可执行程序,并可以正常执行
#make
二、同一目录下多个源文件
此时在当前目录新增两个依赖,并mian函数的执行需要依赖这两个文件
add.cpp
add.h
只需要在CMakeLists.txt中添加所依赖的.cpp文件,编译步骤和上面相同

三、同一目录下很多源文件
如果同一目录下有无穷多源文件,那么一个一个添加就很慢了。此时可以使用cmake中的函数存储这些源文件
aux_source_directory(dir var)
他的作用是把dir目录中的所有源文件都储存在var变量中
然后需要用到源文件的地方用 变量var来取代
此时 CMakeLists.txt 可以这样优化
注意:变量的使用和Makefile不同,CMake是利用大括号,如 ${index}
原文链接:https://blog.youkuaiyun.com/weixin_45031801/article/details/134399664 gdb命令及演示操作
原文链接:https://blog.youkuaiyun.com/weixin_47257473/article/details/131675814 makefile 使用方法

















 1613
1613

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









