







1. Blending集成学习思路
Blending集成学习方式:
(1) 将数据划分为训练集和测试集(test_set),其中训练集需要再次划分为训练集(train_set)和验证集
(val_set);
(2) 创建第一层的多个模型,这些模型可以使同质的也可以是异质的;
(3) 使用train_set训练步骤2中的多个模型,然后用训练好的模型预测val_set和test_set得到val_predict,
test_predict1;
(4) 创建第二层的模型,使用val_predict作为训练集训练第二层的模型;
(5) 使用第二层训练好的模型对第二层测试集test_predict1进行预测,该结果为整个测试集的结果。
bending是一种模型融合方法,对于一般的blending,主要思路是把原始的训练集先分成两部分,比如70%的数据作为新的训练集,剩下30%的数据作为测试集。第一层我们在这70%的数据上训练多个模型,然后去预测那30%数据的label。在第二层里,我们就直接用这30%数据在第一层预测的结果做为新特征继续训练即可。
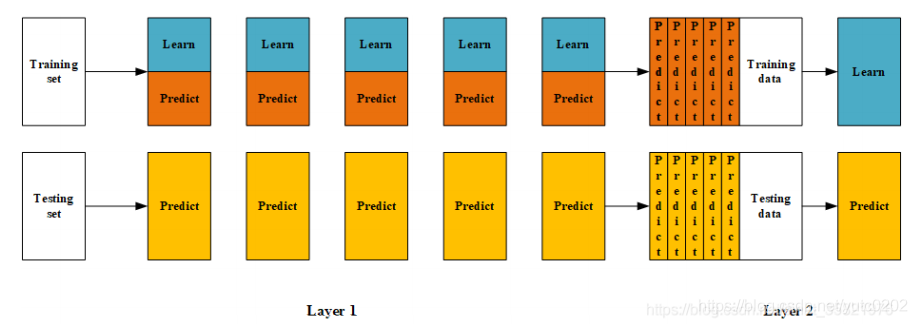
在(2)-(3)步中,我们使用训练集创建了K个模型,如SVM、random forests、XGBoost等,这个是第一层的模型。 训练好模型后将验证集输入模型进行预测,得到K组不同的输出,我们记作 ,然后将测试集输入K个模型也得到K组输出,我们记作 ,其中 的样本数与验证集一致, 的样本数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2894
2894

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









