



 本文介绍了在B站视频中关于强化学习中的概念,如State(状态)、Action(行动)、Reward(奖励),以及Q-learning算法中的Policy(策略)和Value(价值)计算。还讨论了Q-value函数和步长调整对延迟奖励和无延迟奖励环境的影响,以及MCMethod和Temporal-DifferenceLearning的区别。
本文介绍了在B站视频中关于强化学习中的概念,如State(状态)、Action(行动)、Reward(奖励),以及Q-learning算法中的Policy(策略)和Value(价值)计算。还讨论了Q-value函数和步长调整对延迟奖励和无延迟奖励环境的影响,以及MCMethod和Temporal-DifferenceLearning的区别。

B站链接
https://www.bilibili.com/video/BV13a4y1J7bw?p=1&vd_source=6f43d02eb274352809b90e8cdf744905
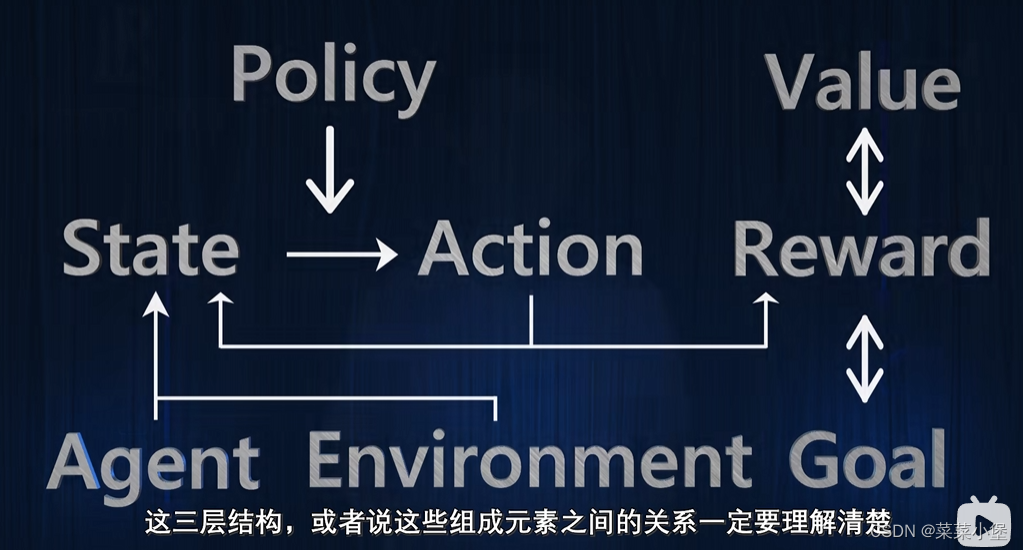
agent----------environment--------goal

State 状态
Action 行动
Reward奖励
是一个及时的反馈
目标是一个长远的结果
Core element👇
Policy 策略
当前需要决定的行动策略,policy依赖于value,可以理解为,policy输入的是state,输出是action
Value 价值
state-value函数
state-action-value函数
try_and_error delay_reward exploration exploitation

a = L(left)/R(right)
以上的Q可以理解是t时刻时进行行动a的价值函数。
选择action时,要选择在此刻t的Q(a_i)的最大值。


Qn+1Q_n+1Qn+1是第n+1次行动的估计价值,RnR_nRn是第n次行动的真实价值。1/n为步长。适用于没有延迟奖励👆且只有一个状态的情况

👆这个函数更受最近的action的影响,所以可能更适合奖励机制。
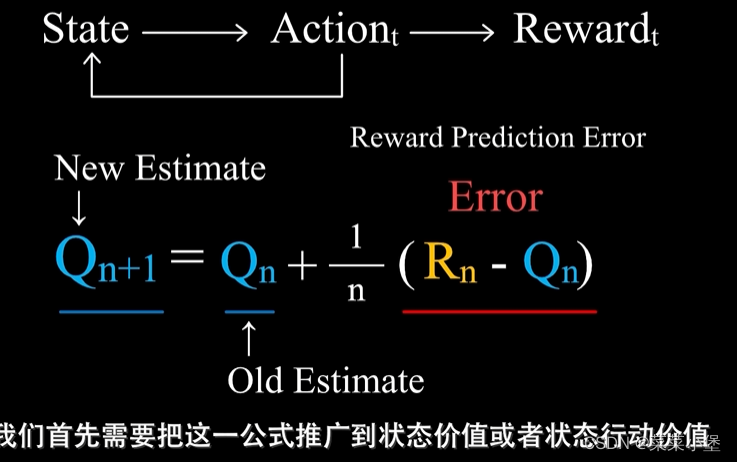
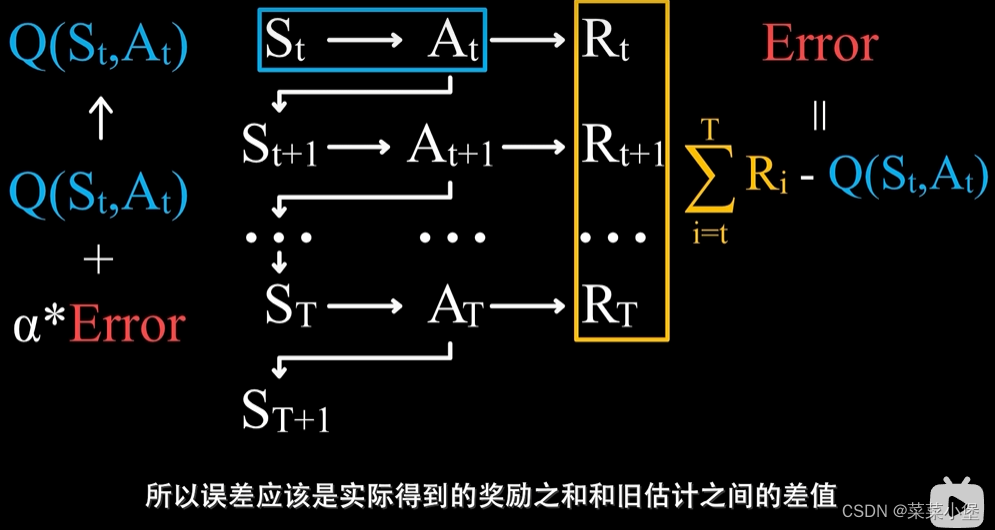
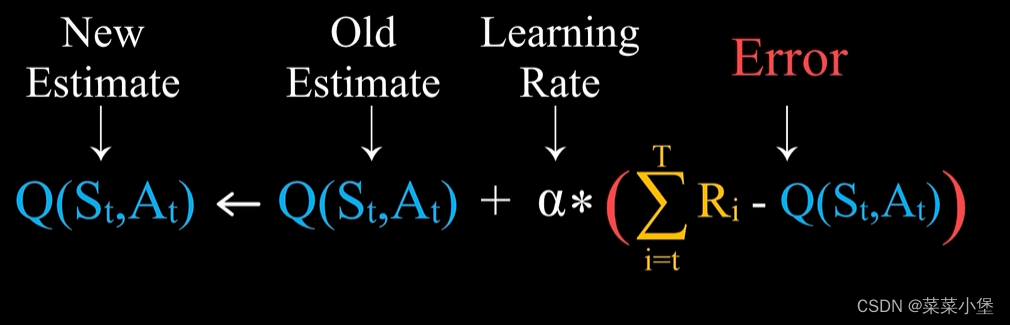
MC Method 和 Tempportal-Difference Learning分别类似于👇俩公式

MC method就是用随机性来模拟状态值。
Tempportal-Difference Learning。

















 1414
1414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









