









此文档用于记录平时使用正则表达式的心得,不定期更新
基础
实例
替换实例一
//这里匹配以 “( 开头,以 )” 结尾的字符串
private static Regex REGEX_ARG_CONTENT = new Regex(@"""@(.*?)""");
//此方法用于在匹配到的结果前添加@字符
format = REGEX_ARG_CONTENT.Replace(format, new MatchEvaluator((m) =>
{
string value = $"@{m}";
return value;
}));替换实例二
//分组构造,匹配以Properties.Resources.开始以,或)结束的字符串
(Properties.Resources.)(.*?)([,)])
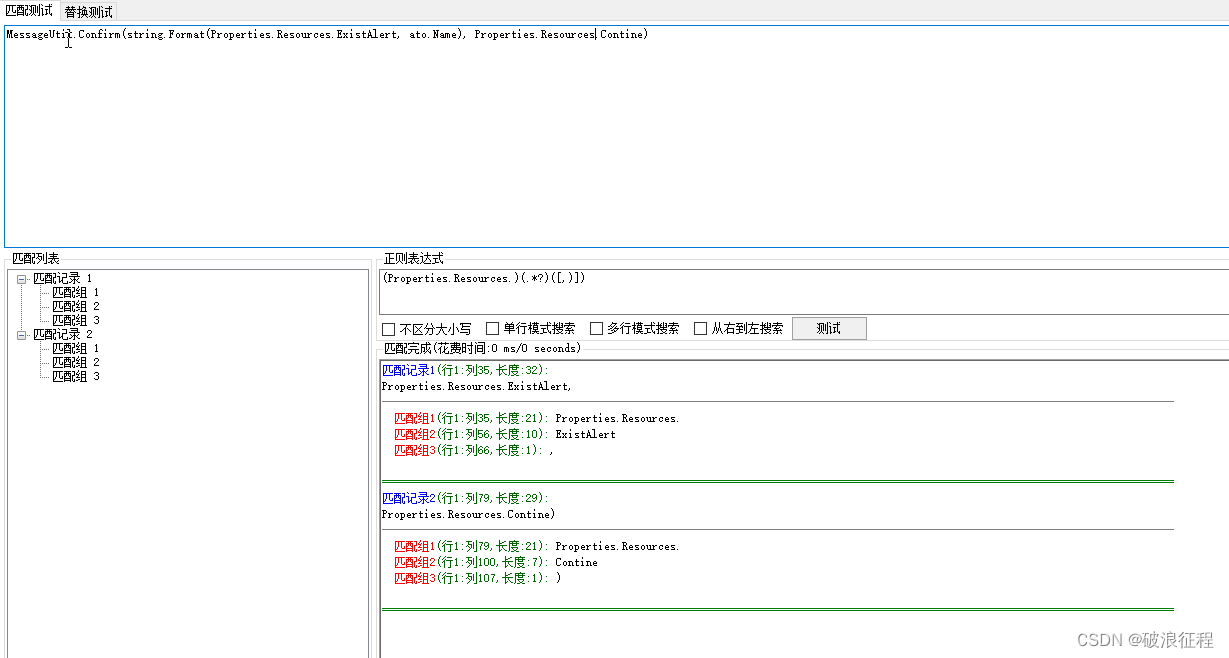
将匹配到的数据分组1替换为LanguageManager.GetString("
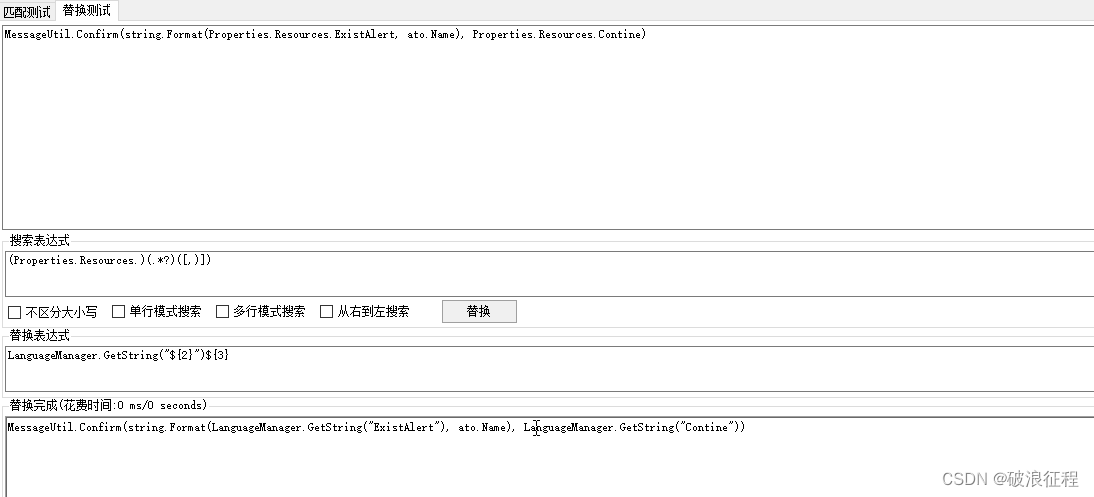
则匹配和替换字符串为:
//匹配字符串,这里使用()将匹配分成3个组
(Properties.Resources.)(.*?)([,)])
//将匹配结果替换如下,使用匹配结果中的分组2和3来组合最后的替换结果
LanguageManager.GetString("${2}")${3}
前一个字符不是某个字符
(?<!x)
可以使用负向零宽断言来实现,在正则表达式中,(?<!x) 表示匹配前一个字符不是x的情况,例如:要查找字符串中不是数字的字符,可以使用 (?<![0-9])\w,其中 (?<![0-9]) 表示前一个字符不是数字,\w 表示匹配任意一个字母、数字或下划线。
后一个字符不是某个字符
?![Xx]
可以使用否定后行断言来实现该功能。上面是一个示例,找到所有的字母,但字符串后面的字符不是X
[A-Za-z](?![Xx])
这个正则表达式使用 [A-Za-z] 匹配任何字母,然后使用 (?![Xx]) 表示后面的字符不是X或x。
请注意,否定后行断言只匹配前面的字符,不匹配在其后面的字符。因此,在使用这些表达式时,请确保在处理整个字符串之前消耗任何之后的匹配。
复杂正则一
@"((?:[\u4e00-\u9fa5_a-zA-Z0-9]:\\)?(?:[^\\?\/\*\|<>:\""]+\\)+[^\\?\/\*\|<>:\""]+\.(?:wav|mp3|mid))"
说明:^符号放在[]内表示取反,不匹配[]内的任一字符,[]后的+表示匹配多次
U4300-U9fa5代表了符合汉字GB18030规范的字符集,因为为了兼容,所有字符都以unicode编码实现,汉字也不例外.
官方文档:.NET 正则表达式 - .NET | Microsoft Learn
正则表达式语言 - 快速参考 - .NET | Microsoft Learn
a|b 匹配 a 或 b
gr(a|e)y 匹配 gray 或 grey
. 匹配任一字符,除了换行符和行结束符
[abc] 匹配任一字符: a 或 b 或 c
[^abc] 匹配任一字符, 但不包括 a, b, c
[a-z] 匹配从 a 到 z 之间的任一字符
[a-zA-Z] 匹配从 a 到 z, 及从 A 到 Z 之间的任一字符
^ 匹配文件名的头部
$ 匹配文件名的尾部
( ) 匹配标记的子表达式
\n 换行
\t 制表符
\b 匹配字词边界
\s 空白字符
\S 非空白字符
\d 数字
\D 除了数字
\w 单词字符,包括字母数字下划线
\W 非单词字符,除了字母数字下划线
* 匹配前一项内容 0 或多次
? 匹配前一项内容 0 或 1 次
+ 匹配前一项内容 1 或多次
*? 匹配前一项内容 0 或多次 (懒人模式)
+? 匹配前一项内容 1 或多次 (懒人模式)
{x} 匹配前一项内容 x 次
{x,} 匹配前一项内容 x 次或更多次
{x,y} 匹配前一项内容次数介于 x 和 y 之间
\ 特殊转义字符
// 创建一个正则表达式的对象java中进行正则表达式匹配:
String regex = "^1[38]\\d{9}$"; //定义好规则
boolean flag = s.matches(regex); //进行匹配
System.out.println("flag:"+flag);



















 1541
1541

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











