






 本文介绍了一种利用前馈神经网络进行多纹理合成的方法,该方法通过引入多样性损失和增量学习方案,解决了现有方法普遍性和多样性不足的问题。此外,还展示了如何将此方法应用于多风格迁移,实现了风格和内容的有效分离。
本文介绍了一种利用前馈神经网络进行多纹理合成的方法,该方法通过引入多样性损失和增量学习方案,解决了现有方法普遍性和多样性不足的问题。此外,还展示了如何将此方法应用于多风格迁移,实现了风格和内容的有效分离。
paper: Li, Yijun, et al. “Diversified texture synthesis with feed-forward networks.” IEEE CVPR 2017.
目前的判别和生成模型在纹理合成方面有较好的效果。但是,现存的基于前馈神经网络的方法往往牺牲generality(普遍性)来换取效率,这往往会引发以下问题: 1) 训练出的网络缺少generality(普遍性) : 也就是说对于每种纹理都要训练一个网络
2) 缺少diversity(多样性): 也就是说不同的输入容易得到视觉上几乎相同的输出。
3) suboptimality: 生成的效果不理想
文章训练了一种网络能够用一个网络生成多种texture,并能在测试阶段通过插值的方法生成新的纹理。
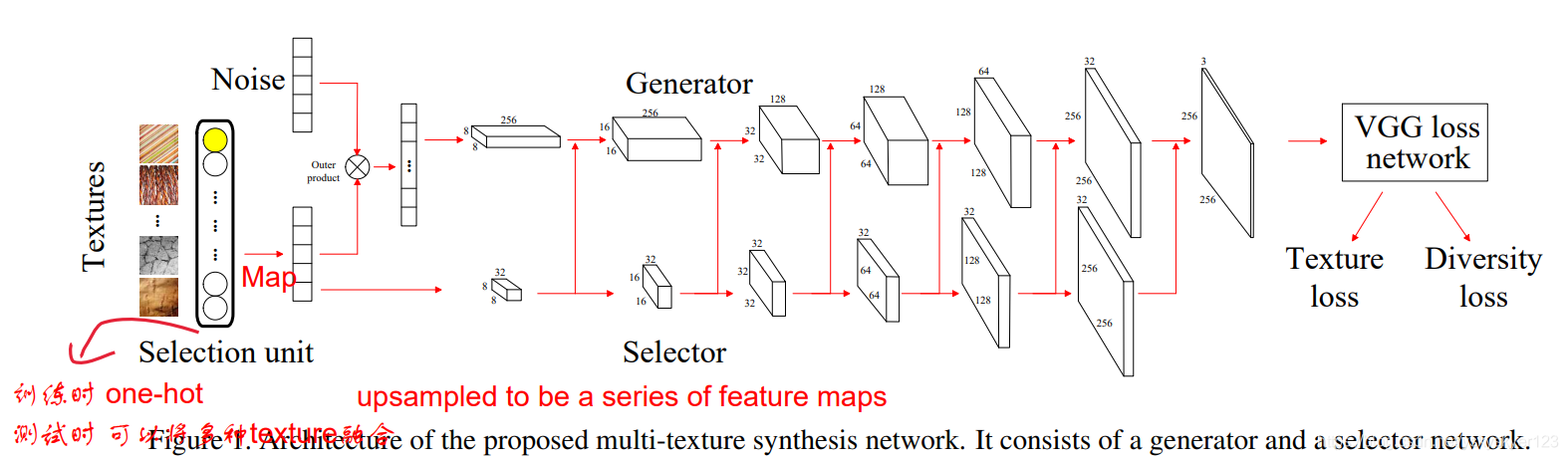
用one-hot selction unit来表示纹理。之后将将这个one-hot selection unit 映射到一个低维、连续的embedding vector。
noise vector负责产生噪声,用noise vector和embedding vector进行外积,得到一个矩阵,然后用
1
×
1
1\times 1
1×1的卷积去得到多个channel的tensor。最终再通过一系列的upsample和卷积去得到
256
×
256
×
3
256\times 256 \times 3
256×256×3的图像输出。这一流程称为Generator Stream, 除此之外下方还有一个Selector Stream, embedding vector通过不断的upsample得到一系列不同尺度的feature map。
这些feature map和Generator Stream中的特征进行融合 用来指导的图像生成。
(PS: 外积的概念,来自Wikipedia )
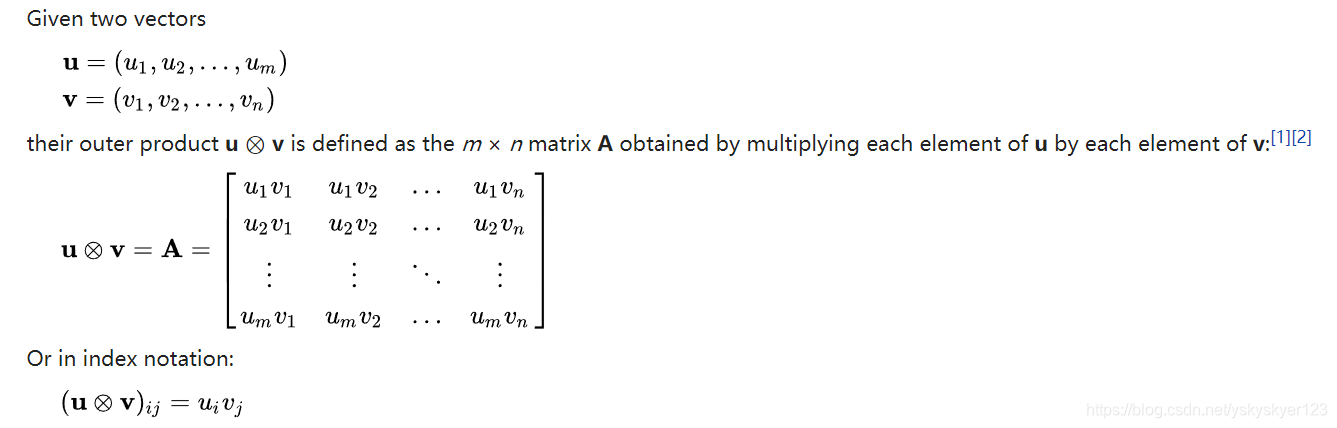
最终生成的图像被送到一个预训练好的固定VGG网络,通过VGG网络不同层提取到的特征计算统计量,并去和目标纹理的统计量进行匹配。
(Parametric methods [17, 27] for texture synthesis aim
to represent textures through proper statistical models, with
the assumption that two images can be visually similar
when certain image statistics match well [20].)
Loss Function
使用texture loss和diversity loss。
Texture Loss
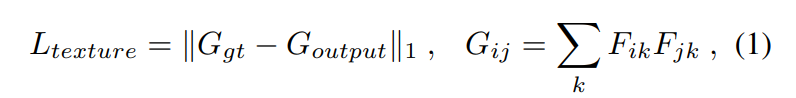
其中G代表Gram 矩阵。
We use the activations at the conv1_1, conv2_1, conv3_1, conv4_1 and conv5_1 layer of the VGG model.
However,文章发现直接使用Gram矩阵生成的图像效果并不好: 生成的纹理存在明显的artifacts和颜色混合问题。 他们将这种问题归结于不同材质Gram矩阵大小上的差异。
并提出了如下修改后的loss:
也就是对特征减去均值(进行中心化)后再来求偏心协方差矩阵。
这个均值是指某个layer中所有激活值的均值,即包含所有channel的Tensor的均值。
(Gram矩阵反应的是不同channel之间关联程度)
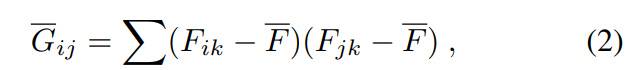
观察发现用减去均值之后的feature来求Gram矩阵的生成效果明显更好。
不减去均值生成图片中会有artifacts出现。
没有中心化时,使用不同风格图片指导风格化时loss和梯度会发生剧烈变化。文章认为这样网络会去学习深度特征的规模,而不是去区分不同纹理图像的差异。

Diversity loss.
目前的前馈方法很容易得到一个退化的解法: 不同的输入得到一个近似相同的输出(有时候会表现为一个较差的模式并在输出图像中重复出现)。
文章认为这种结果的出现是因为训练时只用texture loss去让输出图像的style和目标图像保持一致,但并没有提出输出具有多样性的要求。换句话说,每个输出的结果和网络输入部分的噪声并没有关联起来。
为了解决这个问题,文章提出了diversity loss,要求对于同一种输入不同噪声的情况下,输出图像尽可能不同:

具体参数说明:

其中
Φ
\Phi
Φ用代表VGG网络conv4_2层提取到的特征,Q相当于对排列P进行了一次shuffle。这个loss每个batch求一次。
由于要求下面这个式子尽可能大,所以在训练时 L d i v e r s i t y L_diversity Ldiversity前面会有一个负系数。

Final loss function

其中 α = 1 , β = − 1 \alpha=1,\beta=-1 α=1,β=−1。
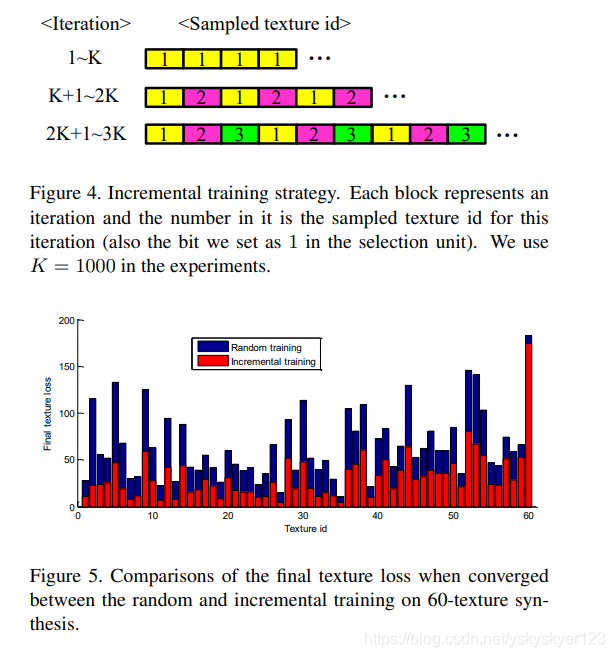
Incremental training
增量式学习
对于每次训练时,选中的训练样本在selection unit中对应的bit为1,其它bits为0。
(Once a target texture is selected, we set the corresponding bit in the
selection unit as 1 and the corresponding texture is used to
compute the texture loss.)
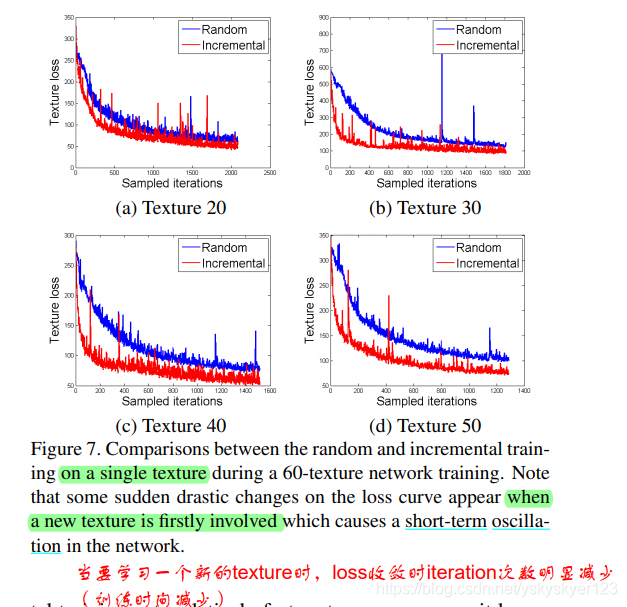
文章通过实验论证了增量式的训练方式较随机抽取样本的方式进行训练有更好的效果。
随机抽取样本进行训练出现的问题:
虽然,对于在某个iteration中随机抽取到的样本的学习效果有所提升,这种提升在之后的iterations中容易被限制住,之后的iterations往往会去优化其它样本的学习效果。 总之,学习效果不佳,并且最后学习到一个局部最优点。
增量学习方法:1) 学好一个任务之后(收敛后),再去学习新的任务。
2) 并且在学习新任务的时候时常复习之前学习的任务,以保证网络不遗忘/记住如何去生成旧的目标图像。
具体来说,前K个iteration,将selection unit的第1个bit设置为1(去学习第一个纹理)。
在接下来的K个iteration中,交替学习第1个和第2个纹理。依次列推…
在所有纹理都被学习之后,训练的样本使用随机采样的方法直到收敛。
实验结果证明了增量式学习比随机抽取样本学习效果好。

有趣的是,文章发现当网络学习到的纹理足够多时,再去学习一种新的纹理时速度会变快(收敛所需的iteration次数降低)
Experimental Results
Multi-texture synthesis

Diversity

与其它方法相比,文章提出方法的diversity更强,这是因为显示地提出了diversity loss。虽然[32] 通过注入不同尺度的噪声来增强diversity。但没有显示地限制条件去要求具有多样性,这样注入噪声后较大的变化/差异,可能会被减少或是被网络吸收,这样仍然会使输出的多样性有限。
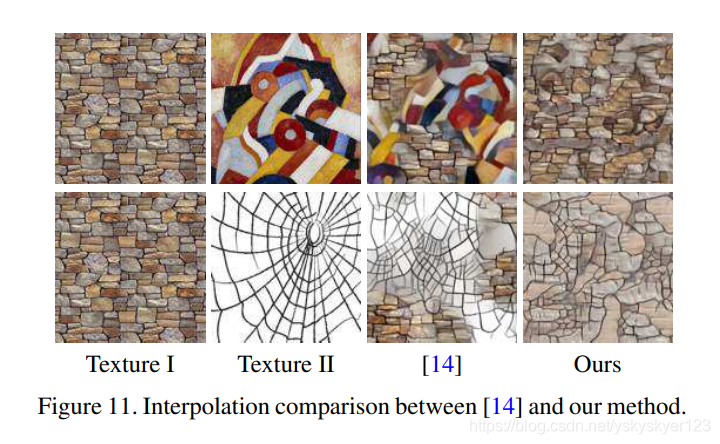
Interpolation
插值的目的主要是创造新的纹理,即通过生成大量样本,再通过对这些样本插值来创造新的纹理。

上图中第一行为纹理20到纹理19的插值图像。这通过逐渐减少selection unit中第20bit的权值,并且逐渐增加selection unit中第19bit的权值,同时保持其它bit为0来实现。
其它方法 [14]通过对Gram矩阵进行插值来实现。

Extension to multi-style transfer (拓展到风格迁移)
风格迁移:
全局内容保持不变,风格和局部结构发生变化。
Given a style image and a content image, image stylization aims at synthesizing an image that preserves the global content while transferring the colors and local structures from the style image。
结构:
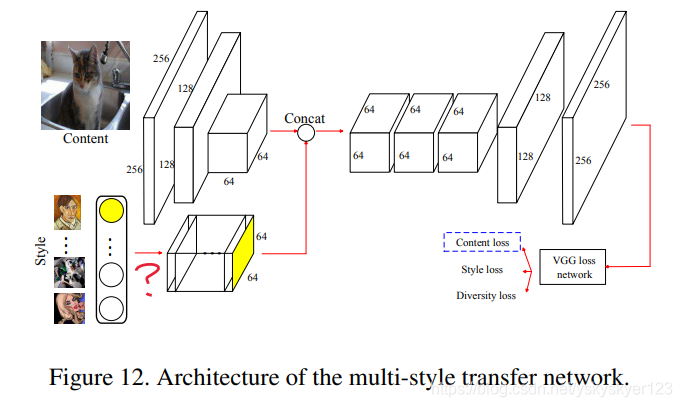
当选择一种风格时,noise map对应bit上的值随机初始化,其它bit上的值为0。
注意此时应该仍然有selction unit,感觉上图有所省略。(selection unit中这种风格对应的bit应该为1,其它bit应该为0。)
Fig. 12中上方用一个Encoder对图像进行提取特征。
之后生成的图像用VGG提取特征并施加三种loss:style和diversity loss和之前介绍的texture loss和diverstiy loss相同。
content loss 计算用VGG conv4_2层分别对生成图像和输出图像提取出特征的差异。
The content loss is computed as the feature differences between the
transferred result and the content at the conv4_2 layer of the
VGG model as in [14].


风格插值:


多样性:

不同于纹理生成:由于保留内容信息 (content) 的限制,图像的全局结构会保持不变。
所以,diversity被表现在局部视觉结构。注意上图中不同结果之间轻微但有意义的差异/变化。
Discussion
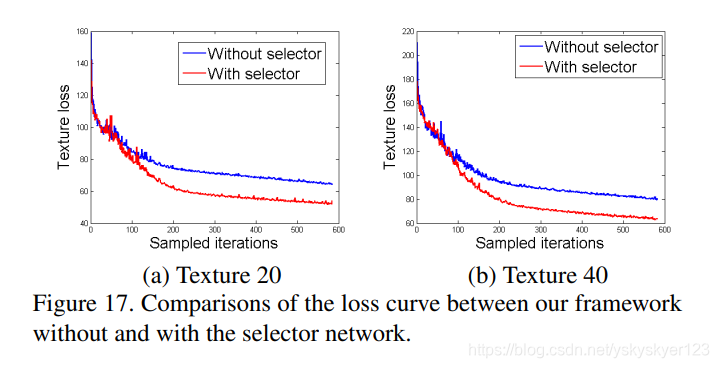
Selector network
The selector injects guidance to the generator at every upsampling scale and
helps the model distinguish different textures better during the synthesis.
选择器的作用:
Embedding
将selection unit映射到一个低维的embedding中,实验证明这样仍然可以区分不同的纹理用于生成,这证明了one-hot 表示是冗余的。
Conclusion
In order to train a deep network for multi-texture synthesis, we introduce the
diversity loss and propose an incremental leaning scheme.

















 2246
2246

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









