



TopN分析是指在研究对象中按照某一个指标进行倒序或者是正序排序,取其中最大的N个数据,并对这N 个数据以倒序或者是正序的方式进行数据分析的方法
案例实现
1.新建一个包topN
2. 新建三个类
TopNDriver
package org.topN;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.log4j.PropertyConfigurator;
import java.io.IOException;
public class TopNDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf=new Configuration();
Job job=Job.getInstance(conf);
job.setJarByClass(TopNDriver.class);
job.setMapperClass(TopNMapper.class);
job.setReducerClass(TopNReducer.class);
job.setNumReduceTasks(1);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(IntWritable.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
boolean res = job.waitForCompletion(true);
System.exit(res ? 0 : 1);
}
}
TopNMapper
package org.topN;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.TreeMap;
//输入 10 4 58 1 3 6 34
//输入<0,‘10 4 58 1 3 6 34">
//输入<null,58><null,10><null,6><null,4>
public class TopNMapper extends Mapper<LongWritable, Text, NullWritable,IntWritable> {
private final TreeMap<Integer, String> treeMap = new TreeMap<Integer, String>();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, NullWritable, IntWritable>.Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] nums = line.split("");//{"10","4","58","1","3","6","34"}
for (String num : nums) {
treeMap.put(Integer.parseInt(num),"");//{<10,"">,<4,"">,<58,"">....
if (treeMap.size() > 5) {
treeMap.remove(treeMap.firstKey());
}
}
}
@Override
protected void cleanup(Mapper<LongWritable, Text, NullWritable, IntWritable>.Context context) throws IOException, InterruptedException {
for (Integer i : treeMap.keySet()) {
context.write(NullWritable.get(), new IntWritable(i));
}
}
}
TopNReducer
package org.topN;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.Comparator;
import java.util.TreeMap;
public class TopNReducer extends Reducer<NullWritable, IntWritable,NullWritable,IntWritable> {
private TreeMap<Integer,String>treeMap=new TreeMap<Integer,String>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2-o1;
}
});
@Override
protected void reduce(NullWritable key, Iterable<IntWritable> values, Reducer<NullWritable, IntWritable, NullWritable, IntWritable>.Context context) throws IOException, InterruptedException {
for(IntWritable value:values){
treeMap.put(value.get(),"");
if (treeMap.size() > 5) {
treeMap.remove(treeMap.firstKey());
}
}
for(Integer i: treeMap.keySet()){
context.write(NullWritable.get(),new IntWritable(i));
}
}
}
3.上传
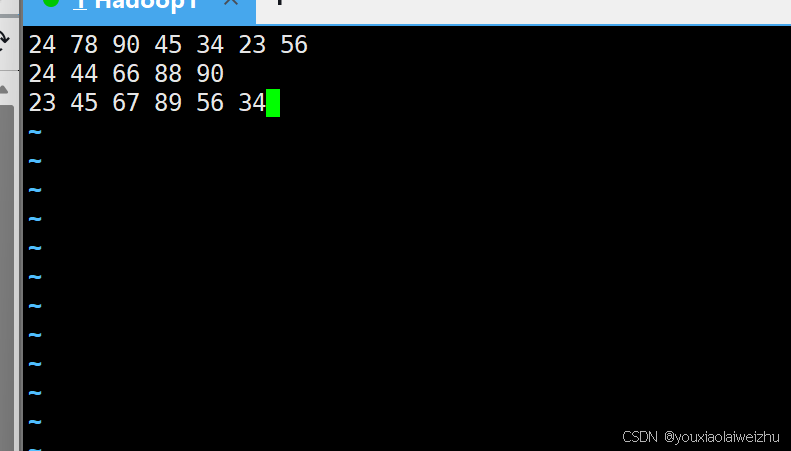
4.测试
vi de.txt
hdfs dfs -mkdir /ca
hdfs dfs -mkdir /de
hdfs dfs -put a.txt /ca
hadoop jar HadoopDemo-1.0-SNAPSHOT.jar org.topN.TopNDriver /ca /de/output1
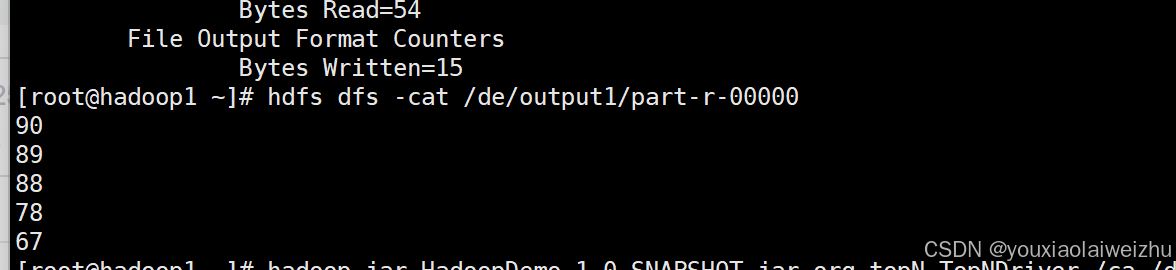
5.检查结果

















 7395
7395

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









