



1.创建一个新包,三个java类
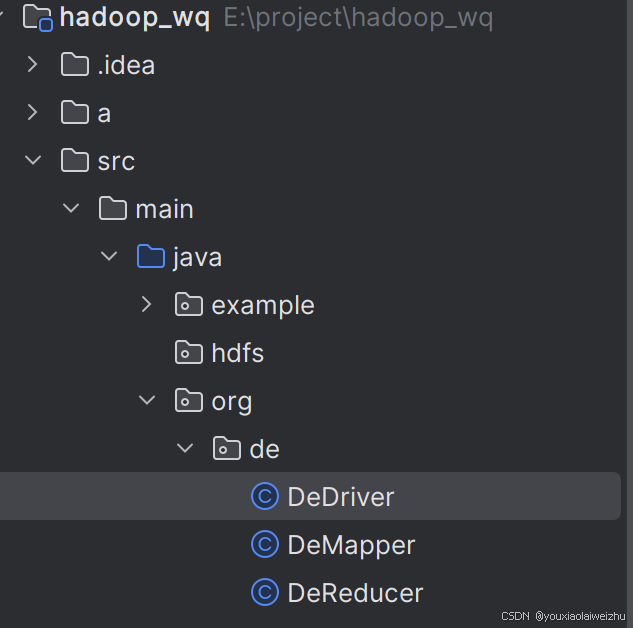
DeMapper
package org.de;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
//a.txt
//this
//this is hadoop
//输入<0,"this"><5,this is hadoop>
//输出<this,null><"this is hadoop",null>
public class DeMapper extends Mapper<LongWritable, Text,Text, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {
context.write(value,NullWritable.get());
}
}
DeReducer
package org.de;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
//输入:<"this",null>
//输出:<“this,null>
public class DeReducer extends Reducer<Text, NullWritable,Text,NullWritable> {
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Reducer<Text, NullWritable, Text, NullWritable>.Context context) throws IOException, InterruptedException {
context.write(key,NullWritable.get());
}
}
DeDriver
package org.de;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
//hadoop jar ****.jar org.de.DeDriver /de/input /output
public class DeDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(DeDriver.class);//设置驱动类
job.setMapperClass(DeMapper.class);//设置Mapper类
job.setReducerClass(DeReducer.class);//设置Reducer类
job.setOutputKeyClass(Text.class);//设置输出的键的类型
job.setOutputValueClass(NullWritable.class);//设置输出的值的类型
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
boolean res = job.waitForCompletion(true);
System.exit(res ? 0 : 1);
}
}2.打包
3.上传
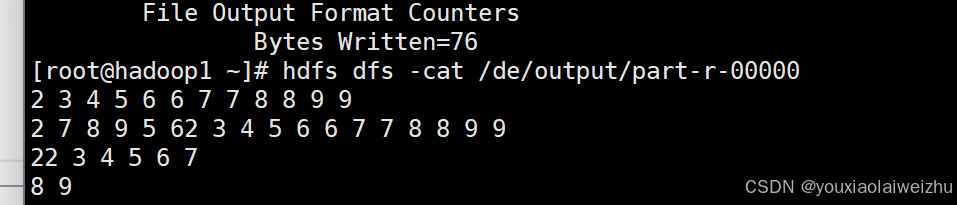
 4.准备测试文件,上传,调用
4.准备测试文件,上传,调用
vi a.txt
hdfs dfs -mkdir /de
hdfs dfs -put a.txt /de
hadoop jar HadoopDemo-1.0-SNAPSHOT.jar org.de.DeDriver /de /de/output
5.检查结果

















 1671
1671

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









