



倒排索引主要用来存储某个单词或者词组在一组文档中的存储位置的映射,提供了可以根据内容查找文档的方式,而不是根据文档确定内容。建立倒排索引的目的是更加方便的进行搜索
1.新建ii包和四个java类
package org.ii;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
//输入:<"MapReduce:file1.txt",1>
//输出:<"MapReduce","file1.txt:1">
public class InvertedIndexCombiner extends Reducer <Text, Text, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException {
int sum = 0;
for (Text i:values){
sum += Integer.parseInt(i.toString());
}
int index = key.toString().indexOf(":");
Text keyInfo = new Text();
Text valueInfo = new Text();
keyInfo.set(key.toString().substring(0,index));//"MapReduce"
valueInfo.set(key.toString().substring(index+1)+":"+ sum);
context.write(keyInfo,valueInfo);
}
}
package org.ii;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class InvertedIndexDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(InvertedIndexDriver.class);
job.setMapperClass(InvertedIndexMapper.class);
job.setCombinerClass(InvertedIndexCombiner.class);
job.setReducerClass(InvertedIndexReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
boolean res = job.waitForCompletion(true);
System.exit(res ? 0:1);
}
}
package org.ii;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
public class InvertedIndexMapper extends Mapper<LongWritable, Text,Text, Text> {
private static Text keyInfo =new Text();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context) throws IOException, InterruptedException {
String line =value.toString();
String[] word =line.split("");
FileSplit fileSplit=(FileSplit) context.getInputSplit();
String filename=fileSplit.getPath().getName();
for(String w:word){
keyInfo.set(w+":"+filename);//"MapReduce:file.txt"
context.write(keyInfo,new Text("1"));
}
}
}
package org.ii;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
//输入:<"MapReduce","file1.txt:1"><"MapReduce","file2.txt:1"><"MapReduce","file3.txt:1">
//输出:<"MapReduce","file1.txt:1;file2.txt:1;file3.txt:1">
public class InvertedIndexReducer extends Reducer<Text, Text,Text,Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException {
String fileList = new String();
for (Text value:values){
fileList += value.toString() +";";
}
context.write(key,new Text(fileList));
}
}
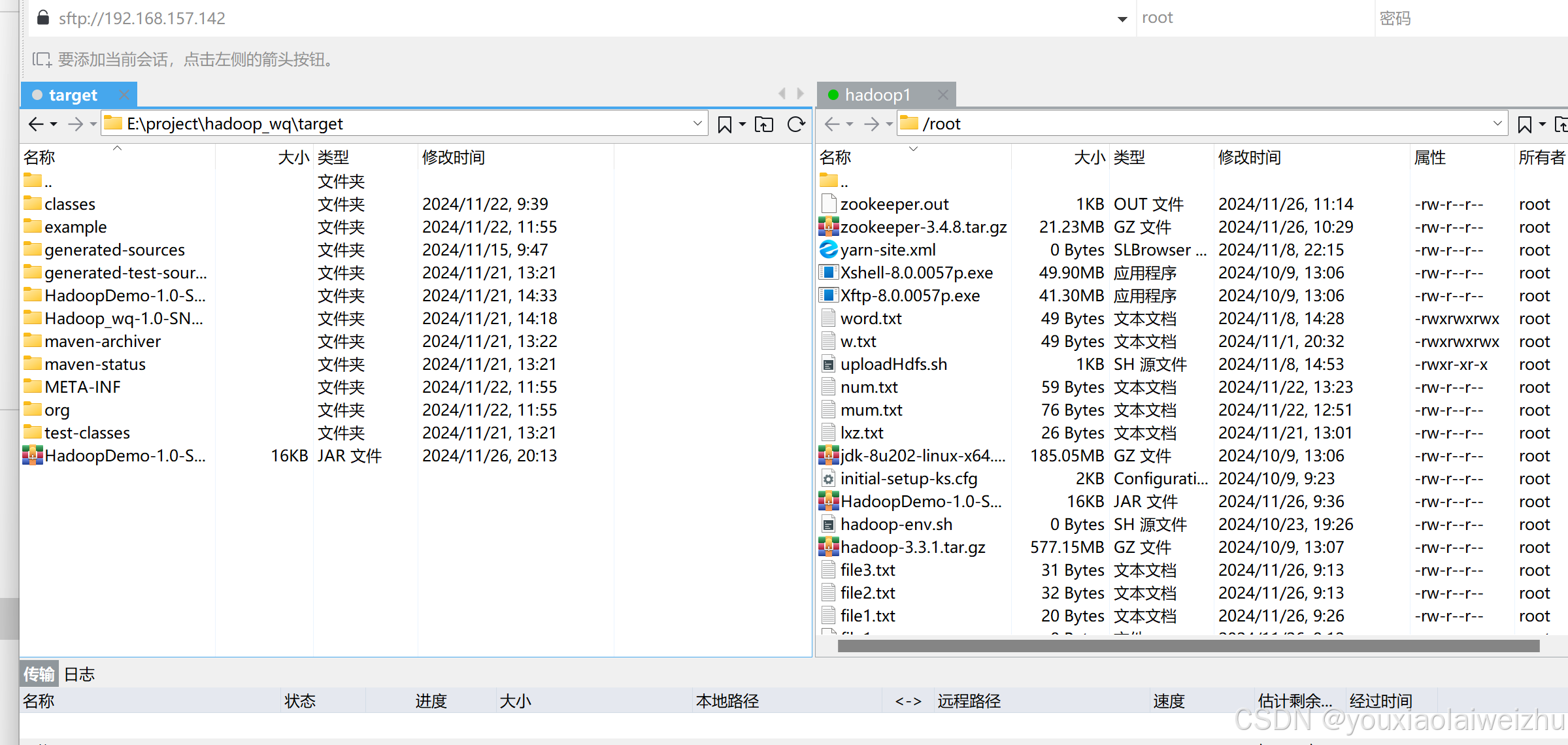
3.打包上传
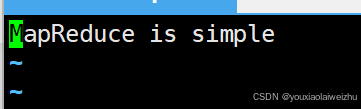
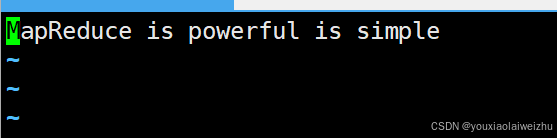
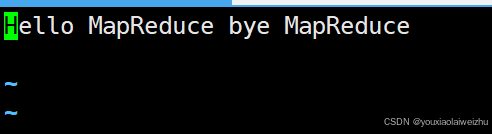
5.测试 新建三个文本文档
vi file1.txt
vi file2.txt
vi file3.txt
hdfs dfs -mkdir /invertIndex
hdfs dfs -mkdir /invertIndex/input
hdfs dfs -put file1.txt /invertIndex/input
hdfs dfs -put file2.txt /invertIndex/input
hdfs dfs -put file3.txt /invertIndex/input
hadoop jar HadoopDemo-1.0-SNAPSHOT.jar org.ii.InvertedIndexDriver /invertIndex/input /invertIndex/output
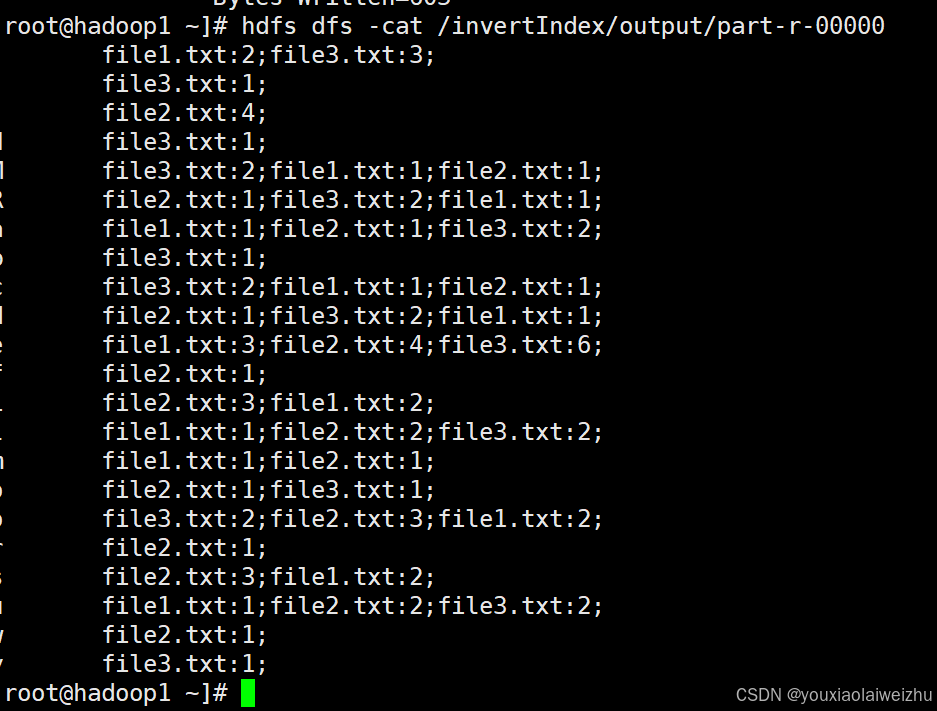
6.查看结果

















 3181
3181

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









