



本文详解如何用MindsDB构建企业级RAG知识库,解决数据孤岛问题。通过统一SQL界面整合多源数据,实现实时同步和语义检索,提供从架构设计到部署实施的完整指南。相比传统方案,MindsDB具有成本低、实时性强、易于扩展等优势,助力企业实现知识资产的高效管理与智能应用。
这就是数据孤岛时代的企业现实:你的知识资产明明就在那里,却在最需要的时候"消失不见"。当IBM的数据中台方案报价单让你倒吸一口冷气,当传统的ETL同步频率追不上业务实时需求,一个更优雅的解决方案正在悄然改变游戏规则——今天,让我们揭开用MindsDB构建生产级RAG知识库的奥秘。
一、企业级RAG的现实困境
**第一个挑战:**数据源过于分散
- 技术文档在飞书和企业网盘
- 生产数据在MES和ERP系统
- 客户反馈在CRM和工单系统
- 内部沟通记录在钉钉和企业微信
- 培训资料在学习管理系统
**第二个挑战:**实时同步困难,传统的数据集成方案要么成本高昂(比如请IBM做数据中台),要么时效性差(每天晚上ETL一次),根本满足不了业务部门"随时获取最新信息"的需求。
而MindsDB恰恰是为解决这些痛点而生的开源方案。它将知识库重新定义为一种"高级AI数据表",彻底突破了传统关键词匹配的局限性。
二、MindsDB:重新定义企业知识库架构
MindsDB提供了一个创新的解决思路:将知识库作为AI数据表来管理。这不仅仅是技术实现上的优化,更是架构思维的转变:
- AI数据表范式:将非结构化数据转化为可SQL查询的虚拟表(CREATE KNOWLEDGE_BASE),实现传统数据库与AI的无缝融合
- 动态数据管道:通过CREATE JOB实现分钟级增量同步,破解ETL延迟困局
- 混合检索架构:向量搜索+重排序模型+LLM生成的黄金三角(代码示例中的rag_pipeline)
1、核心架构原理
MindsDB的知识库系统基于三层架构设计:
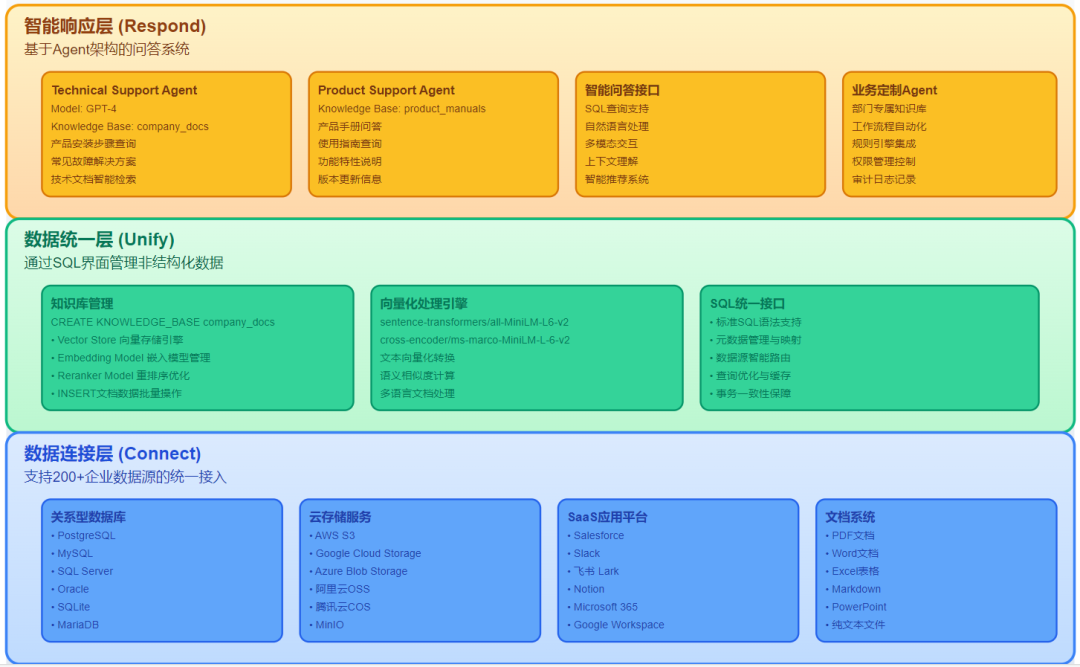
-
数据连接层(Connect) 支持200+企业数据源的统一接入,包括:
-
关系型数据库:PostgreSQL、MySQL、SQL Server等
-
云存储:AWS S3、Google Cloud Storage、Azure Blob等
-
SaaS应用:Salesforce、Slack、飞书、Notion等
-
文档系统:PDF、Word、Excel、Markdown等
-
数据统一层(Unify) 通过SQL界面管理非结构化数据
-- 创建知识库
CREATE KNOWLEDGE_BASE company_docs
USING ENGINE = 'rag'
WITH
STORAGE = vector_store,
EMBEDDING_MODEL = 'sentence-transformers/all-MiniLM-L6-v2',
RERANKER_MODEL = 'cross-encoder/ms-marco-MiniLM-L-6-v2';
-- 插入文档数据
INSERT INTO company_docs (content, metadata)
SELECT document_text, {'source': 'sharepoint', 'department': 'engineering'}
FROM sharepoint_integration.documents
WHERE last_modified > '2024-01-01';
- 智能响应层(Respond) 基于Agent架构的问答系统:
-- 创建专业领域Agent
CREATE AGENT technical_support
USING model = 'gpt-4',
knowledge_base = ['company_docs', 'product_manuals'];
-- 查询示例
SELECT answer
FROM technical_support
WHERE question = '产品X的安装步骤和常见故障解决方案是什么?';
**2、**MindsDB业务流程
因为传统数据库所有操作都在一个系统中完成,而MindsDB需要:
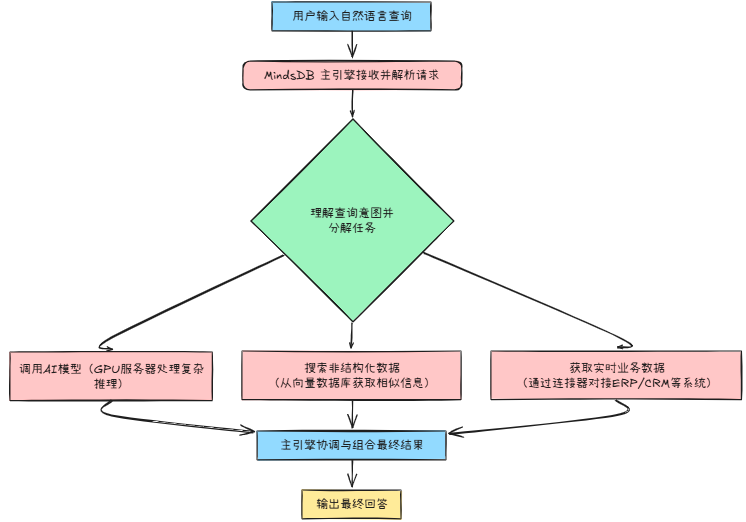
- 理解自然语言 → 调用AI模型(GPU服务器)
- 搜索非结构化数据 → 向量数据库
- 获取实时业务数据 → 对接ERP/CRM等系统
- 组合最终结果 → 主引擎协调
3、关键技术特性深入解析
语义检索vs关键词搜索
传统搜索依赖精确匹配:
用户查询:“如何提高生产效率”
传统结果:只返回包含"生产效率"字样的文档
MindsDB的语义检索:
用户查询:“如何提高生产效率”
智能理解:关联"产能优化"、“工艺改进”、"设备维护"等相关概念
综合返回:工艺优化指南+设备维护手册+生产数据分析报告
重排序模型的作用
检索到候选文档后,重排序模型会根据查询相关性重新排序:
# 内部工作流程示例
def rag_pipeline(query, knowledge_base):
# 1. 向量检索(召回阶段)
candidates = embedding_search(query, top_k=100)
# 2. 重排序(精排阶段)
reranked = reranker_model.rank(query, candidates, top_k=10)
# 3. 生成回答
context = '\n'.join([doc.content for doc in reranked])
answer = llm.generate(query, context)
return answer
三、执行全流程拆解(用统一SQL界面集成异构系统)
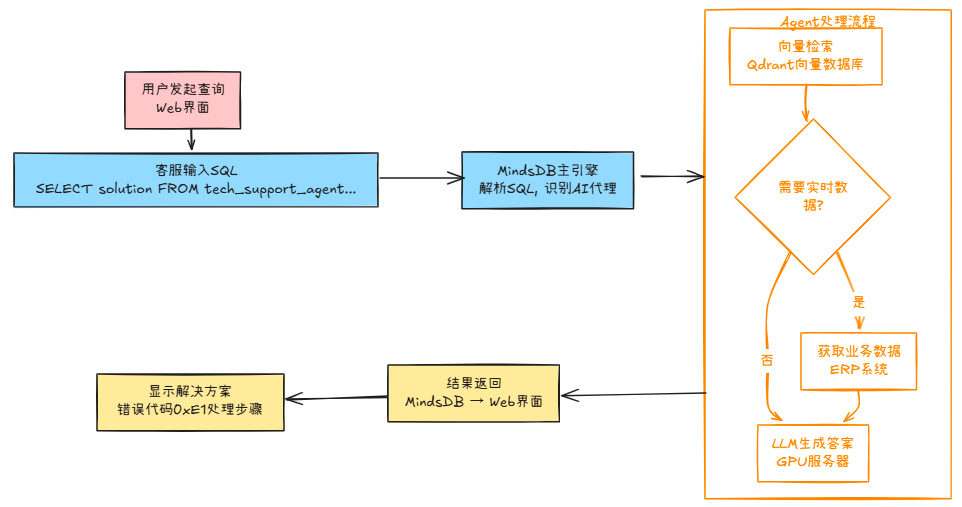
1、用户发起查询(Web界面)
客服人员输入 “客户反映设备报错代码0xE1如何处理?”
-- 客服在MindsDB控制台输入
SELECT solution
FROM tech_support_agent
WHERE question = '设备报错代码0xE1';
2、MindsDB主引擎(大脑)
位置:mindsdb-server:47334
作用:
-
解析SQL语句
-
识别
tech_support_agent是AI代理 -
执行动作:
# 伪代码:MindsDB内部处理流程 def execute_query(sql): if "FROM agent" in sql: question = extract_question(sql) return call_agent("tech_support_agent", question)
3、Agent调用向量检索(智能搜索)
位置:向量数据库(如Qdrant)
作用:
-
将自然语言问题转换为数学向量
-
在知识库中查找相似文档
-
实际执行位置:
# Qdrant服务内部执行 curl http://qdrant:6333/collections/tech_kb/points/search \ -H "Content-Type: application/json" \ -d '{"vector": [0.12, -0.45, ...], "limit": 5}'
4、获取业务数据(真实系统)
位置:原始业务系统
作用:
-
当需要补充实时数据时访问真实系统
-
示例:
-- MindsDB自动生成并下推到ERP系统 SELECT error_code, solution FROM equipment_error_codes -- 真实ERP中的表 WHERE code = '0xE1'
5、LLM生成最终答案(AI推理)
位置:GPU服务器/云API
作用:
-
组合检索结果生成自然语言回答
-
实际执行:
# 在GPU服务器上运行的LLM服务 def generate_answer(question, context): return qwen_model.predict( f"基于以下信息回答问题:{context}\n问题:{question}" )
6、结果返回用户
路径:
GPU服务器 → MindsDB → Web界面
最终客服看到:
“错误代码0xE1表示电机过热,请执行以下操作:
立即停机冷却
检查散热风扇(参考手册第5章)
若持续报警联系工程师”
四、企业级实战部署指南
1、快速启动方案
Docker一键部署
# 创建工作目录
mkdir mindsdb-enterprise && cd mindsdb-enterprise
# 下载配置文件
curl -o docker-compose.yml https://raw.githubusercontent.com/mindsdb/mindsdb/main/docker-compose.yml
# 启动完整服务栈
docker-compose up -d
# 验证服务状态
curl http://localhost:47334/api/status
配置持久化存储
# docker-compose.yml 关键配置
version: '3.8'
services:
mindsdb:
image: mindsdb/mindsdb:latest
ports:
- "47334:47334"
volumes:
- ./data:/opt/mindsdb/var
- ./config:/opt/mindsdb/etc
environment:
- MINDSDB_STORAGE_PATH=/opt/mindsdb/var
- MINDSDB_CONFIG_PATH=/opt/mindsdb/etc/config.json
2、生产环境优化配置
向量存储选择
-- 使用Qdrant作为向量数据库
CREATE DATABASE vector_db
WITH ENGINE = 'qdrant',
PARAMETERS = {
'host': 'qdrant-server',
'port': 6333,
'collection_config': {
'distance': 'Cosine',
'vector_size': 384
}
};
嵌入模型配置
-- 配置多语言嵌入模型
CREATE ML_ENGINE multilingual_embeddings
FROM sentence_transformers
USING
model_name = 'paraphrase-multilingual-MiniLM-L12-v2',
device = 'cuda:0', -- 使用GPU加速
batch_size = 32;
五、实际应用场景与解决方案
场景1:技术支持自动化
问题描述:客服团队每天处理大量重复技术咨询,需要在多个系统中查找解决方案
MindsDB解决方案:
-- 整合多源技术文档
CREATE KNOWLEDGE_BASE tech_support_kb
SELECT content, metadata FROM (
SELECT manual_text as content,
{'type': 'manual', 'product': product_name} as metadata
FROM product_manuals
UNION ALL
SELECT ticket_solution as content,
{'type': 'solution', 'category': issue_category} as metadata
FROM support_tickets
WHERE status = 'resolved'
UNION ALL
SELECT faq_answer as content,
{'type': 'faq', 'priority': 'high'} as metadata
FROM knowledge_base_faq
);
-- 创建技术支持Agent
CREATE AGENT tech_support_bot
USING
model = 'gpt-4',
knowledge_base = ['tech_support_kb'],
prompt_template = '''
你是一名专业的技术支持工程师。基于以下技术文档回答用户问题:
{{context}}
用户问题:{{question}}
请提供详细的解决步骤,如果涉及多个产品请分别说明。
''';
场景2:合规文档管理
问题描述:制药企业需要快速查找FDA法规要求和内部SOP文档
实施代码:
-- 建立合规知识库
CREATE KNOWLEDGE_BASE compliance_kb
WITH
STORAGE = vector_db,
EMBEDDING_MODEL = 'legal_bert', -- 法律领域专用模型
CHUNK_SIZE = 512, -- 适合法规文档的分块大小
OVERLAP = 50; -- 重叠区域保持上下文
-- 定时同步法规更新
CREATE JOB sync_regulations
REPEAT EVERY 1 DAY
AS (
INSERT INTO compliance_kb (content, metadata)
SELECT regulation_text,
{'source': 'fda', 'effective_date': effective_date, 'category': category}
FROM fda_regulations_api.latest_updates
WHERE last_updated > LAST_SYNC_TIME
);
-- 创建合规查询Agent
CREATE AGENT compliance_advisor
USING
model = 'gpt-4',
knowledge_base = ['compliance_kb'],
prompt_template = '''
作为合规专家,请基于最新法规要求回答问题。
如果涉及法规变更,请标注生效日期。
相关法规:{{context}}
查询:{{question}}
''';
场景3:实时数据分析
业务需求:销售团队需要结合CRM数据、市场分析报告和产品文档来制定客户方案
技术实现:
-- 创建实时数据视图
CREATE VIEW customer_360 AS
SELECT
c.customer_name,
c.industry,
c.annual_revenue,
s.deal_stage,
s.pain_points,
p.product_fit_score
FROM salesforce.customers c
JOIN salesforce.opportunities s ON c.id = s.customer_id
JOIN product_analysis.fit_scores p ON c.id = p.customer_id;
-- 整合销售知识库
CREATE KNOWLEDGE_BASE sales_intelligence
SELECT
CONCAT('客户:', customer_name,
',行业:', industry,
',痛点:', pain_points) as content,
{'type': 'customer_profile', 'stage': deal_stage} as metadata
FROM customer_360
WHERE deal_stage IN ('qualification', 'proposal', 'negotiation');
-- 创建销售助手
CREATE AGENT sales_assistant
USING
model = 'gpt-4',
knowledge_base = ['sales_intelligence', 'product_specs'],
skills = ['data_analysis', 'proposal_generation'];
六、性能优化与最佳实践
1、检索性能调优
分块策略优化:
-- 根据文档类型调整分块参数
ALTER KNOWLEDGE_BASE product_docs
SET
CHUNK_SIZE = CASE
WHEN metadata->>'type' = 'manual' THEN 1024 -- 手册类文档用大分块
WHEN metadata->>'type' = 'faq' THEN 256 -- FAQ用小分块
ELSE 512
END,
OVERLAP = CHUNK_SIZE * 0.1; -- 重叠比例10%
向量索引优化:
# 在配置文件中设置索引参数
{
"vector_store": {
"index_type": "HNSW",
"m": 16, # 连接数,影响召回率
"ef_construction": 200, # 构建时的搜索范围
"ef": 100 # 查询时的搜索范围
}
}
2、实时同步策略
增量更新机制:
-- 设置智能同步作业
CREATE JOB smart_sync_docs
REPEAT EVERY 10 MINUTES
AS (
-- 仅处理变更的文档
WITH changed_docs AS (
SELECT doc_id, content, last_modified
FROM document_sources
WHERE last_modified > (
SELECT COALESCE(MAX(sync_time), '1970-01-01')
FROM sync_log
WHERE job_name = 'smart_sync_docs'
)
)
-- 删除旧版本
DELETE FROM company_kb
WHERE metadata->>'doc_id' IN (SELECT doc_id FROM changed_docs);
-- 插入新版本
INSERT INTO company_kb (content, metadata)
SELECT content,
JSON_OBJECT('doc_id', doc_id, 'sync_time', NOW())
FROM changed_docs;
-- 记录同步状态
INSERT INTO sync_log (job_name, sync_time, processed_count)
SELECT 'smart_sync_docs', NOW(), COUNT(*) FROM changed_docs;
);
七、企业级安全与权限管理
1、数据访问控制
-- 基于角色的知识库访问
CREATE ROLE sales_team;
CREATE ROLE engineering_team;
CREATE ROLE management_team;
-- 授权不同知识库访问权限
GRANT SELECT ON sales_kb TO sales_team;
GRANT SELECT ON tech_docs_kb TO engineering_team;
GRANT SELECT ON all_knowledge_bases TO management_team;
-- 创建带权限控制的Agent
CREATE AGENT secure_assistant
USING
model = 'gpt-4',
knowledge_base = ACCESSIBLE_KBS(), -- 动态获取可访问的知识库
access_control = 'rbac';
2、审计与监控
-- 启用查询审计日志
CREATE TABLE query_audit_log (
query_id UUID DEFAULT gen_random_uuid(),
user_id VARCHAR(50),
query_text TEXT,
knowledge_bases TEXT[],
query_time TIMESTAMP DEFAULT NOW(),
response_time_ms INTEGER,
result_count INTEGER
);
-- 创建审计触发器
CREATE TRIGGER audit_queries
AFTER EACH QUERY ON knowledge_bases
FOR EACH ROW EXECUTE FUNCTION log_query_audit();
八、MCP集成:连接外部AI生态
MindsDB内置的MCP(Model Context Protocol)服务器让它能够无缝集成到现有的AI工作流中:
# 通过MCP连接到Claude Desktop
import mcp_client
# 连接MindsDB MCP服务器
client = mcp_client.connect("http://localhost:47334/mcp")
# 在Claude Desktop中直接查询企业数据
response = client.query(
"分析Q4销售数据,找出表现最好的产品类别",
tools=["mindsdb_query", "data_analysis"]
)
配置MCP服务器:
{
"mcpServers": {
"mindsdb": {
"command": "npx",
"args": ["@mindsdb/mcp-server"],
"env": {
"MINDSDB_URL": "http://localhost:47334",
"MINDSDB_API_KEY": "your-api-key"
}
}
}
}
九、性能监控与故障排查
1、关键指标监控
-- 创建性能监控视图
CREATE VIEW rag_performance_metrics AS
SELECT
DATE_TRUNC('hour', query_time) as time_bucket,
COUNT(*) as query_count,
AVG(response_time_ms) as avg_response_time,
PERCENTILE_CONT(0.95) WITHIN GROUP (ORDER BY response_time_ms) as p95_response_time,
AVG(result_count) as avg_results_returned
FROM query_audit_log
GROUP BY DATE_TRUNC('hour', query_time)
ORDER BY time_bucket DESC;
-- 设置性能告警
CREATE ALERT slow_queries
WHEN avg_response_time > 5000 -- 5秒响应时间告警
OR p95_response_time > 10000 -- P95超过10秒告警
NOTIFY ['ops-team@company.com'];
2、常见问题诊断
检索质量问题:
-- 分析低相关性查询
SELECT
query_text,
COUNT(*) as frequency,
AVG(user_feedback_score) as avg_satisfaction
FROM query_audit_log q
JOIN user_feedback f ON q.query_id = f.query_id
WHERE f.feedback_score < 3 -- 低分查询
GROUP BY query_text
ORDER BY frequency DESC
LIMIT 10;
性能瓶颈分析:
-- 识别慢查询模式
SELECT
kb_name,
query_pattern,
COUNT(*) as occurrence,
AVG(response_time_ms) as avg_time
FROM (
SELECT
unnest(knowledge_bases) as kb_name,
CASE
WHEN length(query_text) > 200 THEN 'long_query'
WHEN query_text ~* '统计|分析|汇总' THEN 'analytics_query'
ELSE 'simple_query'
END as query_pattern,
response_time_ms
FROM query_audit_log
WHERE query_time > NOW() - INTERVAL '24 hours'
) patterns
GROUP BY kb_name, query_pattern
HAVING AVG(response_time_ms) > 2000
ORDER BY avg_time DESC;
十、成本优化策略
1、模型选择与资源配置
# 生产环境分层配置 - 2025年9月最新国产开源模型方案
embedding_models:
tier_1: # 高频查询使用轻量模型
model: "BAAI/bge-small-zh-v1.5" # 经久考验的轻量级Embedding模型,适合高频查询
batch_size: 64
cache_ttl: 3600
tier_2: # 复杂查询使用重型模型
model: "BAAI/bge-large-zh-v1.5" # 性能强大的大型Embedding模型,适合复杂语义表示
batch_size: 16
cache_ttl: 7200
generation_models:
primary: "Qwen/Qwen3-8B-Instruct" # 成本效益平衡: Qwen3-8B指令微调版,性能强劲,适合日常生成任务
fallback: "deepseek-ai/deepseek-llm-7B" # 高并发场景: 深度求索7B模型,以高效推理见长,高并发下稳定
premium: "Qwen/Qwen3-32B-Instruct" # 关键业务查询: Qwen3-32B指令微调模型,强大性能应对高要求场景
2、缓存策略优化
-- 配置智能缓存
CREATE CACHE POLICY intelligent_cache AS
CACHE QUERIES FOR 1 HOUR
WHERE similarity(current_query, cached_query) > 0.85
AND user_context.department = cached_context.department;
-- 预计算常见查询结果
CREATE MATERIALIZED VIEW frequent_queries AS
SELECT
query_embedding,
precomputed_answer,
last_updated
FROM popular_queries
WHERE query_frequency > 100; -- 高频查询预计算
十一、总结
通过这次深入解析,我们看到MindsDB不仅仅是一个技术工具,更是企业数字化转型的战略支撑。它解决了传统知识管理的三个核心痛点:
- 数据孤岛问题:通过统一的SQL界面管理异构数据源
- 实时同步挑战:基于JOB的自动化数据流处理
- 智能检索需求:语义理解+上下文感知的AI问答系统
RAG在成本和实时性能方面相比微调具有明显优势,这使得MindsDB成为企业级AI应用的理想选择。随着LLM响应速度提升7倍,基于RAG的知识库系统将在2025年迎来更广泛的企业应用。
关键成功因素包括:
- 渐进式部署:从单一数据源开始,逐步扩展到全域数据
- 持续优化:基于用户反馈调整检索和生成策略
- 安全合规:建立完善的访问控制和审计机制
大模型未来如何发展?普通人能从中受益吗?
在科技日新月异的今天,大模型已经展现出了令人瞩目的能力,从编写代码到医疗诊断,再到自动驾驶,它们的应用领域日益广泛。那么,未来大模型将如何发展?普通人又能从中获得哪些益处呢?
通用人工智能(AGI)的曙光:未来,我们可能会见证通用人工智能(AGI)的出现,这是一种能够像人类一样思考的超级模型。它们有可能帮助人类解决气候变化、癌症等全球性难题。这样的发展将极大地推动科技进步,改善人类生活。
个人专属大模型的崛起:想象一下,未来的某一天,每个人的手机里都可能拥有一个私人AI助手。这个助手了解你的喜好,记得你的日程,甚至能模仿你的语气写邮件、回微信。这样的个性化服务将使我们的生活变得更加便捷。
脑机接口与大模型的融合:脑机接口技术的发展,使得大模型与人类的思维直接连接成为可能。未来,你可能只需戴上头盔,心中想到写一篇工作总结”,大模型就能将文字直接投影到屏幕上,实现真正的心想事成。
大模型的多领域应用:大模型就像一个超级智能的多面手,在各个领域都展现出了巨大的潜力和价值。随着技术的不断发展,相信未来大模型还会给我们带来更多的惊喜。赶紧把这篇文章分享给身边的朋友,一起感受大模型的魅力吧!
那么,如何学习AI大模型?
在一线互联网企业工作十余年里,我指导过不少同行后辈,帮助他们得到了学习和成长。我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑。因此,我坚持整理和分享各种AI大模型资料,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频。
学习阶段包括:
1.大模型系统设计
从大模型系统设计入手,讲解大模型的主要方法。包括模型架构、训练过程、优化策略等,让读者对大模型有一个全面的认识。

2.大模型提示词工程
通过大模型提示词工程,从Prompts角度入手,更好发挥模型的作用。包括提示词的构造、优化、应用等,让读者学会如何更好地利用大模型。

3.大模型平台应用开发
借助阿里云PAI平台,构建电商领域虚拟试衣系统。从需求分析、方案设计、到具体实现,详细讲解如何利用大模型构建实际应用。

4.大模型知识库应用开发
以LangChain框架为例,构建物流行业咨询智能问答系统。包括知识库的构建、问答系统的设计、到实际应用,让读者了解如何利用大模型构建智能问答系统。

5.大模型微调开发
借助以大健康、新零售、新媒体领域,构建适合当前领域的大模型。包括微调的方法、技巧、到实际应用,让读者学会如何针对特定领域进行大模型的微调。



6.SD多模态大模型
以SD多模态大模型为主,搭建文生图小程序案例。从模型选择、到小程序的设计、到实际应用,让读者了解如何利用大模型构建多模态应用。

7.大模型平台应用与开发
通过星火大模型、文心大模型等成熟大模型,构建大模型行业应用。包括行业需求分析、方案设计、到实际应用,让读者了解如何利用大模型构建行业应用。


学成之后的收获👈
• 全栈工程实现能力:通过学习,你将掌握从前端到后端,从产品经理到设计,再到数据分析等一系列技能,实现全方位的技术提升。
• 解决实际项目需求:在大数据时代,企业和机构面临海量数据处理的需求。掌握大模型应用开发技能,将使你能够更准确地分析数据,更有效地做出决策,更好地应对各种实际项目挑战。
• AI应用开发实战技能:你将学习如何基于大模型和企业数据开发AI应用,包括理论掌握、GPU算力运用、硬件知识、LangChain开发框架应用,以及项目实战经验。此外,你还将学会如何进行Fine-tuning垂直训练大模型,包括数据准备、数据蒸馏和大模型部署等一站式技能。
• 提升编码能力:大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握将提升你的编码能力和分析能力,使你能够编写更高质量的代码。
学习资源📚
- AI大模型学习路线图:为你提供清晰的学习路径,助你系统地掌握AI大模型知识。
- 100套AI大模型商业化落地方案:学习如何将AI大模型技术应用于实际商业场景,实现技术的商业化价值。
- 100集大模型视频教程:通过视频教程,你将更直观地学习大模型的技术细节和应用方法。
- 200本大模型PDF书籍:丰富的书籍资源,供你深入阅读和研究,拓宽你的知识视野。
- LLM面试题合集:准备面试,了解大模型领域的常见问题,提升你的面试通过率。
- AI产品经理资源合集:为你提供AI产品经理的实用资源,帮助你更好地管理和推广AI产品。
👉获取方式: 😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】


















 1528
1528

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









