







25年9月来自字节 Seed 的论文“Robix: A Unified Model for Robot Interaction, Reasoning and Planning”。
Robix 是一个将机器人推理、任务规划和自然语言交互集成在单一视觉-语言架构中的统一模型。作为分层机器人系统中的高级认知层,Robix 可以动态地为低级控制器生成原子命令,并为人机交互生成口头响应,使机器人能够遵循复杂指令、规划长期任务,并在端到端框架内与人类进行自然交互。Robix 进一步引入新功能,例如主动对话、实时中断处理和在任务执行过程中感知上下文的常识推理。Robix 的核心是思维链推理,并采用三阶段训练策略:(1)持续的预训练以增强基础的具体推理能力,包括 3D 空间理解、视觉基础和以任务为中心的推理;(2)监督微调,将人机交互和任务规划建模为统一的推理-动作序列; (3)通过强化学习来提高推理-动作一致性和长期任务的连贯性。大量实验表明,Robix 在交互式任务执行方面的表现优于开源和商业基线(例如 GPT-4o 和 Gemini 2.5 Pro),并展示了对各种指令类型(例如开放式、多阶段、受限式、无效式和中断式)和各种用户参与任务(例如收拾餐桌、购物和饮食过滤)的强大泛化能力。
通用机器人的目标是在开放、动态的环境中协助人类完成各种日常任务。实现这一愿景需要的不仅仅是执行孤立的命令,还需要能够进行自然的人机交互,并推理处理复杂的、长期的任务。例如,在清洁餐桌时,机器人不仅要识别餐具,还要理解诸如“只有吃完饭才收拾盘子”之类的细微指令,响应诸如“把杯子留下”之类的纠正指令,并适应诸如正确整理堆叠餐具等新场景。为了满足这些要求,通用机器人系统应采用分层架构,其中高级认知层负责处理复杂的多模态推理、自适应任务规划和自然的人机交互,而低级控制器层则执行高级层发出的原子运动动作。这种职责划分使机器人能够在宏观层面进行推理,同时在微观层面采取行动,从而在现实场景中拥有类似人类的适应能力。
现有的分层方法通常采用大语言模型 (LLM) 或视觉-语言模型 (VLM) 作为任务规划的高级认知层,将长周期任务分解为低级控制器可执行的子任务 [1, 8, 17, 29, 53, 60, 84, 88]。然而,这些方法仅仅关注任务分解,忽略人机交互和具身推理,而这些对于通用机器人系统至关重要。更进一步,最近的研究 [11] 构建模块化流程,通过手工设计的工作流将推理、规划和交互结合在一起。虽然基于工作流的系统易于开发,但其缺乏灵活性和脆弱性仍然是显著的局限性——主要根源在于僵化的模块化和对手工设计的过度依赖。本研究的 Robix,是一个统一的高级认知层,它将推理、任务规划和自然语言交互无缝集成到一个模型中。与模块化框架不同,Robix 采用专为交互式任务执行而设计的端到端视觉-语言架构。Robix 的核心在于其思维链推理,将交互式任务执行构建为统一的推理-行动序列,有效地充当通用机器人系统的“大脑”。如图展示 Robix 在交互式表格整理任务中的灵活能力,例如理解复杂指令、处理实时中断、监控任务进度以及主动对话以澄清模糊命令或推断用户意图。

Robix 通过扎实的多维度推理,统一整个交互任务执行流程,包括指令理解、任务规划、任务状态监控、实时用户反馈集成、主动对话和动态重规划。与以往用于任务规划或人机交互的模块化框架不同,Robix 提供显著更高的灵活性,使机器人能够根据动态环境变化实时调整自身行为,从而实现类似人类的适应性。
在单个视觉-语言模型 (VLM) 中对如此复杂的交互式任务执行进行建模极具挑战性。尽管通用视觉-语言模型 (VLM) 在数字领域已经取得优异的表现,但将其扩展到物理机器人领域则要求更高:机器人必须在动态环境中持续感知和行动,解读模糊指令,适应实时反馈,并在严格的物理和时间约束下做出连续决策。要弥补这一差距,需要克服现有模型的两个主要局限性:(1)具身推理能力有限——将物体和空间概念在物理世界中扎根,并整合这些信号进行自适应规划和以任务为中心的推理的能力 [64];(2)缺乏灵活的多模态交互——这既受到其固有复杂性的阻碍,也受到相应训练数据匮乏的阻碍。
为了应对这些挑战,Robix 采用三阶段策略进行训练:
• 继续在通用 VLM 上进行预训练,以增强基础的具身推理能力。构建一个涵盖各种机器人相关任务的大规模数据集,例如 3D 空间理解、视觉落地和以任务为中心的推理,从而使模型能够增强其落地的规划和推理能力。
• 监督式微调,赋予模型复杂的交互能力。采用全面的数据合成技术,将思维链推理融入模型中,并将交互任务执行建模为统一的推理-动作序列。合成数据涵盖全方位的功能,包括复杂指令理解、长期规划、任务状态监控、动态重规划、实时中断处理以及人机对话。
• 强化学习,进一步完善推理能力,增强推理与动作之间的一致性,尤其是在长期交互任务中。
对 Robix 的具身推理和交互式任务执行能力进行全面评估。在涵盖机器人相关能力(3D 空间理解、视觉落地、任务中心推理)和通用技能(通用 VQA、多模态推理)的 31 个基准测试中,Robix 在大多数机器人相关任务上取得了显著提升,同时保持了强劲的通用性能。实验表明,Robix 将强大的具身推理与灵活的高级规划和交互相结合,正在向通用的具身智能迈进。
如图展示分层机器人系统,其中 Robix 充当负责规划和交互的高级认知层。低级控制器(通常采用视觉-语言-动作 (VLA) 模型)执行 Robix 生成的原子命令,使机器人系统能够直接与物理环境交互。
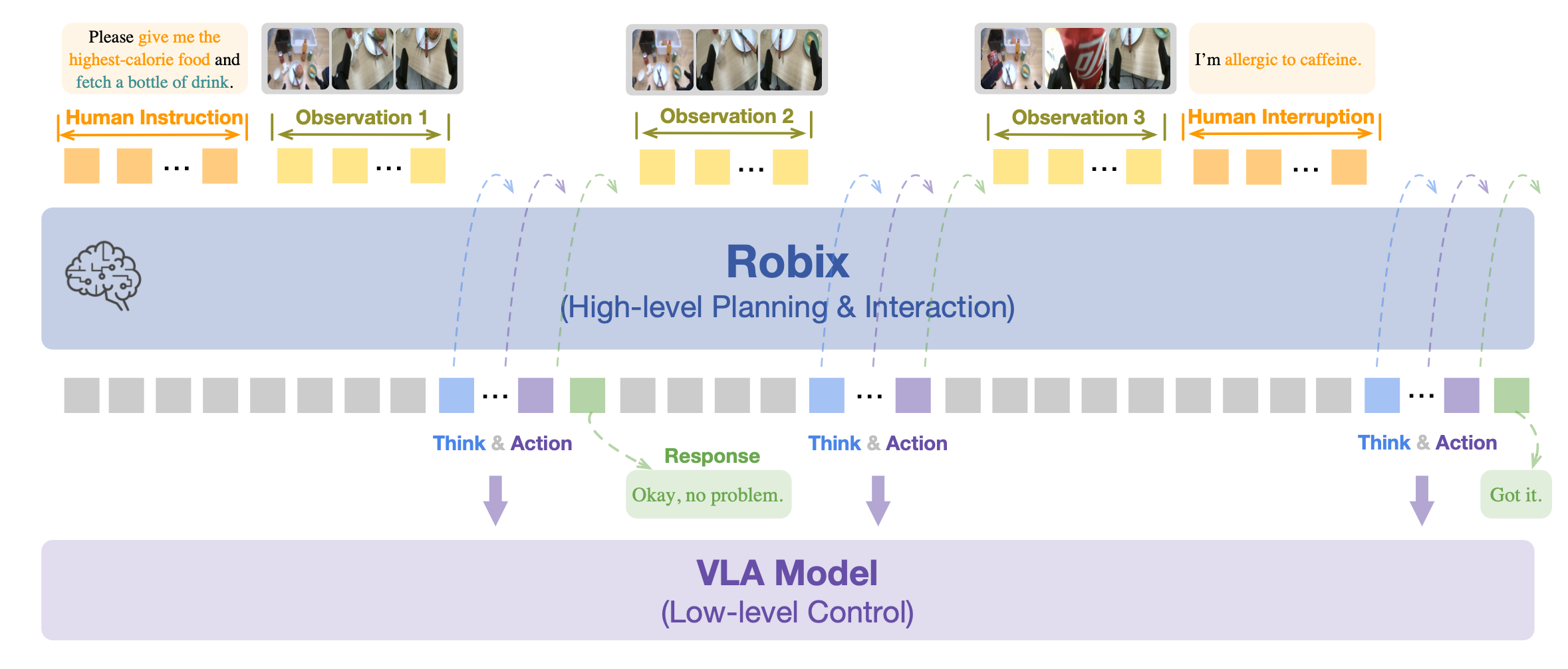
在每次迭代中,Robix 直接处理来自机器人摄像头的视觉观察和用户话语,选择性地为低级控制器生成原子动作命令和适当的口头响应。这种迭代的推理-动作循环使 Robix 能够进行深思熟虑的推理,并生成基于情境的行为。
在这里,每一步都涉及根据当前观察结果 o_n、可选的用户指令 u_n 和交互历史记录,预测下一个想法 t_n、动作 a_n 和可选的口头响应 r_n。这些中间想法提供了结构化的推理轨迹,可以指导决策,并实现与人类和环境进行细致入微、情境-觉察的交互。为了在 token 预算约束(例如 32k 上下文长度)下平衡内存使用并保持推理效率,仅保留最新的 N 个视觉观察结果作为显式输入。之前的想法和动作的完整序列存储在短期记忆中,这使得 Robix 能够推理近期历史记录而不会超出容量限制。
使用三阶段训练流程,在约 2000 亿个 token 上持续训练 Qwen2.5-VL-7B 和 32B [3],本文开发 Robix-7B 和 Robix-32B。首先,进行持续的预训练,以增强模型在机器人相关感知和推理方面的能力。接下来,应用监督式微调,将复杂的人机交互和长期任务规划建模为基于思维链推理的顺序决策过程。最后,利用强化学习进一步提高具身推理能力,并增强交互式长期任务中推理与行动之间的一致性。
持续预训练
通用具身模型的一项基本能力是具身推理——将物体和空间概念在物理世界中落地,并整合这些信号以用于后续机器人任务的能力 [64]。目标是开发一个以具身推理为核心的视觉-语言模型,该模型能够在保持强大的基础多模态理解的同时,跨各种具身场景进行泛化。为了实现这一目标,构建一个包含 2000 亿个高质量且多样化 tokens 的大规模预训练语料库,旨在兼顾机器人相关能力和通用多模态能力,如图所示。特别强调 3D 空间理解、视觉落地和以任务为中心的推理,同时融入通用视觉理解、多模态推理和指令调优数据。

3D 空间理解。当前的 VLM 普遍缺乏强大的空间理解能力,而这对于导航和操作规划等具身场景至关重要。为了使模型能够从 2D 图像中理解 3D 空间,整理超过 3000 万条指令对(约 400 亿个 tokens),涵盖五种关键任务类型:(1)多视图对应——学习同一场景的立体或多视图图像之间的 2D 点对应关系;(2)3D 边框检测——使用开放词汇目标描述从单目图像中预测度量 3D 边框;(3)相对深度排序——推断单个图像内目标的深度顺序;(4)绝对深度估计——使用语义掩码和带注释的深度图,估计目标的绝对深度;(5)自运动预测——对相机随时间的运动进行建模以支持时间和空间推理。大部分数据均来自或基于公开来源,例如 ScanNet [12]、ScanNet++ [79]、3RScan [66]、CA-1M [35]、SUN RGB-D [61] 和 ARKitScenes [4]。整合这五个空间推理任务可有效提升模型在具身任务中的空间感知能力。
视觉落地。视觉落地使多模态模型能够解读用户指令并定位图像中的目标物体。用两种基础格式——边框和中心点——并使用四种类型的数据进行训练:二维边框标注、点标注、计数和视觉提示。将所有坐标值归一化到 [0, 1000] 范围内,从而能够在不同的图像分辨率下实现一致的落地预测。数据集包含超过 5000 万个指令对(约 700 亿个 token),涵盖以下任务:(1)二维边框标注:根据开放词汇描述预测边框,或根据给定的边框坐标生成文本描述;(2)点标注:根据描述预测物体中心点,或根据给定的坐标识别物体。(3)计数:基于边框和点数据,通过两阶段定位和计数流程支持基于框和基于点的计数;(4)视觉提示:提示包含文本指令和视觉标注(例如,点、边框、箭头),使模型能够学习基于视觉线索的多模态融合和情境-觉察理解。这些任务共同显著增强模型在语言-到-图像和图像-到-语言两个方向上的落地能力,并提升了其在具身情境中进行落地规划的能力。
以任务为中心的推理。为了直接增强模型在具身场景中的推理和规划能力,基于公开的机器人数据集和自我中心数据集构建一个大规模的具身任务中心推理数据集,这些数据集包括 AgiBot [6]、BridgeData V2 [67]、Droid [32]、Egodex [27]、RoboVQA [52]、HoloAssist [70] 和 Ego4D [22]。整理超过 500 万个示例(约 100 亿个 token),针对三个关键推理功能:(1)任务状态验证——确定任务或子任务是否已成功完成;(2)动作 affordance——评估动作在当前情境下是否可行;(3)下一步行动预测——确定实现预期目标的最合理下一步。为了丰富推理过程,进一步使用 Seed-1.5-VL-thinking [24],通过精心设计的提示为问答对生成逐步的思维轨迹。这种思维增强的监督使模型能够在动态和开放式环境中学习深思熟虑的高级决策。
通用多模态推理。为了增强模型的通用推理能力,整理超过 600 万个多模态指令-图像对(约 100 亿个 token),涵盖 STEM 问题解决、基于智体的决策和视觉推理任务。具体而言,包括:(1) STEM 推理数据:数学、物理、化学和生物领域的多模态问题解决示例,将文本问题与图表、方程式和视觉内容相结合。(2) 多模态智体数据:基于 GUI 的智体演示,涉及逐步规划、纠错和反思性推理。(3) 视觉推理数据:需要扎实视觉推理的任务,包括识别配对图像之间的差异以及根据用户界面截图生成 HTML/CSS 代码。这些数据集共同赋予模型强大的抽象推理能力和跨模态问题解决能力,支持其在开放环境中泛化至复杂任务。
通用多模态理解。为了保存和增强广泛的视觉-语言理解,整理一个包含超过 5000 万个图文对(超过 800 亿个 token)的大规模数据集,作为多模态理解的基础。 (1) VQA:一套基于图像和视频的多样化问答任务,涵盖视觉感知、事实知识、基础概念、时间推理、空间理解和计数。(2) 字幕:为图像和视频提供密集字幕,支持模型理解静态场景和多帧时间动态。(3) OCR:为了改进文本识别,纳入涵盖场景文本、文档、表格、图表和流程图的大规模带注释和合成数据集。这些数据集共同为训练通用视觉-语言模型奠定了坚实的基础。
指令调优。为了进一步增强模型的指令遵循和推理能力,构建一个包含 100 万个示例的高质量指令调优数据集。这些示例涵盖广泛的任务,是通过从先前收集的数据中提取精选子集构建的,整合来自开源和内部来源的通用指令和思维链示例。用 Seed-1.5-VL [24] 对指令进行质量过滤,以确保指令、图像和响应之间更好地对齐。这个经过指令调优的数据集显著提升模型遵循开放世界多模态指令和进行多轮扎实推理的能力。
采用两阶段训练策略,利用上述大规模多样化语料库。在第 1 阶段,继续在完整数据集(约 5% 为纯文本数据)上预训练 Qwen2.5-VL [3],更新所有模型参数以增强通用多模态和具身推理能力。训练遵循完整的余弦学习率方案,从 1 × 10−5 开始衰减至 1 × 10−6,并在前 10% 的总步数中进行线性预热。用 32,768 个 token 的序列长度,7B 模型和 32B 模型的有效批次大小分别为序列长度的 1536 倍和 3008 倍。在第 2 阶段,对精选的指令遵循数据进行指令调整,以使模型与多模态提示对齐并提高指令遵循率。在此阶段,视觉编码器处于冻结状态,而所有其他参数保持可训练状态。学习率固定为第 1 阶段的最终值 (1 × 10−6),并在整个第 2 阶段保持不变。优化器状态从第 1 阶段延续,无需额外预热。两个阶段均使用 AdamW [33, 41] 进行优化,其中 β1 = 0.9,β2 = 0.99,权重衰减为 0.01。对这个多样化和全面的语料库进行训练,显著提高模型的具体推理、多模态理解以及它在现实世界中泛化到长期交互任务的能力。
监督微调
监督微调 (SFT) 阶段将先前的预训练模型适配到机器人的高级认知模块中,同时保留其原有的功能。核心挑战在于缺乏能够将人机交互与任务规划相结合的大规模、多轮自我中心视觉数据集。为了解决这个问题,其设计一个数据合成流程,将现有的任务规划数据集转换为人机交互轨迹。由此产生的 SFT 数据的两个特性对于实现分布外(OOD)泛化至关重要:(1) 多样化的人机交互;(2) 高质量的推理轨迹。整体流程如图所示:
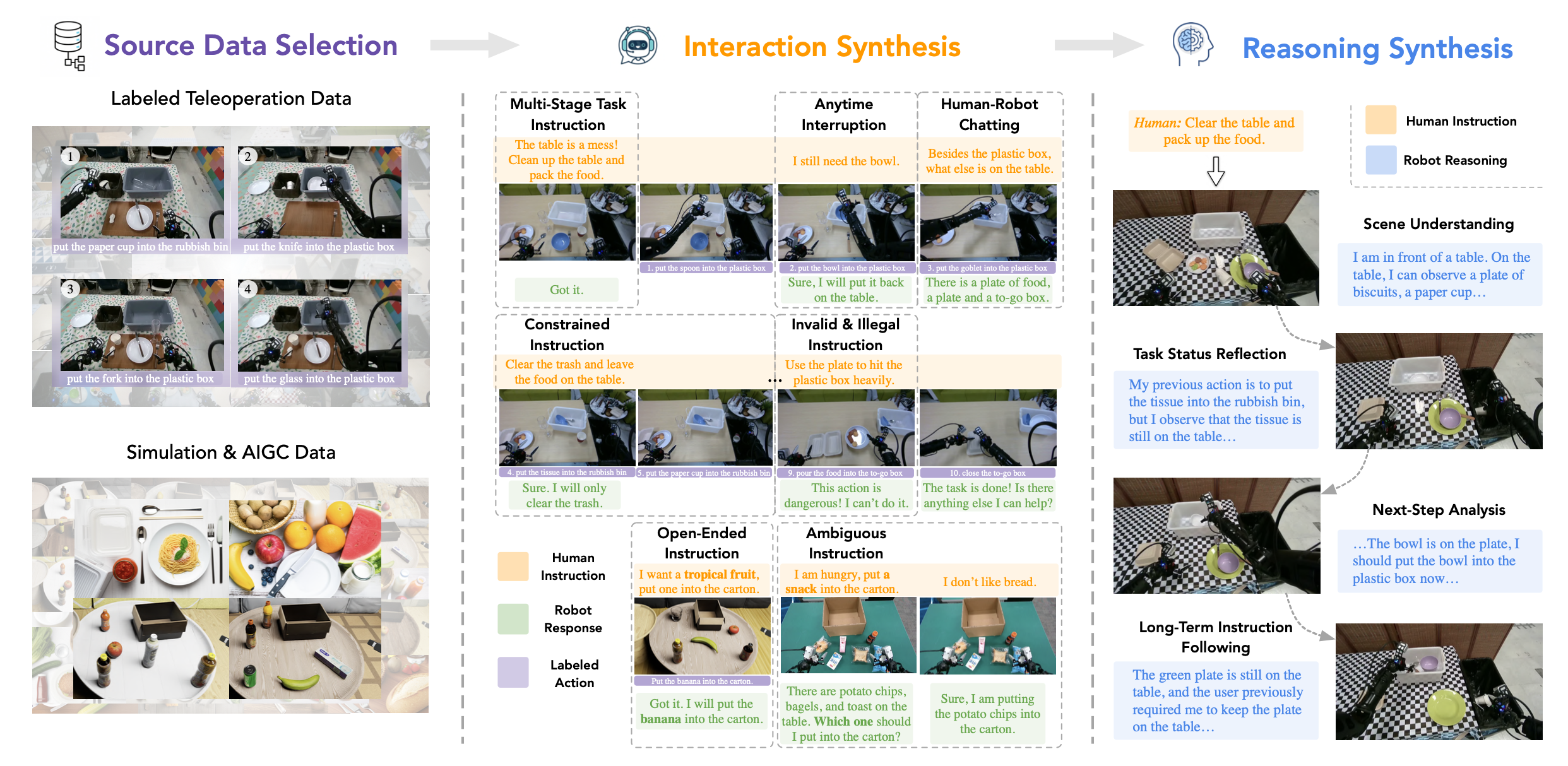
交互合成
交互合成主要基于两个数据源:
• 遥控机器人演示。利用内部遥控数据(之前用于训练 GR-3 [7])和开源 AGIBot 数据集 [6]。每集都包含机器人执行各种任务(例如,收拾餐桌、准备早餐)的片段。人工标注员将每个演示分割成多个片段,每个片段对应一个原子动作,例如,“把纸巾扔进垃圾桶”。
• 仿真与 AIGC 数据。在内部模拟器中以编程方式生成各种目标组织场景,并进一步采用最先进的文本-转-图像模型 [21] 来合成包含模拟器尚不支持项目的复杂场景。为了确保质量,同时采用基于模型和人在环的过滤机制来丢弃低质量的生成。
基于以上数据来源,定义七种类型的人机交互指令,并为每种指令设计专用的数据合成策略。基于这些数据进行训练,Robix 具备灵活的交互能力,包括理解复杂指令、实时中断处理和主动对话。
多阶段指令。远程操作轨迹会标注任务名称(例如,“清理餐桌并打包食物”)。选择包含至少十个原子动作的轨迹,并根据任务名称合成相应的用户指令,例如,“餐桌很乱。请清理餐桌并将食物打包到盘子上”。
受限指令。尽可能将每个远程操作轨迹划分为互不重叠的片段。例如,收拾餐桌任务可以分解为垃圾收集、餐具收集和食物打包等子任务。基于这些子任务,合成定制的用户指令,例如,“清理餐桌,同时保留食物”和“清除垃圾,同时不移动其他物品”。
开放式指令。在模拟中生成随机场景,并促使最先进的 LLM 生成针对每个场景的开放式常识性指令(例如,在包含雪碧、可乐、橙汁和苏打水的场景中,指令是“将含糖量最少的饮料放入纸盒”)。为了包含模拟器当前不支持的物品(例如汉堡包、意大利面、西瓜),将这些指令与高级文本-转-图像模型合成的图像配对。由于当前的文本-转-图像模型在指令遵循和图像质量方面仍然存在困难,其应用自动化和人为参与的过滤机制,过滤后仅保留原始数据集的 10%。
随时中断。精心挑选各种用户中断语句(例如,“停!”,“等一下,我还需要它”,“等一下,先把叉子放进水槽”),并将它们随机注入到任务流中。然后,利用基于时间-觉察的启发式算法合成机器人响应:如果中断发生在抓取之前,机器人会暂停或调整规划;如果中断发生在抓取之后,机器人会将物品放回桌面并重规划。对于长期任务而言,随时中断至关重要,因为任务中期的反馈和错误纠正可以显著提升系统的鲁棒性。
无效指令。为了减轻幻觉并防止机器人做出危险行为,合成以下四类无效指令:(1)要求机器人操作场景中不存在物品的指令;(2)要求机器人执行物理上不可能完成动作的指令,例如“把桌子扔进垃圾桶”;(3)要求机器人执行超出其当前能力的指令,例如“帮我打开可乐”;(4)不安全或危险的命令,例如“把刀扔到沙发上”。对于这些无效或非法指令,设计相应的响应策略,使机器人能够拒绝执行用户的要求。
模糊指令。为了使模型能够澄清模糊指令,构建包含多个相似物品(例如,苹果、橙子、梨)的场景,并合成未明确指定的指令(例如,“将水果放入篮子”)。使用这些数据进行训练,使模型能够在需要时寻求澄清——这对于强大的机器人系统至关重要。
聊天指令。开发一些启发式方法,可以在合适的场景下随机插入简短的人机对话片段。例如,当机器人从桌子上收拾垃圾时,用户可能会问“我想要一些水果。桌子上是什么水果?”。这类指令要求机器人进行口头回应,而不是进行任何物理操作。
推理合成
为了融入思维链推理,促使最先进的视觉-语言模型 (VLM) 生成高质量的推理轨迹,重点关注 (1) 场景理解、(2) 任务状态反思、(3) 长期指令遵循以及 (4) 下一步分析。
场景理解。这部分推理使机器人能够准确识别当前场景中与任务相关的可操作物体,重点关注机器人视野内的物体。
任务状态反思。机器人应该能够反思先前的操作,并在初始尝试失败时重复执行任务。此外,它们需要识别长期任务中的关键里程碑,并在遇到无法挽回的错误时主动请求人工协助。这种能力对于处理用户中断也至关重要,因为机器人必须保持对当前状态的感知,以便规划后续操作(例如,跟踪夹爪是否抓取了物品)。
长期指令跟踪。该模块旨在帮助机器人在长期任务中持续执行初始目标和中间用户指令,确保主要目标完成,并且任务中指令能够继续指导后续步骤的操作(例如,“清理完桌子后,从冰箱里拿杯饮料”)。
下一步分析。在推理的最后阶段,当整体任务尚未完成时,机器人应该分析下一步的潜行动。该分析包括评估目标的可达性以及执行该行动是否有助于整体任务的完成。
受 UI-TARS [50] 的启发,采用 ActRe [78] 和 Thought Bootstrapping [50] 来合成高质量的推理轨迹。与传统的 LLM 推理基于模型的过滤流程来丢弃不切实际或逻辑不一致的推理。这些高质量、多方面的思维链轨迹使 Robix 能够通过任务状态监控和动态重规划来执行稳健的长期任务规划。
强化学习
在监督微调 (SFT) 阶段之后,该模型在自适应任务规划和自然人机交互方面展现出良好的智体能力。然而,机器人推理和规划仍然存在一些局限性,特别是:(1) 非理性推理,例如产生矛盾的想法、缺乏常识或部分忽略用户指令;(2) 思维与行动不一致,即模型提出的规划在意图或内容上与先前的想法存在分歧。例如,在清洁桌面任务中,SFT 模型正确地推断出留在桌子上的纸巾应该丢弃在垃圾桶中。然而,在后续规划中,它错误地建议使用纸杯。这些问题对模型在实际任务执行中的有效性产生了负面影响。
为了缓解这些问题,采用强化学习 (RL),特别是群体相对策略优化 (GRPO) [23, 54],以增强推理能力以及思维与行动之间的一致性。该方法基于两个核心策略:(1) 与通用视觉推理数据协同训练;(2) 以思维-行动一致性为目标的奖励设计。
与通用视觉推理数据协同训练。强化学习阶段利用两个主要数据源:机器人交互数据和通用视觉推理数据集。基于机器人交互数据进行训练可以提高模型的鲁棒性和对分布外 (OOD) 场景的泛化能力。同时,结合通用视觉推理数据可以增强模型固有的推理能力。这种协同训练策略有助于缓解非理性推理,并增强整体任务理解和解决能力。通用视觉推理数据集涵盖广泛的认知挑战,例如任务完成验证、动作 affordance 评估和物体定位——涵盖了与现实世界机器人应用相关的广泛推理技能。
思维-行动一致性的奖励设计。为了明确鼓励模型思维与行动的一致性,除了输出格式和行动准确性的标准奖励之外,还引入了思维-行动一致性奖励。在每个决策步骤中,模型生成的思维及其对应的行动都会被提取出来,并由外部的大语言模型 (LLM)(在实验中为 Qwen-2.5-32B [74])进行评估。该辅助奖励模型会评估当前行动是否与先前的思维在逻辑上一致。如果评估结果显示不一致,则会给予负奖励。
为了最大限度地提高强化学习训练的有效性,还采用一种数据过滤程序,旨在仅保留能够为策略预测模型 (GRPO) 提供有意义的梯度信息的样本。其核心思想是丢弃候选答案奖励方差较低的问题,因为这类样本对策略改进的贡献甚微。具体来说,对于数据集中的每个问题,用 SFT 模型生成多个候选答案,并删除奖励方差较低的答案:D 表示原始数据集,R(yi_n ,y*_n) 是奖励函数,它根据问题 x_n 的真实值 y_n,为第 i 个生成的答案 y_n 分配一个标量分数,π_SFT 是 RL 的基本策略。输入 x_n 和输出 y_n∗ 的定义遵循等式:x_n 由当前的观察、指令和轨迹组成,而 y_n 包括模型的思维、可选动作和可选的机器人响应。在实验中,将样本数 M 设置为 8,将方差阈值 τ 设置为 0。所有 RL 训练均使用 verl 框架 [55] 进行。
通过结合多样化推理数据的协同训练和有针对性的奖励设计,强化学习策略显著提高模型对新任务的泛化能力,增强推理和规划之间的一致性。
对 Robix 进行持续预训练(记为 Robix-Base),并在一系列全面的公共基准测试中与最先进的多模态模型进行了比较,这些模型包括 Qwen-2.5-VL-7B&32B [3]、RoboBrain-2.0-32B [63]、Cosmos-Reason1-7B [2]、Gemini-2.5-Pro [64]、OpenAI GPT-4o [30]、Seed-1.5-VL 和 Seed-1.5-VL-Think [24]。评估涵盖:(1) 机器人相关的具身推理(3D 空间理解、视觉基础、任务中心推理)和 (2) 通用多模态理解与推理。
离线评估可使用预定义评估集完全自动化地评估规划和交互能力。为了全面评估交互式长期规划和分布外 (OOD) 泛化能力,设计三个专用评估集:
• AGIBot 评估集。从 AGIBot 数据集中手动选取 16 个高频日常任务(例如,制作三明治、用洗碗机洗碗、摆放沙发、用洗衣机洗衣服、插花),并确保这些任务未出现在训练数据中。该评估集主要评估模型在分布外 (OOD) 任务上的长期任务规划能力。
• 内部分布外 (OOD) 基准测试。手动设计 16 个脚本,涵盖任务规划和各种人机交互场景,包括餐桌整理(他变了organization)、食物筛选(dietary filtering)、收银打包(checkout packing)、购物(grocery shopping)和鞋柜整理(shoe cabinet organization)。这些脚本由人类参与者执行——一个扮演用户,另一个通过机器人遥控或通用操作接口 (UMI) [10] 设备执行动作——随后由经过训练的注释者进行注释。该基准测试包含训练数据中不存在的任务和项目,旨在评估在未见过的场景中交互式任务的执行情况。
• 内部分布内 (ID) 基准测试。该评估集从合成数据中随机抽样,并根据任务类型和用户指令分为六类:(1) 多阶段指令,(2) 受限指令,(3) 无效指令,(4) 用户中断,(5) 失败并重规划,以及 (6) 开放式指令。每个类别都旨在评估模型相应的指令遵循和任务规划能力。
基线方法。与广泛使用的商业和开源 VLM 进行比较,包括 Gemini-2.5-Pro、GPT-4o、Seed-1.5-VL、Seed-1.5-VL-Think、Qwen2.5-VL-7B/32B/72B、GLM-4.1V-9B-Thinking [26] 和 RoboBrain-2.0-7B/32B。对于每个模型,都测试英文和中文提示,并报告更优的结果。Gemini-2.5-Pro 和 GPT-4o 在英文提示下表现更佳,而其他模型在中文提示下准确率更高。所有评估均采用贪婪解码法进行。
虽然离线评估成本低廉,但它仅限于静态环境,无法评估模型与动态物理世界的交互能力。为了解决这个问题,将模型和基线部署到一个分层机器人系统中,涵盖各种现实场景(包括厨房、会议室和杂货店),并进行在线评估,以衡量它们作为日常任务的高级规划和交互模块的有效性。设计两组实验:
• 视觉语言模型 (VLM) 的在线评估。在不受底层控制器影响的情况下,独立评估 VLM 的规划和交互能力。
• VLM-VLA 机器人系统的在线评估。通过将 VLM 与自动 VLA 模型配对作为底层控制器,评估端到端系统的性能。
VLM 评估实验设置。设计五项任务——收拾餐桌、打包收银台、筛选食物、购物以及餐具整理与配送——涵盖厨房、会议室和杂货店等多种环境。为了增强真实感,部分任务特意融入了用户干扰以及“失败并重新规划”的场景。进一步为每个任务添加子任务注释以评估完成情况(例如,对于收拾餐桌的任务:“纸巾在垃圾桶里”、“盘子在篮子里”)。将 Robix-32B 1 与四个在离线评估中表现良好的基准模型进行比较:Gemini-2.5-Pro、GPT-4o、Seed-1.5-VL-Think 和 Qwen2.5-VL-32B。为了减少实验差异,每个任务-模型对重复四次,并报告平均结果。遵循[57]的做法,用任务进度(即任务结束时子任务完成的百分比)作为评估指标。训练有素的人工标注员会评估任务进度,以确保其可靠性和一致性。
VLM-VLA 实验设置。从在线评估中选择三个任务——清洁餐桌、筛选食物和打包收银台——作为评估集,并排除了剩余两个超出 GR-3 当前能力的任务。为了更好地区分高级认知层的性能,还移除特别具有挑战性的项目,以减少频繁的操作失败。按照 VLM 在线评估协议,每个任务-模型对进行四次评估,并以任务进度为指标报告平均结果。所有实验均使用 GR-3 模型和 ByteMini 机器人进行 [7]。

















 993
993

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









