










24年12月来自中科院自动化所、中科院大学和中科院香港AI机器人中心的论文“DrivingGPT: Unifying Driving World Modeling and Planning with Multi-modal Autoregressive Transformers”。
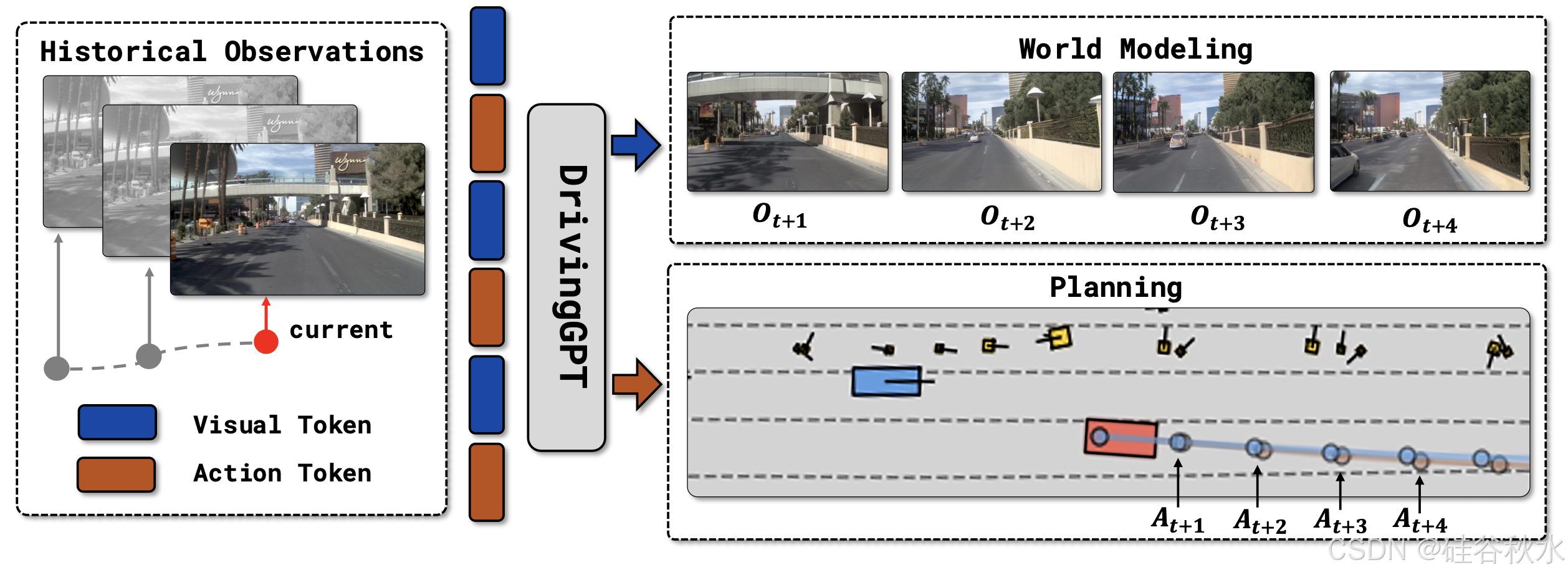
基于世界模型的搜索和规划被广泛认为是实现人类水平物理智能的一条有前途的道路。然而,目前的驾驶世界模型主要依赖于视频扩散模型,这些模型专注于视觉生成,但缺乏纳入动作等其他模态的灵活性。相比之下,自回归TRansformer在建模多模态数据方面表现出色。该工作旨在将驾驶模型模拟和轨迹规划统一为一个序列建模问题。引入一种基于交错图像和动作tokens的多模态驾驶语言,开发 DrivingGPT,通过标准的下一个token预测来学习联合世界建模和规划。DrivingGPT 在动作条件视频生成和端到端规划方面都表现出色,在大型 nuPlan 和 NAVSIM 基准测试中表现优于强大的基线。DrivingGPT 概览如图所示:
世界模型 [23, 24, 34] 在自动驾驶领域引起广泛关注,旨在根据动作预测不同的未来状态。现有工作主要侧重于生成,无论是 2D 视频预测 [19, 27, 31, 60, 62, 63, 70] 还是 3D 空间预测 [21, 65, 74–76]。其中,视觉建模因其更丰富、更像人类的表现形式而受到了广泛关注。Drive-WM [63] 进一步探索如何使用未来视觉反馈来指导端到端规划器。除了 GAIA-1 具有一个带有附加扩散图像解码器的自递增下一个token预测器外,大多数先前的工作都建立在扩散模型之上 [1, 46]。尽管扩散模型已经实现更逼真的视觉质量,但它们仍然面临着时间一致性和更长视频生成方面的挑战。
早期研究探索像素级的直接自回归图像生成 [55, 56]。受 VQVAE [57] 的启发,许多方法 [18, 35, 73] 将连续图像编码为离散tokens。最近,有几种方法借鉴大语言模型 [53] 中使用下一个token预测范式的成功,将其应用于图像和视频生成。在图像生成方面,LlamaGen [49] 使用语言模型架构来证明简单的下一个token预测可以生成高质量的图像。此外,VAR [52] 采用下一尺度预测生成范式,与传统语言模型的序列建模方法有所区别。在视频生成方面,Loong [64] 提出渐进的从短到长的训练,探索长视频的自回归生成。同时,VideoPoet [33]、Chameleon [51] 和 Emu3 [61] 专注于多模态生成,通过使用离散token将语言理解与视觉生成相结合。
端到端自动驾驶[2, 10, 14, 29, 32, 44, 67]因其能够从原始传感器输入直接生成车辆运动规划而备受关注。从评估基准来看,现有方法可分为开环和闭环设置。对于闭环评估,大量研究[11–13, 26, 28, 30]在模拟器中进行评估,例如CARLA [17]、nuPlan [7]和Waymax [22]。最近,在开环基准上开发端到端模型引起越来越多的关注。在nuScenes [6]基准上,UniAD [29]引入一个统一的框架,该框架集成多个驾驶任务并直接生成规划输出。VAD [32]推进矢量化自动驾驶,提高性能。 PARA-Drive [66] 设计一种完全并行的端到端自动驾驶汽车架构,在感知、预测和规划方面实现最先进的性能,同时还显著提高运行时效率。SparseDrive [50] 探索稀疏表示,并提出一种分层规划选择策略。
经过训练用于下一个token预测的自回归Transformer已在不同领域展现出卓越的能力。这项工作通过结合世界建模和轨迹规划,利用自回归Transformer的强大功能实现自动驾驶。该方法将视觉输入和驾驶动作都转换为离散的驾驶语言,从而通过自回归Transformer实现统一建模,如图所示。
与许多其他任务一样,驾驶问题可以表述为马尔可夫决策过程 (MDP),它是在具有部分随机结果的环境中进行决策的通用数学框架。MDP 包含一个状态空间 S,它反映自车和环境的所有状态,一个动作空间 A,一个随机转换函数 P(st+1 | st, at),它描述给定时间 t 的状态和动作所有可能结果的概率分布,以及一个标量奖励函数 R(st+1 | st, at),它决定在特定状态下应采取的最佳动作。在大多数实际应用中,只能感知到噪声观测 ot 而不是底层状态 st。因此,引入观测概率函数 Z(ot | st),MDP 变为部分可观测 MDP (POMDP)。
预测未来轨迹的端到端策略 π(at | ot) 和模拟驾驶世界动态的观测空间随机转移函数 P(ot+1 | ot, at) 在自动驾驶中都非常重要。
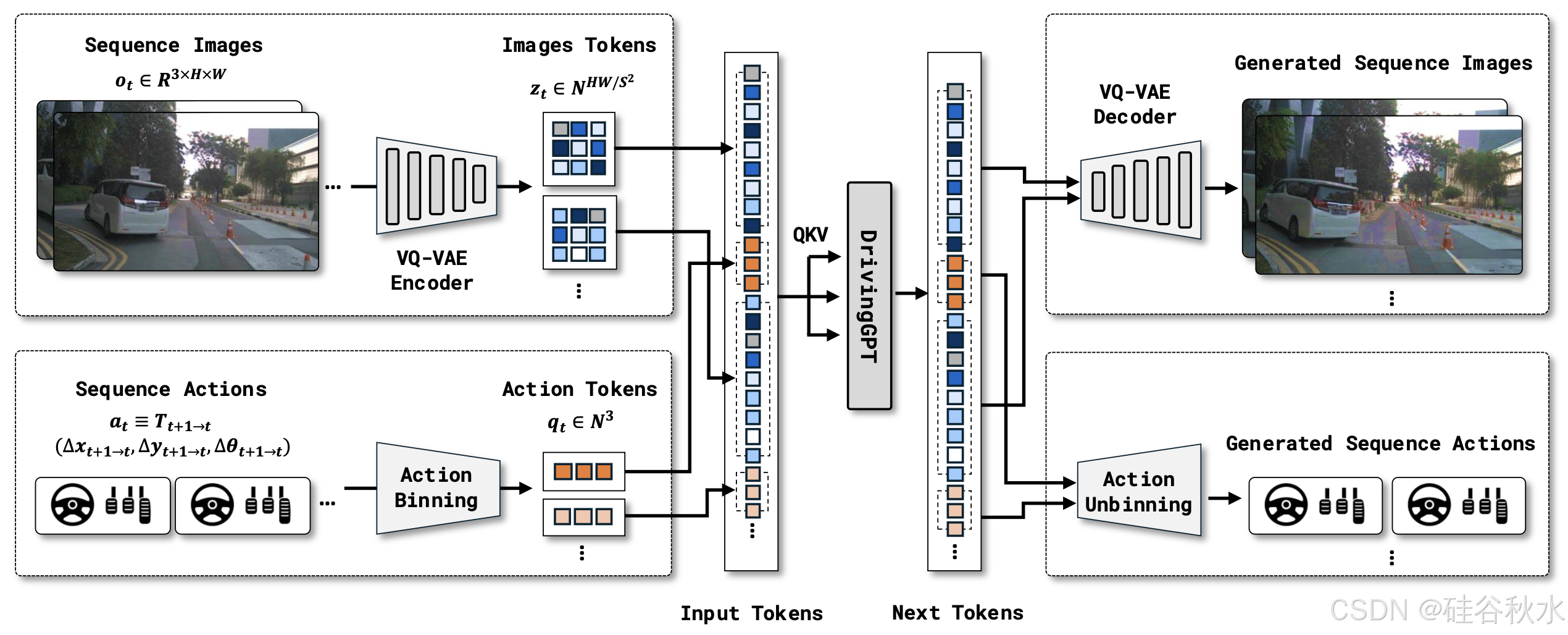
一般驾驶序列可以表示为一系列时间同步的观察-动作对 o/1、a/1,o/2、a/2,…,o/t、a/t,时间范围为 T。在这里,需要将观察 o/t 和动作 a/t token 化为离散 tokens,并形成一个多模态驾驶语言,然后才能利用自回归Transformer 进行下一个 token 预测。
为了简化方法,只将前置摄像头图像 oi 包含在观察空间中。为了将更多帧合并到序列建模中,利用 VQ-VAE [18] 将形状为 H × W 的图像 oi 下采样为形状为 H/S × W/S 且词汇大小为 D 的图像tokens zi。
预测的不是长距离绝对驾驶轨迹,而是逐帧相对驾驶轨迹。首先将每个动作分量限制在其第 1 和第 99 个百分位之间,从而将 量化为动作tokens。然后,将限制的动作分量均匀地分成 M 个 bins qt,从而获得动作 tokens qt。由于 x、y、θ 的大小和单位各不相同,用不同的词汇表量化这三个动作分量,以最大限度地减少信息损失。
根据 token 化的驾驶序列(如 z/1、q/1、z/2、q/2、…、z/T、q/T)构建统一的驾驶语言,其中 z/t 代表图像 tokens {z/tj}^HW/S2,q/t 代表动作 tokens {q/tk},然后利用带有因果注意掩码的自回归 Transformer 将驾驶建模为下一个token预测。
将视觉模态和动作模态视为不同的外语,并使用统一的词汇表进行驾驶。视觉模态的词汇量为 D,即 VQ-VAE 的码本大小。动作模态的词汇量为 3M,其中 M 是每个动作组件的bin大小,3 表示不同的动作组件。因此,多模态驾驶语言的词汇量为 D + 3M。对图像和动作 tokens 都应用逐帧 1D 旋转嵌入 [48]。然后,自回归Transformer p/θ,学习用标准交叉熵损失对统一标记序列 x 进行建模。
虽然驾驶语言模型形式看起来很简单,但它明确地将驾驶世界建模 p/θ(z/t | z/<t, q/<t) 和端到端驾驶 p/θ(q/t | z/≤t, q/<t) 作为其子任务。
由于在驾驶语言中使用帧间相对动作,因此需要将它们积分回去以获得绝对驾驶轨迹。首先将预测动作 {q/tk} = (x/t, y/t, θ/t) 转换为 2D 变换矩阵,然后进行积分。
然后,通过连乘这些相对姿势矩阵来获得绝对姿势,并将其相应地转换回绝对动作。
训练中,nuPlan 和 NAVSIM 都记录高 900 像素、宽 1600 像素的摄像头图像。将原始图像调整为 288×512,同时保持宽高比。模型结构与 LlamaGen [49] 相同,其 SwishGLU 和 FFN 维度设计与原始 Llama [53] 相同。用空间下采样率为 8 和 16 的 VQVAE 对图像进行token化,这会导致每个前置摄像头图像产生 2304 或 576 个图像tokens。对于 nuPlan,用 10Hz 的 16 帧剪辑范围,对于 NAVSIM,按照官方评估协议使用 12 帧,包括 4 个历史帧和 8 个未来帧,频率为 2Hz。用的图像词汇量为 16384,每个动作组件的动作词汇量为 128,因此驾驶语言的总词汇量为 16768。用标准交叉熵损失进行下一个token预测。用 AdamW 优化器,学习率为 10−4,权重衰减为 5 × 10−2,一阶/二阶动量为 0.9/0.95。将梯度的总范数剪裁为 1.0,并使用 0.1 的token-级 dropout 率进行正则化。在图像token化之前,应用随机水平图像翻转作为增强,并相应地翻转动作中的点和偏航方式。默认情况下,模型训练 100k 次迭代,总批次大小为 16。
推理中,对温度为 1.0 且 top-k 为 2000 的图像tokens进行采样。由于驾驶语言包含图像和动作词汇,因此采用引导采样方案,通过屏蔽外部词汇的 logit,以避免在温度较高时偶尔采样其他模态的tokens。对于长视频生成,一次生成 16 帧,并以之前的 8 帧为条件。

















 1768
1768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









