




一、三级模式—两级映射
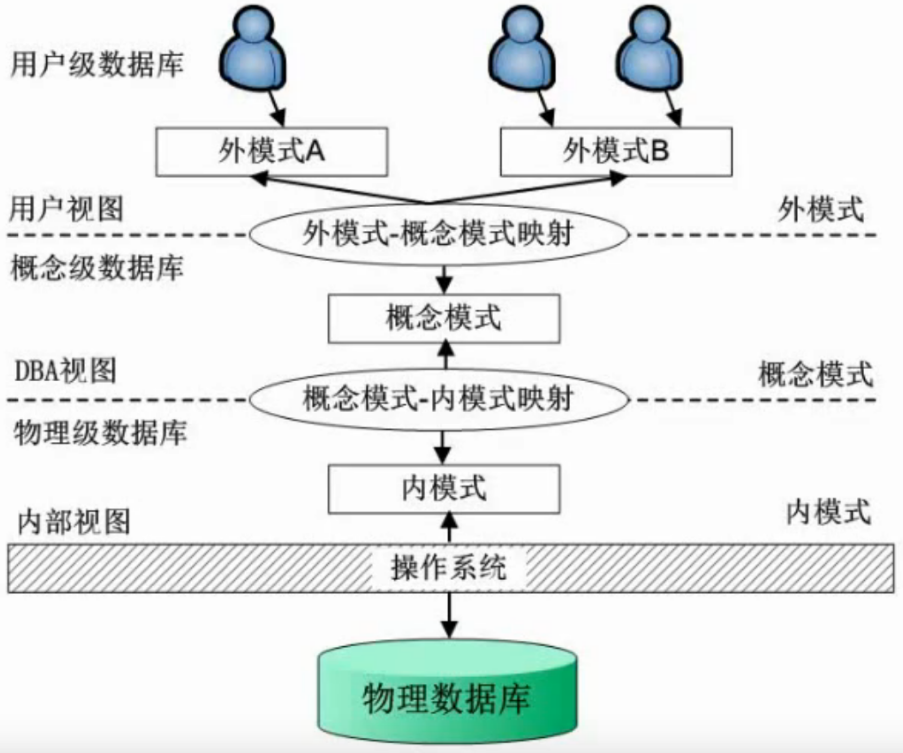
内模式:如何存储数据
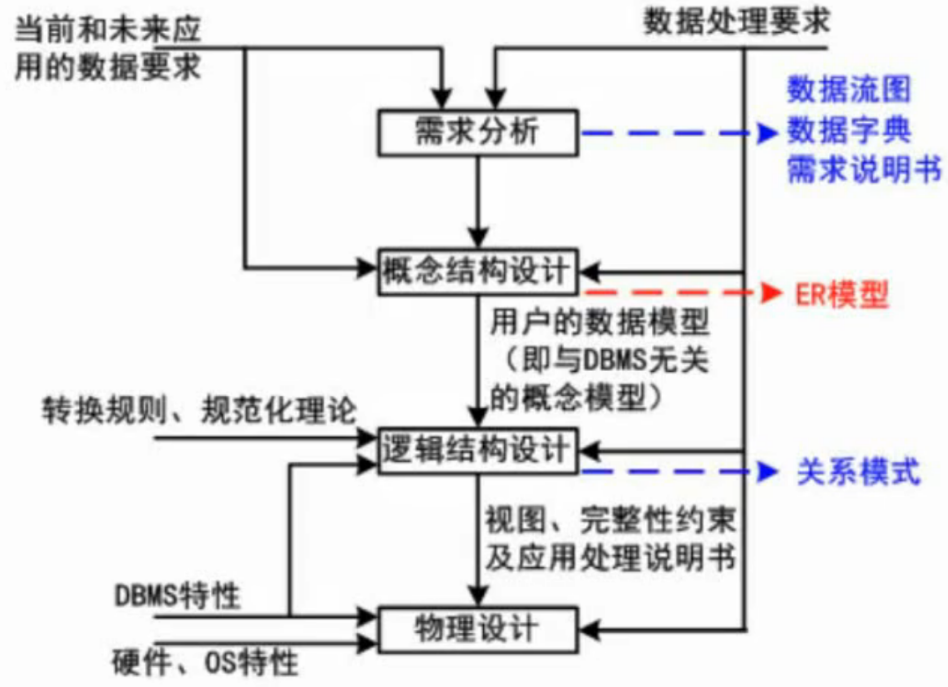
二、数据库设计过程
三、E-R模型
E-R模型示例: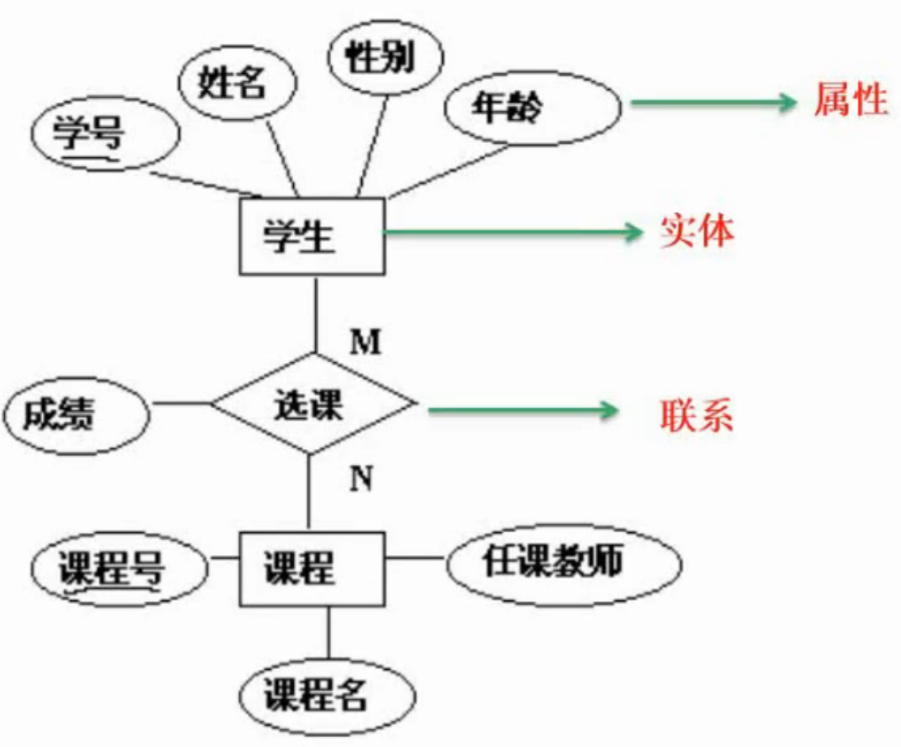
集成的方法:
多个局部E-R图一次集成。
逐步集成,用累加的方式一次集成两个局部E-R。
集成产生的冲突及解决办法:
属性冲突:包括属性域冲突和属性取值冲突
命名冲突:包括同名异义和异名同义。
结构冲突:包括同一对象在不同应用中具有不同的抽象,以及同一实体在不同局部E-R图中所包含的属性个数和属性排列次序不完全相同。
E-R模型转关系模式时:
一个实体型转换为一个关系模式
1:1联系:两个实体各自转换为关系模式,中间的联系则可以单独为一个关系模式或是和任意实体结合成为一个关系模式
1:n联系:同样最少转换为两个关系模式
m:n联系时联系必须单独为一个实体
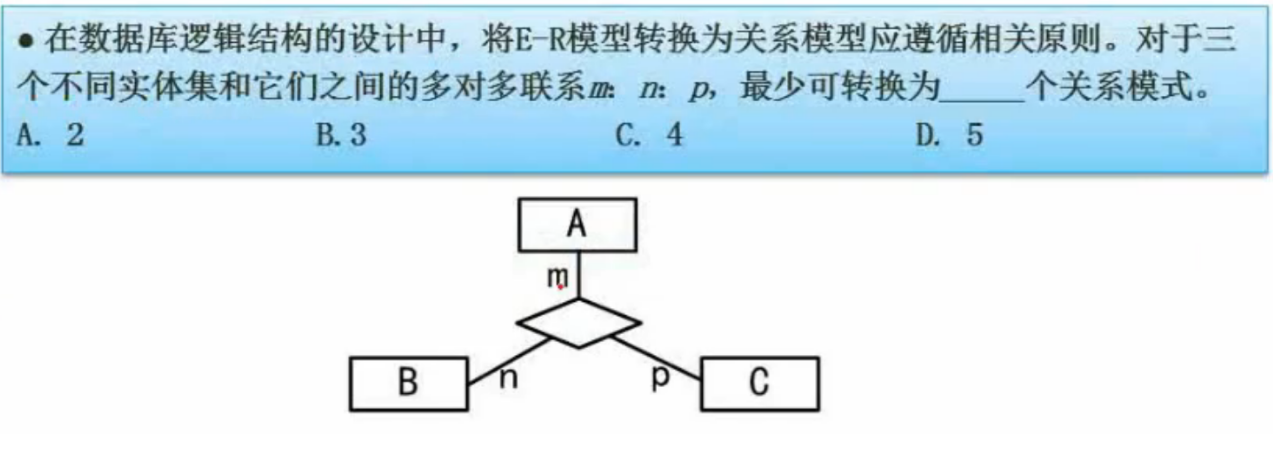
由上知识点易得答案为C
四、关系代数
并、交、叉、笛卡尔积、投影、选择、联接
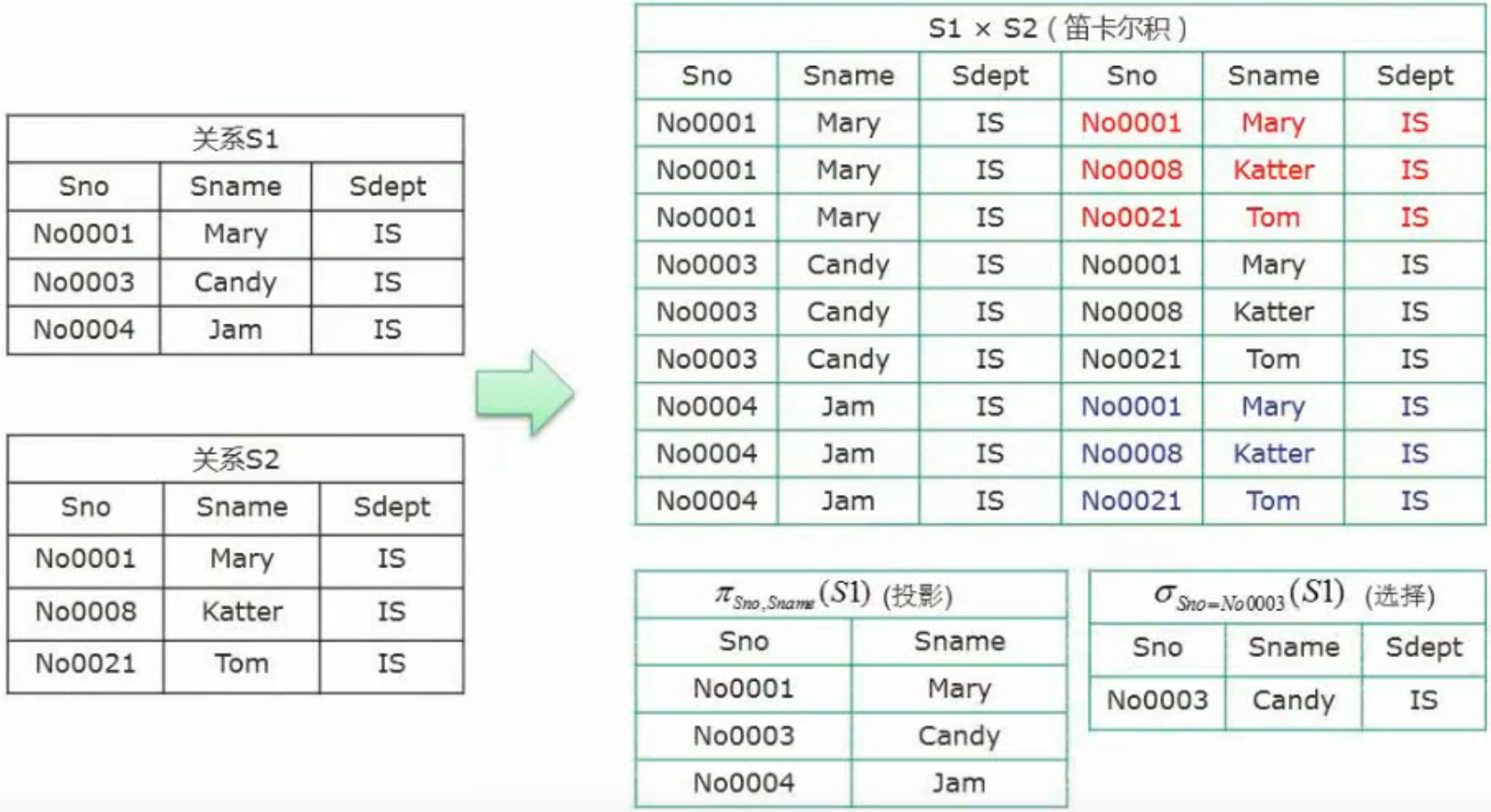
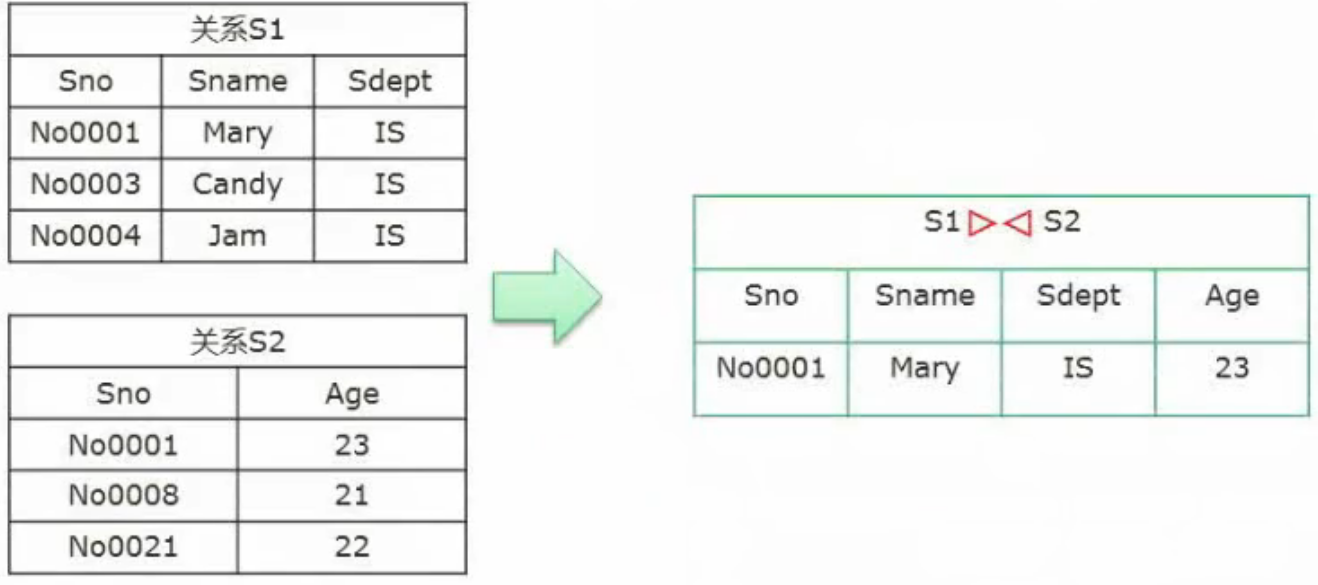
联接:
五、规范化理论
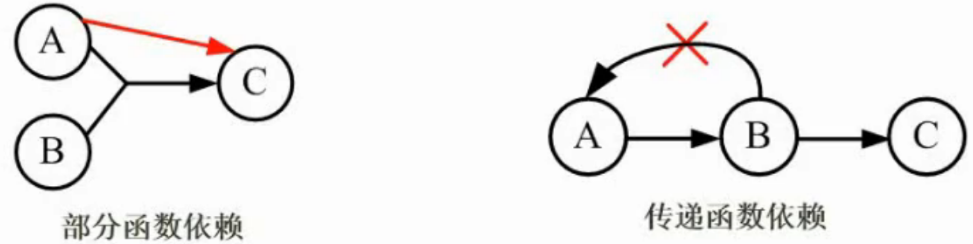
1.函数依赖
设R(U)是属性U上的一个关系模式,和Y是u的子集,r为R的任一关系,如果对于r中的任意两个元组u,v,只要有u[X]=v[X],就有u[Y]=v[Y],则称X函数决定Y,或称Y函数依赖于X,记为X→Y。
2.价值与用途
非规范化的关系模式,可能存在的问题包括:数据冗余、更新异常、插入异常、删除异常
例如:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









