







接着上一部分,在读取过程中StreamingMonitorFunction的monitorAndForwardSplits()方法如何获取到增量FlinkInputSplit
FlinkInputSplit[] splits = FlinkSplitPlanner.planInputSplits(this.table, newScanContext, this.workerPool);
调用FlinkSplitPlanner的planInputSplits方法:
static FlinkInputSplit[] planInputSplits(Table table, ScanContext context, ExecutorService workerPool) {
try {
CloseableIterable<CombinedScanTask> tasksIterable = planTasks(table, context, workerPool);
Throwable var4 = null;
FlinkInputSplit[] var8;
try {
List<CombinedScanTask> tasks = Lists.newArrayList(tasksIterable);
FlinkInputSplit[] splits = new FlinkInputSplit[tasks.size()];
boolean exposeLocality = context.exposeLocality();
Tasks.range(tasks.size()).stopOnFailure().executeWith(exposeLocality ? workerPool : null).run((index) -> {
CombinedScanTask task = (CombinedScanTask)tasks.get(index);
String[] hostnames = null;
if (exposeLocality) {
hostnames = Util.blockLocations(table.io(), task);
}
splits[index] = new FlinkInputSplit(index, task, hostnames);
});
var8 = splits;
} catch (Throwable var13) {
var4 = var13;
throw var13;
} finally {
if (tasksIterable != null) {
$closeResource(var4, tasksIterable);
}
}
return var8;
} catch (IOException var15) {
throw new UncheckedIOException("Failed to process tasks iterable", var15);
}
}
planTasks方法:
static CloseableIterable<CombinedScanTask> planTasks(Table table, ScanContext context, ExecutorService workerPool) {
FlinkSplitPlanner.ScanMode scanMode = checkScanMode(context);
if (scanMode == FlinkSplitPlanner.ScanMode.INCREMENTAL_APPEND_SCAN) {
IncrementalAppendScan scan = table.newIncrementalAppendScan();
scan = (IncrementalAppendScan)refineScanWithBaseConfigs(scan, context, workerPool);
if (context.startSnapshotId() != null) {
scan = (IncrementalAppendScan)scan.fromSnapshotExclusive(context.startSnapshotId());
}
if (context.endSnapshotId() != null) {
scan = (IncrementalAppendScan)scan.toSnapshot(context.endSnapshotId());
}
return scan.planTasks();
} else {
TableScan scan = table.newScan();
scan = (TableScan)refineScanWithBaseConfigs(scan, context, workerPool);
if (context.snapshotId() != null) {
scan = scan.useSnapshot(context.snapshotId());
}
if (context.asOfTimestamp() != null) {
scan = scan.asOfTime(context.asOfTimestamp());
}
return scan.planTasks();
}
}
此处为核心内容,调用BaseIncrementalAppendScan的planTasks()方法:
public CloseableIterable<CombinedScanTask> planTasks() {
//获取到所有数据文件
CloseableIterable<FileScanTask> fileScanTasks = this.planFiles();
//对大文件进行拆分
CloseableIterable<FileScanTask> splitFiles = TableScanUtil.splitFiles(fileScanTasks, this.targetSplitSize());
//把多个小文件合并成在一个 CombinedScanTask 中
return TableScanUtil.planTasks(splitFiles, this.targetSplitSize(), this.splitLookback(), this.splitOpenFileCost());
}
通过以下流程来生成输入分片:
- 由 planFiles() 获取所有需要读取的数据文件, 实际是委托给了 ManifestGroup 来操作
- 对大文件进行拆分,如果单个文件大小超过 SPLIT_SIZE,默认128M,并且文件格式支持切分,会对文件进行切分
- 将小文件打包在一起,如果文件比较小,比如只有1KB, 会将多个文件打包成一个输入分片,如果文件大小小于 SPLIT_OPEN_FILE_COST, 默认4M,会按照 SPLIT_OPEN_FILE_COST 来计算
其中:
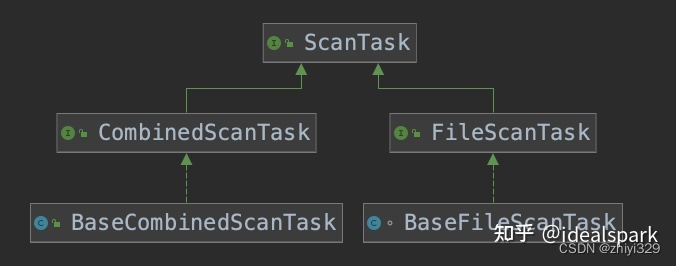
FileScanTask 表示一个输入文件或者一个文件的一部分,在这里实现类是 BaseFileScanTask
CombinedScanTask 表示多个 FileScanTask 组合在一起,实现类是 BaseCombinedScanTask
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 654
654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









