



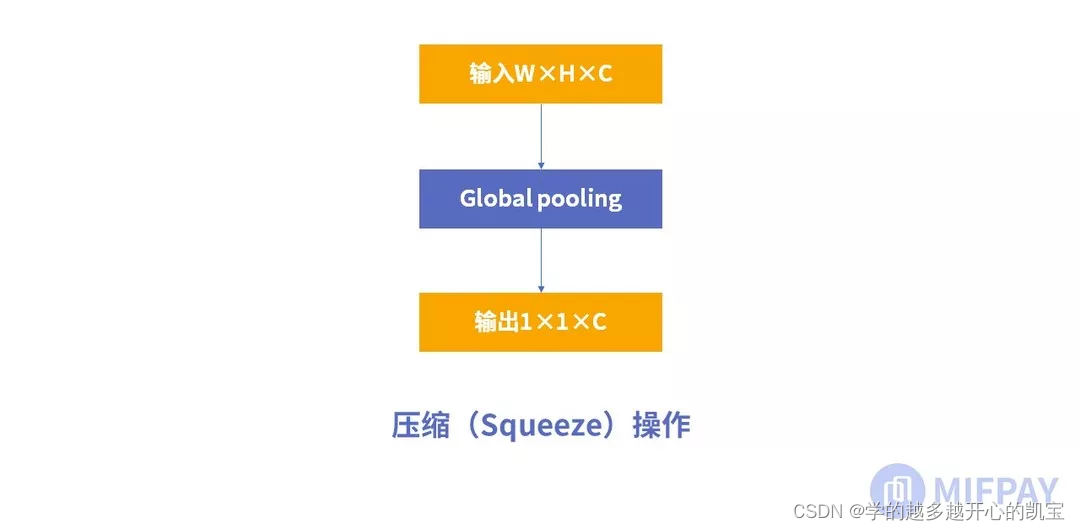
1、压缩(Squeeze)
进行的操作是 全局平均池化(global average pooling)
特征图被压缩为1×1×C向量
2、激励(Excitation)
两个全连接层。
两个FC组成一个可训练的函数,用来学习通道注意力。(所以FC激活函数不是线性的就行)
两个FC构成了bottleneck结构:(SERatio是一个缩放参数)
第一个FC把神经元数量减少了
- 除去冗余信息 2. 降低计算量
第二个FC的作用就是恢复到1×1×C尺寸。
(分割的Unet把尺寸越整越小就是在把那些纹理什么信息都取掉,只留下边界信息,之后再把尺寸回到原来的大小)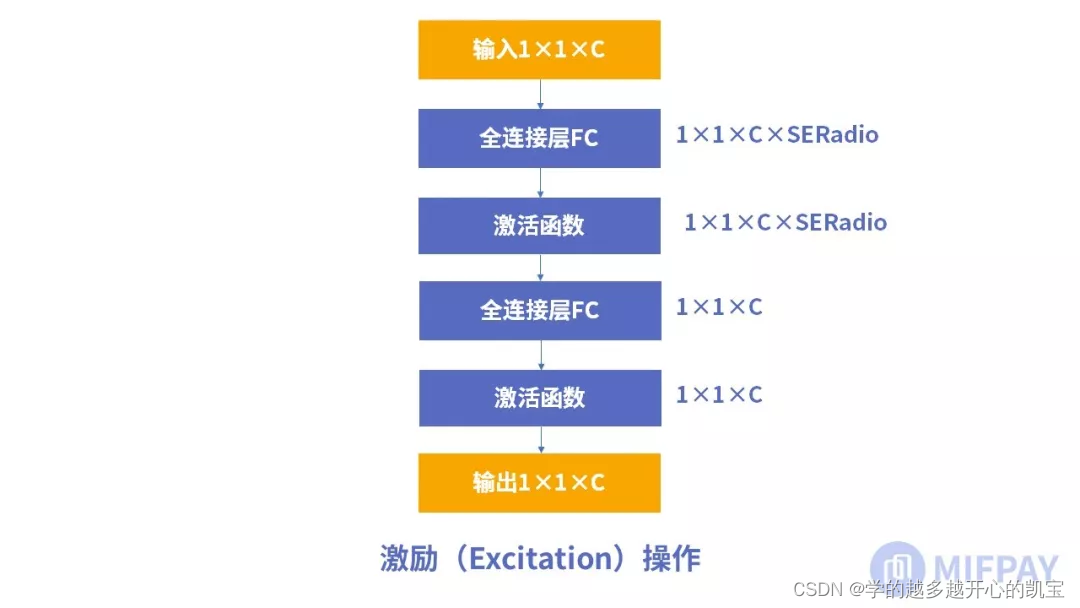

















 880
880

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









