






Start
下载
-
!!!!!先下载:Numpy、matplotlib、Scipy!!!!!
-
才能正常下载(有镜像源):pip install -i Simple Index scikit-learn
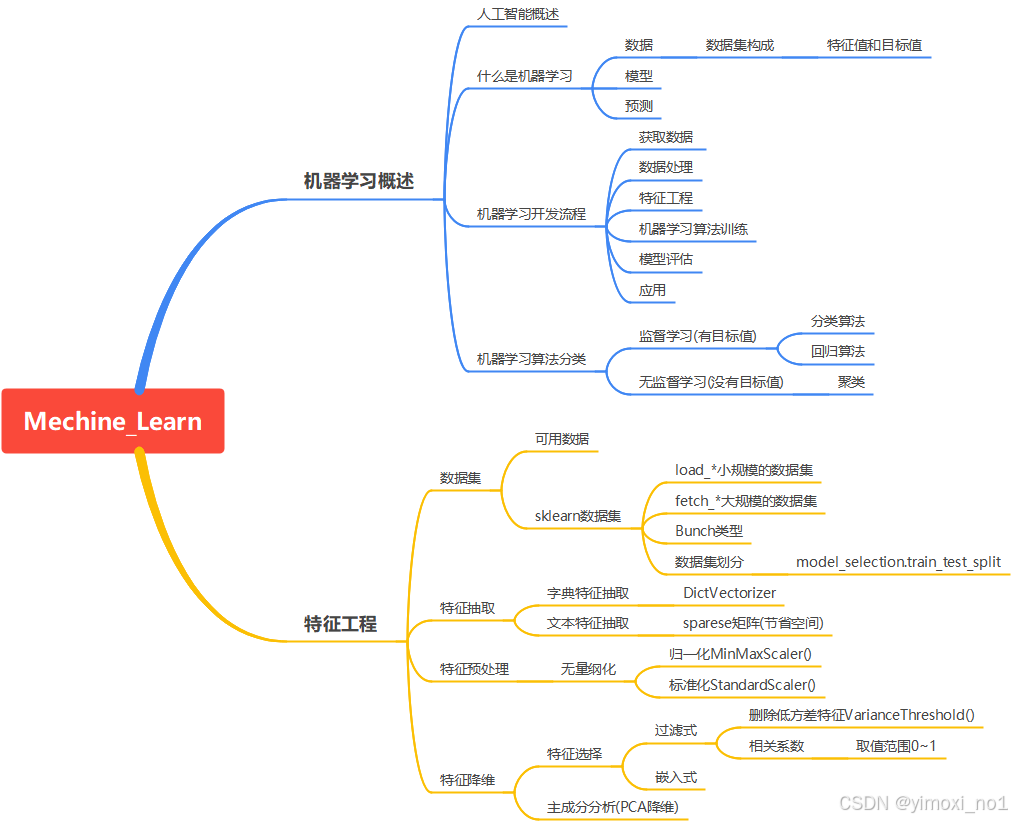
特征工程
数据集
学习阶段数据集:sklearn、kaggle、UCI
sklearn数据集
-
小规模:datasets.load_()
-
大规模:datasets.fetch_(data_home=None)
-
数据集的返回值:

# 导入鸢尾花数据集
from sklearn.datasets import load_iris
def datasets_demo():
# sklearn数据集使用
iris = load_iris()
print("鸢尾花数据集:", iris)
print("数据集描述:", iris["DESCR"])
print("特征名字:", iris.feature_names)
print("特征值:", iris.data, iris.data.shape)
return None
if __name__ == '__main__':
datasets_demo()
数据集划分

-
训练集特征值:x_train
-
测试集特征值:x_test
-
训练集目标值:y_train
-
测试集目标值: y_test
# 导入鸢尾花数据集
from sklearn.datasets import load_iris
# 导入数据集划分模块
from sklearn.model_selection import train_test_split
def datasets_demo():
# 获取鸢尾花数据集
iris = load_iris()
# 数据集划分
# iris.data: Iris数据集的特征(总共有四个特征)
# random_state = 22: 控制随机数生成器的种子,以相同的方式分割数据,从而确保结果的可重复性
# test_size: 默认情况下,75%的数据分配给训练集,剩下的25%分配给测试集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)
print("训练集的特征值:\n", x_train, "\n", x_train.shape)
return None
if __name__ == '__main__':
datasets_demo()
特征提取
特征提取API:sklearn.feature_extraction
将任意数据转换为可用于机器学习的数字特征:

字典 DictVectorizer
将类别转换成one-hot编码

# DictVectorizer将字典列表转换成 NumPy 数组或稀疏矩阵
from sklearn.feature_extraction import DictVectorizer
def dict_demo():
# 字典特征提取
data = [{"city": "北京", "temperature": 100}, {"city": "上海", "temperature": 60}, {"city": "深圳", "temperature": 30}]
# 1、实例化一个转换器
transfer = DictVectorizer(sparse=False) # sparse=True为稀疏矩阵
# 2、调用fit_transform():先学习(即“拟合”)字典中的键作为特征名,然后将 data 列表中的字典转换为 NumPy 数组
data_new = transfer.fit_transform(data)
print(data_new)
print("特征名字:", transfer.get_feature_names_out()) # get_feature_names_out获取特征名
return None
if __name__ == '__main__':
dict_demo()
文本 CountVectorizer

英文文本特征提取
# CountVectorizer将文本数据转换为数值特征矩阵
from sklearn.feature_extraction.text import CountVectorizer
def count_demo():
data = ["lift is short, i like like python", "lift is too long, i dislike python"]
# 实例化一个转换器
transfer = CountVectorizer()
# 调用fit_transform
data_new = transfer.fit_transform(data)
print("出现的次数:", data_new.toarray()) # toarray()转换二维数组
print("特征名字:", transfer.get_feature_names_out())
if __name__ == '__main__':
count_demo()
中文文本特征提取 jieba
# CountVectorizer将文本数据转换为数值特征矩阵
from sklearn.feature_extraction.text import CountVectorizer
# 导入jieba包, 精确模式进行分词
import jieba
def count_chinese_dome():
# 1、将中文文本进行分词
data = ["也很不错,这个课非常适合第一次入门机器学习,尽管大部分内容是在掉包。",
"但其中也不乏穿插算法的简单原理介绍,学完这门课你会对几个算法有个大致的了解。",
"接着去听细致讲算法的课就不会那么一脸懵,而且能对机器学习的流程有一个比较清晰完整的认知。"]
data_new = []
for sent in data:
data_new.append(cut_word(sent))
# 1、实例化一个转换器
transfer = CountVectorizer(stop_words=["一个", "一脸"]) # stop_words不指定特征词
# 2、调用fit_transform():先学习(即“拟合”)字典中的键作为特征名,然后将 data 列表中的字典转换为 NumPy 数组
data_final = transfer.fit_transform(data_new)
print("出现的次数:", data_final.toarray()) # toarray()转换二维数组
print("特征名字:", transfer.get_feature_names_out())
return None
def cut_word(text):
# jieba.cut()返回的是一个生成器,将其转换为列表,join将列表中的每个词语用空格连接起来
return " ".join(list(jieba.cut(text)))
if __name__ == '__main__':
count_chinese_dome()
TF-IDF TfidfVectorizer


# 通过计算词频(Term Frequency, TF)和逆文档频率(Inverse Document Frequency, IDF)的乘积来转换文本数据
from sklearn.feature_extraction.text import TfidfVectorizer
def tfidf_demo():
data = ["lift is short, i like like python", "lift is too long, i dislike python"]
# 实例化一个转换器
transfer = TfidfVectorizer() # 拟合和转换二维数组
# 2、调用fit_transform():先学习(即“拟合”)字典中的键作为特征名,然后将 data 列表中的字典转换为 NumPy 数组
data_new = transfer.fit_transform(data)
print("数值越大说明该词更重要:\n", data_new.toarray()) # toarray()转换二维数组
print("特征名字:", transfer.get_feature_names_out())
if __name__ == '__main__':
tfidf_demo()
特征预处理
无量纲化
-
定义:无量纲化是指通过某种数学变换,将原始数据转换为无量纲的数值,以便进行后续的数据分析和机器学习建模。
-
目的:
-
消除不同量纲的影响,使得所有特征在数值上处于同一量级,便于算法处理。
-
提高模型的收敛速度和性能,防止某些特征因量纲过大或过小而对模型产生过大的影响。
-
归一化 MinMaxScaler
from sklearn.preprocessing import MinMaxScaler
-
归一化是将原始数据线性变换到[0,1]区间(或其他指定区间)内。其公式为:xnor**m=xmax−xminx−x**min,其中x**min和xmax分别是样本的最小值和最大值。
-
优点:简单易行,能够保持数据的原始分布形态,对于小数据集或需要保留稀疏矩阵特性的情况较为适用。
-
缺点:当新数据加入时,最大值和最小值可能会发生变化,需要重新计算归一化参数。


# MinMaxScaler 将特征缩放到给定的最小值和最大值之间(默认:0~1)
from sklearn.preprocessing import MinMaxScaler
import pandas as pd
def min_max_scaler():
data = pd.read_csv('./clean_day2.csv').loc[:1000, ["hightest_tem", "lowest_tem"]]
# 1、实例化转换器
transfer = MinMaxScaler(feature_range=(2, 3)) # 指定特征范围
# 2、调用fit_transform():先学习(即“拟合”)字典中的键作为特征名,然后将 data 列表中的字典转换为 NumPy 数组
data_new = transfer.fit_transform(data)
print("统一规格(二维数组):\n", data_new)
if __name__ == '__main__':
min_max_scaler()
标准化 StandardScaler
from sklearn.preprocessing import StandardScaler
-
标准化是将特征值转换为均值为0,标准差为1的正态分布形式。其公式为:xnor**m=σ**x−μ,其中x是原始数据,μ是样本均值,σ是样本标准差。
-
优点:能够反映数据分布的离散程度,对于符合正态分布或数据量较大的情况更为有效。
-
缺点:对异常值敏感,且会改变原始数据的分布结构,不适合稀疏数据。

# StandardScaler 所有特征的尺度一致,从而提高算法的收敛速度。
from sklearn.preprocessing import StandardScaler
import pandas as pd
def stand_demo():
data = pd.read_csv('./clean_day2.csv').loc[:1000, ["hightest_tem", "lowest_tem"]]
# 1、实例化转换器
transfer = StandardScaler()
# 2、调用fit_transform():先学习(即“拟合”)字典中的键作为特征名,然后将 data 列表中的字典转换为 NumPy 数组
data_new = transfer.fit_transform(data)
print("统一规格(二维数组):\n", data_new)
if __name__ == '__main__':
stand_demo()
特征降维
特征选择
from sklearn.feature_selection import VarianceThreshold
低方差过滤 VarianceThreshold


# VarianceThreshold 删除低方差的一些特征
from sklearn.feature_selection import VarianceThreshold
import pandas as pd
def Variance_demo():
data = pd.read_csv('./clean_day2.csv').loc[:1000, ["hightest_tem", "lowest_tem"]]
# 1、实例化转换器
transfer = VarianceThreshold(threshold=5) # 特征(列)的方差如果低于5,该特征将在转换过程中被移除
# 2、调用fit_transform():先学习(即“拟合”)字典中的键作为特征名,然后将 data 列表中的字典转换为 NumPy 数组
data_new = transfer.fit_transform(data)
print("统一规格(二维数组):\n", data_new, data_new.shape)
if __name__ == '__main__':
Variance_demo()
相关系数 pearsonr
特征与特征之间的相关程度
from scipy.stats import pearsonr
# 计算两个变量之间的皮尔逊相关系数(介于-1和1之间:越大相关性越强)
from scipy.stats import pearsonr
import pandas as pd
def pearsonr_demo():
data = pd.read_csv('./clean_day2.csv').loc[:1000, ["hightest_tem", "lowest_tem"]]
print("相关系数:\n", pearsonr(data["hightest_tem"], data["lowest_tem"]))
if __name__ == '__main__':
pearsonr_demo()
主成分分析 PCA
from sklearn.decomposition import PCA

# PCA通过正交变换将可能相关的变量转换为一组线性不相关的变量
from sklearn.decomposition import PCA
def pca_demo():
data = [[26, 39, 48, 57], [16, 25, 33, 41], [13, 22, 34, 24], [41, 25, 43, 40]]
# 1、实例化转换器
transfer = PCA(2) # 保留 2 个主成分
# 2、调用fit_transform():先学习数据的主成分,然后将数据转换到这些主成分构成的新空间中
data_new = transfer.fit_transform(data)
print("二维数组:\n", data_new, data_new.shape)
if __name__ == '__main__':
pca_demo()
分类算法
估计器 estumator
-
实例化一个estimator
-
estimator.fit(x_train, y_train) 计算--模型生成
-
模型评估:
-
直接比对真实值和预测值
y_priedict = estimator.predict(x_test) y_test == y_predict
-
计算准确度
score = estimator.score(x_test, y_test)
-
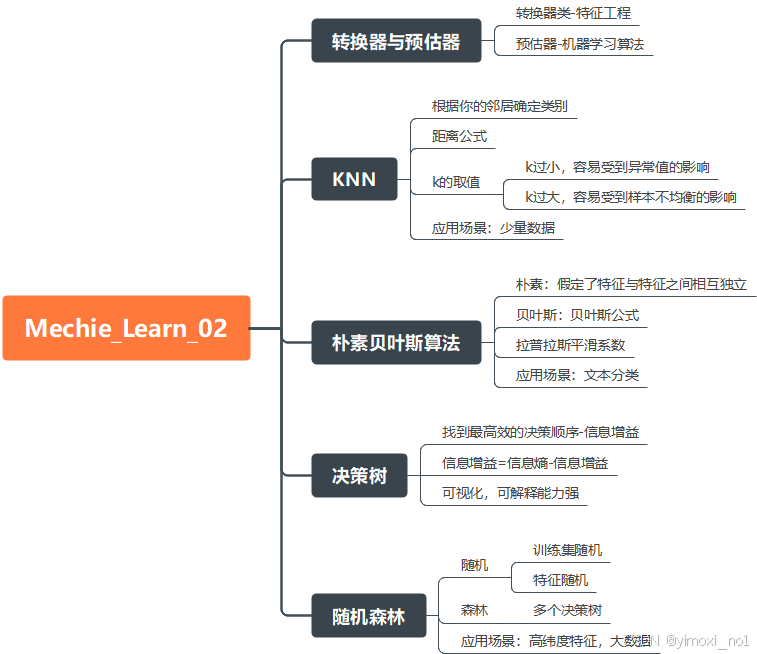
K-近邻算法(KNN)

分类任务KNeighborsClassifier
-
预测一个离散的类别标签。
-
例如,根据邮件内容判断是否为垃圾邮件、根据图像特征判断图像中的物体类别等。
# 用于实现K近邻分类
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 用于特征缩放,即将特征值缩放到均值为0,标准差为1的分布中
from sklearn.preprocessing import StandardScaler
# 网格搜索与验证
from sklearn.model_selection import GridSearchCV
def knn_iris():
# 1、获取数据
iris = load_iris()
# 2、划分数据集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=22)
# 3、特征工程:标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4、KNN算法预估器
estimator = KNeighborsClassifier()
# 加入网格搜索与交叉验证
# 参数准备(需找合适的邻近k值)
param_dict = {"n_neighbors": [1, 3, 5, 7, 9, 11]}
estimator = GridSearchCV(estimator, param_grid=param_dict, cv=10) # cv使数据更精确:常用10
estimator.fit(x_train, y_train)
# 5、模型评估
# 方法1、直接对比真实值和预测值
y_pred = estimator.predict(x_test)
print(y_pred)
print("直接对比真实值和预测值:", y_test == y_pred)
# 方法2、计算准确度
score = estimator.score(x_test, y_test)
print("计算准确度:", score)
# 最佳参数
print("最佳参数:", estimator.best_params_)
# 最佳结果
print("最佳结果:", estimator.best_score_)
# 最佳估计器
print("最佳估计器:", estimator.best_estimator_)
# 交叉验证结果
print("交叉验证结果:", estimator.cv_results_)
if __name__ == '__main__':
knn_iris()
回归任务KNeighborsRegressor
-
预测一个连续的数值。
-
例如,预测房价、股票价格或气温等。
模型选择与调优API
交叉验证 GridSearchCV


# 用于实现K近邻分类
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 用于特征缩放,即将特征值缩放到均值为0,标准差为1的分布中
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import GridSearchCV
def knn_iris():
# 1、获取数据
iris = load_iris()
# 2、划分数据集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=22)
# 3、特征工程:标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4、KNN算法预估器
estimator = KNeighborsClassifier()
# 加入网格搜索与交叉验证
# 参数准备
param_dict = {"n_neighbors": [1, 3, 5, 7, 9, 11]}
estimator = GridSearchCV(estimator, param_grid=param_dict, cv=10)
estimator.fit(x_train, y_train)
# 5、模型评估
# 方法1、直接对比真实值和预测值
y_pred = estimator.predict(x_test)
print(y_pred)
print("直接对比真实值和预测值:", y_test == y_pred)
# 方法2、计算准确度
score = estimator.score(x_test, y_test)
print("计算准确度:", score)
# 最佳参数
print("最佳参数:", estimator.best_params_)
# 最佳结果
print("最佳结果:", estimator.best_score_)
# 最佳估计器
print("最佳估计器:", estimator.best_estimator_)
# 交叉验证结果
print("交叉验证结果:", estimator.cv_results_)
if __name__ == '__main__':
knn_iris()
朴素贝叶斯算法 fetch_20newsgroups


# 新闻数据集
from sklearn.datasets import fetch_20newsgroups
# 导入朴素贝叶斯算法
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
def nb_news():
# 获取数据
news = fetch_20newsgroups(subset='all')
# 划分数据集
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target)
# 特征提取:文本特征提取:tfidf
transfer = TfidfVectorizer()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 朴素贝叶斯算法预估器
estimator = MultinomialNB()
estimator.fit(x_train, y_train)
# 模型评估
# 方法1、直接对比真实值和预测值
y_pred = estimator.predict(x_test)
print(y_pred)
print("直接对比真实值和预测值:", y_test == y_pred)
# 方法2、计算准确度
score = estimator.score(x_test, y_test)
print("计算准确度:", score)
if __name__ == '__main__':
nb_news()
决策树 DecisionTreeClassifier
作用:高效进行决策
优点:可解释能力强
缺点:容易产生过拟合

from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
# 导入决策树模块和可视化决策树模块
from sklearn.tree import DecisionTreeClassifier, export_graphviz
def tree_iris():
# 1、获取数据集
iris = load_iris()
# 2、划分数据集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)
# 3、决策树预估器
estimator = DecisionTreeClassifier()
estimator.fit(x_train, y_train)
# 4、模型评估
# 方法1、直接对比真实值和预测值
y_pred = estimator.predict(x_test)
print(y_pred)
print("直接对比真实值和预测值:", y_test == y_pred)
# 方法2、计算准确度
score = estimator.score(x_test, y_test)
print("计算准确度:", score)
# 5、可视化决策树
export_graphviz(estimator, out_file="iris_tree.dot", feature_names=iris.feature_names)
if __name__ == '__main__':
tree_iris()
随机森林预测 RandomForestClassifier
优点:极好准确率,处理具有高维持特征的输入样本,不需要降维

from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import GridSearchCV
def random_forest():
# 1、获取数据集
iris = load_iris()
# 2、划分数据集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)
# 3、决策树预估器
estimator = RandomForestClassifier()
# 加入网格搜索与交叉验证
# 参数准备(需找合适的邻近k值)
param_dict = {"n_estimators": [120, 200, 300, 500, 800, 1200]}
estimator = GridSearchCV(estimator, param_grid=param_dict, cv=3) # cv使数据更精确:常用10
estimator.fit(x_train, y_train)
# 4、模型评估
# 方法1、直接对比真实值和预测值
y_pred = estimator.predict(x_test)
print(y_pred)
print("直接对比真实值和预测值:", y_test == y_pred)
# 方法2、计算准确度
score = estimator.score(x_test, y_test)
print("计算准确度:", score)
# 最佳参数
print("最佳参数:", estimator.best_params_)
# 最佳结果
print("最佳结果:", estimator.best_score_)
# 最佳估计器
print("最佳估计器:", estimator.best_estimator_)
# 交叉验证结果
print("交叉验证结果:", estimator.cv_results_)
if __name__ == '__main__':
random_forest()
回归与聚类算法
线性回归
-
线性关系一定是线性模型
-
线性模型不一定是线性关系
优化方法:
-
正规方程(小规模数据):不能解决拟合问题

-
梯度下降(大规模数据)

-
回归性能评估:均方误差

# 导入正规方程和梯度下降
from sklearn.linear_model import LinearRegression, SGDRegressor
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_diabetes
from sklearn.preprocessing import StandardScaler
# 导入回归性能评估:均方误差
from sklearn.metrics import mean_squared_error
def linear_1():
"""
正规方程
:return:
"""
# 1、获取数据集
diabetes = load_diabetes()
print("特征数量:", diabetes.data.shape[1])
# 2、数据集划分
x_train, x_test, y_train, y_test = train_test_split(diabetes.data, diabetes.target, random_state=22)
# 3、特征工程-标准化
transfer = StandardScaler()
t_train = transfer.fit_transform(x_train)
t_test = transfer.transform(x_test)
# 4、预估器
estimator = LinearRegression()
estimator.fit(x_train, y_train)
# 5、得出模型
print("正规方程权重系数:", estimator.coef_)
print("正规方程偏置为:", estimator.intercept_)
# 6、模型评估
y_pred = estimator.predict(x_test)
print("预测:\n", y_pred)
error = mean_squared_error(y_test, y_pred)
print("正规方程-均方误差为:\n", error)
def linear_2():
"""
梯度下降
:return:
"""
print("*"*100)
# 1、获取数据集
diabetes = load_diabetes()
print("特征数量:", diabetes.data.shape[1])
# 2、数据集划分
x_train, x_test, y_train, y_test = train_test_split(diabetes.data, diabetes.target, random_state=22)
# 3、特征工程-标准化
transfer = StandardScaler()
t_train = transfer.fit_transform(x_train)
t_test = transfer.transform(x_test)
# 4、预估器
estimator = SGDRegressor(learning_rate="constant", eta0=0.01, max_iter=10000) # 增加 max_iter 以改善拟合,帮助算法更好地收敛.
estimator.fit(x_train, y_train)
# 5、得出模型
print("梯度下降权重系数:", estimator.coef_)
print("梯度下降偏置为:", estimator.intercept_)
# 6、模型评估
y_pred = estimator.predict(x_test)
print("预测:\n", y_pred)
error = mean_squared_error(y_test, y_pred)
print("梯度下降-均方误差为:\n", error)
if __name__ == '__main__':
linear_1()
linear_2()
欠拟合与过拟合
-
欠拟合

-
过拟合



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









