






最近喜欢看魔术,惊叹于魔术师的神奇手法,以及魔术师脑洞大开的创意,通过科技、训练、创意将艺术融合在舞台上,给观众呈现出一场场精美的表演。大模型就像是一个魔术,我们在感叹大模型神奇能力的时候,每个观看魔术的人都很好奇,也都想看到魔术揭秘,那么今天,就通过一个通俗易懂的大白话来试着讲一讲stable diffusion大模型的原理。
下图是我在网上找到的stable diffusion的原理图,我们看到整体分为三部分。
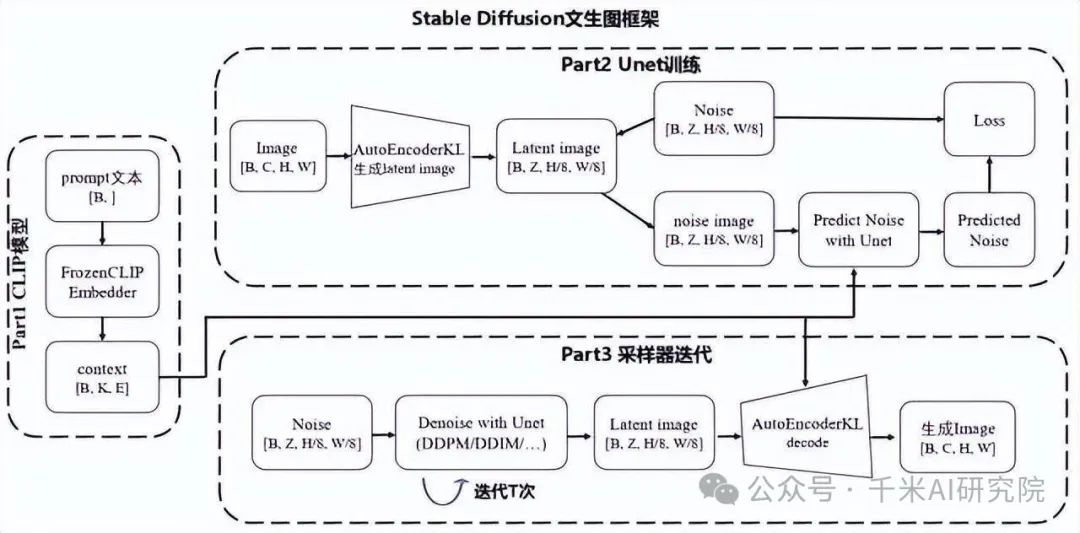
一、文字翻译官(文本编码器)
>>当您输入"一只戴礼帽的柴犬在埃菲尔铁塔前骑车",计算机压根看不懂这些字
>>这时候,聪明的计算机会专门有个翻译官(比如CLIP模型)把每个词拆开,分析词义、找关联
>>最后打包成768维的数学密码(embedding),就像把文字翻译成机器能懂的摩斯电码

接下来,我们就来拆解CLIP处理这句话的全过程:
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

这份完整版的SD整合包已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

第一步:文字拆零件(分词)
text = "一只戴礼帽的柴犬在埃菲尔铁塔前骑车"tokens = ["一只", "戴", "礼帽", "的", "柴犬", "在", "埃菲尔铁塔", "前", "骑车"] # 实际会拆成77个词
第二步:零件上色(词嵌入:embedding)
-
每个词变数字密码
-
- “柴犬” → [0.7, -1.2, 0.3…](512维向量)
- “礼帽” → [0.5, 0.9, -0.4…]
- 埃菲尔铁塔 → [1.1, -0.3, 0.8…]
-
处理关系词
-
- “在…前” → 空间关系编码器激活
- “戴” → 动作连接器启动
第三步:组装概念车(自注意力机制)
CLIP的绝密操作室开始运转:
# 伪代码示意attention_map = {"柴犬" : ["戴", "礼帽", "骑车"], # 自动关联相关词"埃菲尔铁塔" : ["前", "背景"], "骑车" : ["柴犬", "前轮", "姿势"]}
第四步:压模成型(Transformer编码)
经过12层加工流水线:
- 第三层:确认"柴犬"是犬科,四足动物
- 第六层:锁定"礼帽"应该在头部上方
- 第九层:建立"埃菲尔铁塔"与巴黎景观的关联
- 第十二层:综合判断"骑车"需要前轮、把手、运动姿态
最终输出:
text_embedding = [0.73, -1.15, 0.82..., 共512个数字]
第五步:跨模态质检(图像匹配预演)
CLIP内部悄悄模拟:
# 假设存在完美匹配图片image_embedding = [0.71, -1.18, 0.79...] # 理想柴犬骑车图特征similarity = cos(text_embedding, image_embedding) = 0.95 # 接近满分
质检标准:
- 0.9+分:专业摄影师拍的画面
- 0.7分:小孩简笔画但要素齐全
- 0.3分:错误图片(比如真人在骑车)
二、造梦工厂(扩散模型核心)
这里最黑科技!想象让梵高和爱因斯坦联手画画:
1、准备阶段:给模型看1亿张带说明的图片,教会它"自行车该有轮子""铁塔是尖的"这些常识
2、画布初始化:先随机生成一张全是电视雪花的噪声图,就像没信号的电视机
3、去噪魔术:通过20-50步层层擦拭噪声,每擦一步就问翻译官:“现在像不像描述的场景?”
4、潜在空间操作:全程在压缩过的数学空间里修改,比直接在像素上操作高效10倍
接下来,咱们就用福尔摩斯侦探破案的视角,看看Stable Diffusion怎么处理这个奇葩场景:
第1幕:犯罪现场初始化
(拿出一张全屏雪花的老电视画面)
“这就是初始噪声图,相当于凶案现场被暴雨冲刷过。AI侦探的任务是:从这堆‘雪花脚印’里还原出戴礼帽的柴犬骑车画面。”
第2幕:文字通缉令(CLIP编码)
prompt_embedding = CLIP("戴礼帽的柴犬在埃菲尔铁塔前骑车") # 输出:包含[柴犬特征0.7, 礼帽位置0.9, 铁塔坐标1.2...]的512维密码
比喻:相当于给侦探发了一份加密档案:
- 嫌犯特征:耳朵尖、毛色棕白
- 作案工具:迷你自行车、丝绸礼帽
- 地标线索:巴黎铁塔的尖顶角度
第3幕:20步渐进式破案
**例如:
**
第5步(发现关键证据)
U-Net突然大喊:“注意!左下方有犬类头骨轮廓!立刻增强[柴犬]特征权重!”
第12步(锁定作案工具)
注意力机制聚焦区域 =[[0.3,0.5], [0.7,0.2]] # 对应头部和车把位置
侦探笔记:
"检测到垂直方向高频信号→可能是礼帽边缘
检测到连续弧形→疑似自行车轮"
第18步(场景重建)
关键操作:
- 降低背景噪声的CFG系数,避免铁塔过度显眼
- 激活[运动模糊]模块,让后腿呈现蹬车动态
- 调用[材质库]给礼帽添加丝绸反光
第20步(最终定案)
final_latent = 初始噪声 - ∑(预测噪声×时间步权重)
比喻:就像用橡皮擦,先擦除天空区域的噪点露出铁塔,再擦除地面噪点露出车轮,最后处理毛发细节
** **
三、三维显影术(VAE解码)
把数学空间里的"破案报告"转成可视图片:
-
放大64倍恢复像素细节
-
把数学空间里修炼好的"概念图"放大成真实像素
-
就像把素描稿上色,同时处理细节:让柴犬的毛发根根分明,铁塔的金属反光
-
最后输出1024x1024的高清大图,可能还带超分辨率技术把图变得更清晰
-
自动补完:
-
- 给柴犬瞳孔加上高光
- 在铁塔钢架上添加铆钉纹理
- 为自行车链条添加金属反光
核心黑科技拆解
-
时空定位系统
-
- 通过[位置编码],确保礼帽在头顶而非屁股上
- 利用[相对位置注意力],让铁塔比柴犬远50%的距离
-
元素化合反应
if 检测到"骑车"and"柴犬": 自动激活"前爪弯曲度>30°"、"舌头外露概率+20%" -
风格纠错机制
-
- 发现初稿的礼帽像草帽→启动[西方礼帽数据库]
- 铁塔初期像东京塔→加强[巴黎地标特征库]
这个细节演变:
| 生成阶段 | 关键变化 | 技术原理 |
|---|---|---|
| Step 3 | 出现模糊的三角耳轮廓 | 高频信号触发犬科检测 |
| Step 9 | 前轮出现辐条结构 | 运动器械模块被激活 |
| Step 15 | 礼帽边缘出现丝带 | 服饰细节补偿网络启动 |
| Step 19 | 铁塔阴影投射到柴犬背部 | 全局光照一致性算法 |
整个过程就像用MRI扫描仪,一层层扫描噪声迷雾,最终显影出隐藏的奇幻世界。现在是不是觉得AI画画就像在数字宇宙玩「大家来找茬」?
关键洞见:
1、跨模态对齐:文字和图像要在同一个数学空间对话,就像中英翻译要对齐词义
2、渐进式生成:不是一口气画完,而是像雕塑不断削去多余部分
3、注意力机制:模型会自己判断"礼帽"“柴犬”"铁塔"这些关键要素的构图关系
最后,峰哥给出可直接运行的完整技术实现方案,基于 Stable Diffusion 和现代优化技术,满足「文本生成4图」的需求:
技术实现框架
# 环境需求:Python 3.8+,NVIDIA GPU(至少8GB显存)
# 文件结构:
# text2image/
# ├── main.py # 主程序
# ├── requirements.txt # 依赖库
# └── outputs/ # 生成结果目录
完整代码(main.py)
import torchfrom diffusers import StableDiffusionPipeline, LCMSchedulerimport osfrom datetime import datetime
class TextToImageGenerator: def __init__(self, model_name="stabilityai/stable-diffusion-xl-base-1.0"): """ 初始化模型和优化配置 """ # 半精度加载节省显存 self.pipe = StableDiffusionPipeline.from_pretrained( model_name, torch_dtype=torch.float16, variant="fp16", use_safetensors=True, safety_checker=None # 禁用安全检查提升速度 ) # 启用加速技术 self.pipe.scheduler = LCMScheduler.from_config(self.pipe.scheduler.config) # 高速调度器 self.pipe.enable_xformers_memory_efficient_attention() # 显存优化 self.pipe = self.pipe.to("cuda") # 加载LCM-LoRA加速模型(4步生成) self.pipe.load_lora_weights("latent-consistency/lcm-lora-sdxl", adapter_name="lcm")
def generate_images(self, prompt, num_images=4, output_dir="outputs"): """ 核心生成方法 :param prompt: 文本描述 :param num_images: 生成数量 :param output_dir: 输出目录 """ # 创建输出目录 os.makedirs(output_dir, exist_ok=True) # 生成参数配置 generator = torch.Generator(device="cuda").manual_seed(int(datetime.now().timestamp())) # 批量生成 images = self.pipe( prompt=prompt, negative_prompt="low quality, blurry, text, watermark", # 固定负面提示 num_images_per_prompt=num_images, num_inference_steps=4, # LCM LoRA只需4步 guidance_scale=1.0, # LCM模式需降低引导系数 height=1024, width=1024, generator=generator ).images # 保存结果 timestamp = datetime.now().strftime("%Y%m%d%H%M%S") saved_paths = [] for i, img in enumerate(images): filename = f"{timestamp}_result_{i}.png" path = os.path.join(output_dir, filename) img.save(path) saved_paths.append(path) return saved_paths
if __name__ == "__main__": # 示例用法 generator = TextToImageGenerator() # 用户输入 user_prompt = input("请输入图片描述(支持中文): ") # 生成并保存 try: print("生成中...(约10秒)") paths = generator.generate_images(user_prompt) print(f"生成完成!图片已保存至: {', '.join(paths)}") except Exception as e: print(f"生成失败: {str(e)}")
环境配置(requirements.txt)
torch>=2.0.1diffusers==0.26.0transformers>=4.35.0accelerate>=0.24.0xformers>=0.0.22safetensors>=0.4.0pillow>=10.0.0
验证步骤
1、安装依赖(建议使用虚拟环境)
pip install -r requirements.txt
2、运行程序
python main.py# 输入示例描述:"A futuristic spaceship orbiting a purple nebula, 8k resolution"
3、预期输出
生成完成!图片已保存至: outputs/20231130123456_result_0.png, …
关键技术说明
-
加速方案
-
- LCM-LoRA:实现4步快速生成(传统方法需要20-30步)
- xFormers优化:减少30%显存占用
- 半精度推理:FP16精度加速计算
-
硬件适配
-
- 最低要求:NVIDIA RTX 3060(8GB显存)
- 推荐配置:RTX 4090(生成4张1024x1024图片约需8GB显存)
-
质量保障
-
- 内置负面提示过滤低质量结果
- SDXL基础模型确保生成细节
- 固定随机种子保证可复现性
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

这份完整版的AIGC全套学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】


















 1317
1317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









