






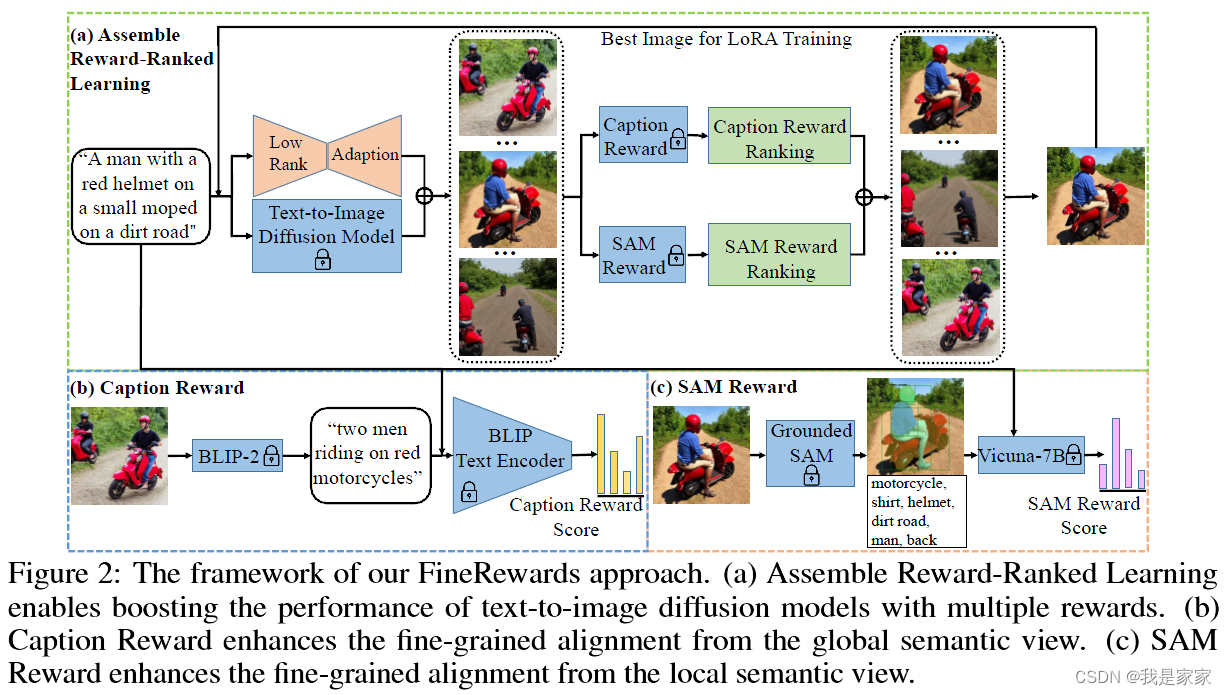
由于缺乏成功诊断模态差异的精细语义指导,以前的方法无法在文本概念和生成的图像之间执行准确的模态对齐。因此,提出FineRewards,在文本到图像diffusion模型中提高文本和图像间的对齐,这里引入两个Fine-grained semantic rewards: the caption reward and the semantic segmentation anything reward.
1. Caption reward: 从全局语义的角度来看,Caption reward是通过 BLIP-2 模型生成相应的详细字幕,描述合成图像中的所有重要内容,然后通过测量生成的字幕与给定提示之间的相似度来计算奖励分数。
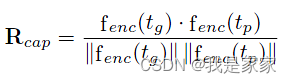
2. SAM reward: 从局部语义的角度来看,SAM 奖励将生成的图像分割成带有类别标签的局部部分,并通过大型语言模型(即 Vicuna-7B)测量每个类别出现在提示场景中的可能性来对分割的部分进行评分。

框架图:
The text-to-image model is finetuned through Low-rank Adaptation,这里的diffusion model用了连个作为base models: Stable diffusion v1.5 和Stable diffusion v2.1.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









