



 Tip-Adapter是一种基于CLIP的小样本分类技术,无需额外训练。它使用小样本集构建适配器,通过多模态cache模块存储视觉和文本知识,更新CLIP的先验信息,实现与训练方法相当的性能。
Tip-Adapter是一种基于CLIP的小样本分类技术,无需额外训练。它使用小样本集构建适配器,通过多模态cache模块存储视觉和文本知识,更新CLIP的先验信息,实现与训练方法相当的性能。
Tip-Adapter: Training-free Adaption of CLIP for Few-shot Classification
提出利用CLIP,不用训练的自适应方法,进行小样本分类。它不仅继承了零样本CLIP的不用训练优势,而且性能与那些需要训练的方法相当。。
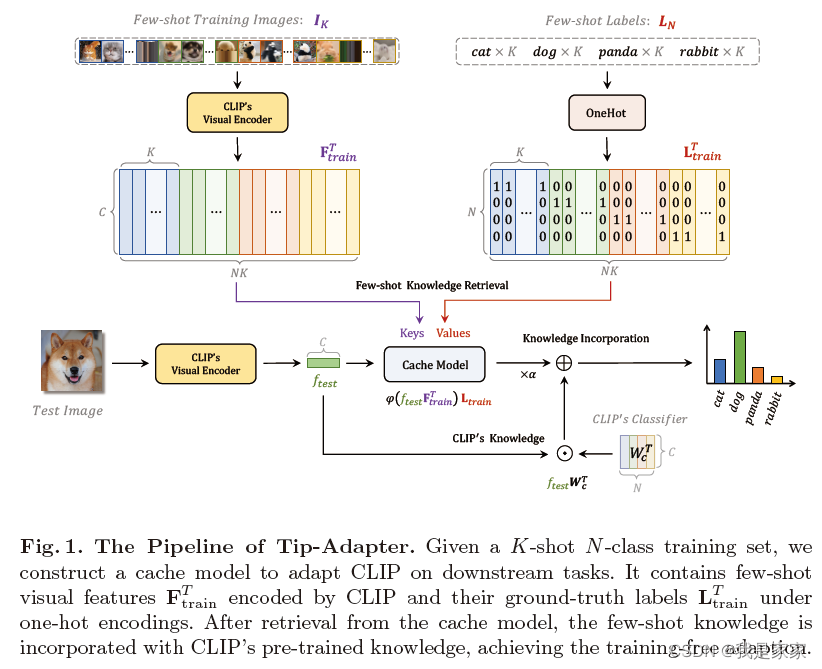
Tip-Adapter 方法是利用小样本训练集中的键值缓存模型构建适配器,并通过特征检索更新 CLIP 中编码的先验知识。
对于小样本数据集,利用CLIP提取视觉特征表示,利用one-hot编码真值标签。
在KQV机制下的cache模型,并整合CLIP预训练的知识信息,进而完成小样本分类任务。
框架图:
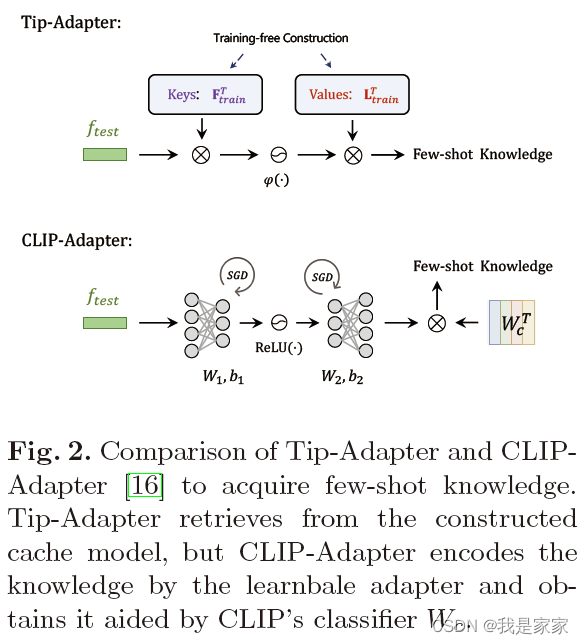
所提出的方法和CLIP-Adapter相比:
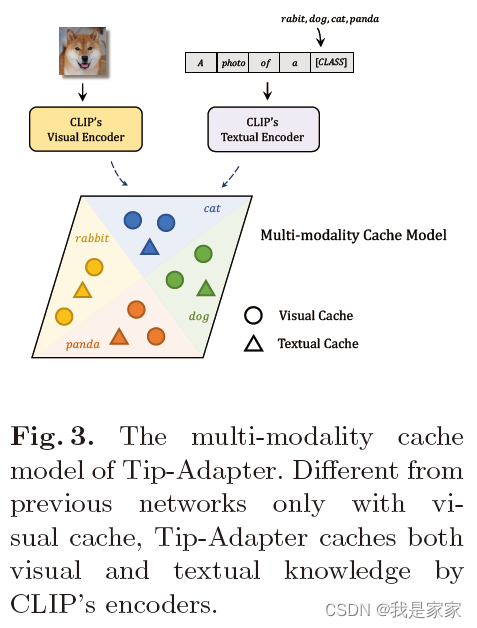
多模态cache模块,能够暂存CLIP编码出来的视觉和文本知识。

















 1316
1316

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









