




通过注入语义概念到图像标记(inject semantic concepts into image tagging),提出识别一切+的模型(Recognize anything plus model, RAM++), 一个具有强的开集识别能力的图像识别模型。
RAM++模型能够利用图像-标签-文本三者之间的关系,整合image-text alignment 和 image-tagging 到一个统一的交互框架里。
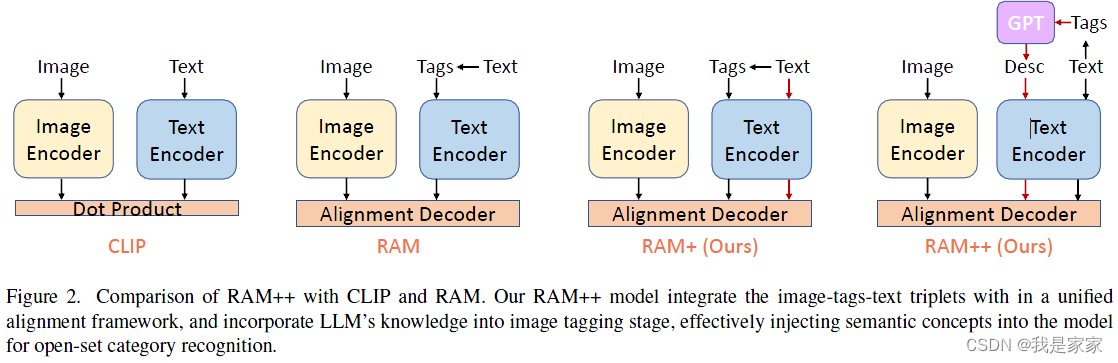
框架图:
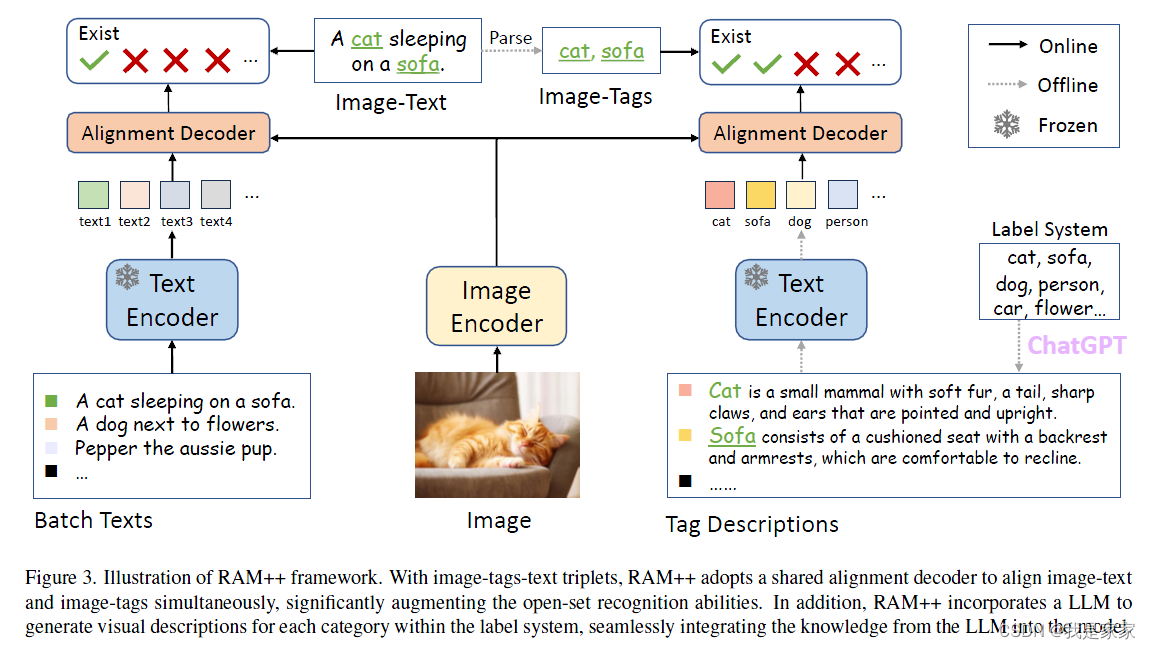
 RAM++模型通过将语义概念注入图像标记,结合图像、标签和文本的关系,构建了一个强大的图像识别系统,能在一个统一的交互框架中执行image-textalignment和image-tagging任务。
RAM++模型通过将语义概念注入图像标记,结合图像、标签和文本的关系,构建了一个强大的图像识别系统,能在一个统一的交互框架中执行image-textalignment和image-tagging任务。
通过注入语义概念到图像标记(inject semantic concepts into image tagging),提出识别一切+的模型(Recognize anything plus model, RAM++), 一个具有强的开集识别能力的图像识别模型。
RAM++模型能够利用图像-标签-文本三者之间的关系,整合image-text alignment 和 image-tagging 到一个统一的交互框架里。
框架图:
 1976
2512
2万+
1976
2512
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























