 随机森林RF算法详解与优缺点分析
随机森林RF算法详解与优缺点分析





 本文详细介绍了bagging算法,特别是随机森林(RF)算法,包括其原理、步骤和优缺点。随机森林通过并行训练多个决策树,采用随机抽样和特征选择来降低模型的方差,增强泛化能力。该算法适用于处理高维数据,能评估特征重要性,并对部分特征缺失不敏感。然而,过多的特征划分可能影响模型效果,且在某些噪声大的数据集上可能过拟合。
本文详细介绍了bagging算法,特别是随机森林(RF)算法,包括其原理、步骤和优缺点。随机森林通过并行训练多个决策树,采用随机抽样和特征选择来降低模型的方差,增强泛化能力。该算法适用于处理高维数据,能评估特征重要性,并对部分特征缺失不敏感。然而,过多的特征划分可能影响模型效果,且在某些噪声大的数据集上可能过拟合。
bagging算法(随机森林RF算法简介)
bagging算法特点是各个弱学习器之间没有依赖关系,可以并行拟合。加快计算速度。那么,bagging算法其实是一种工程思维,真正把这个思维转换成可以应用于工程计算的就是随机森林算法
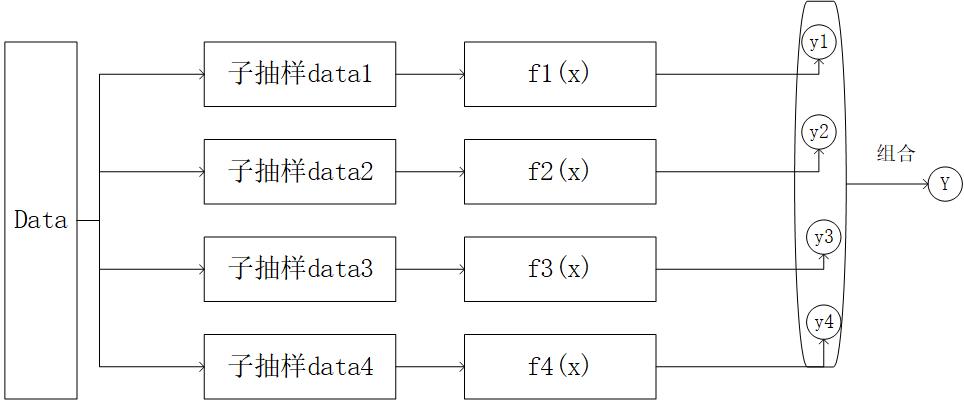
通过上图我们知道,bagging是每个弱学习器之间的并行计算最后综合预测,但是,有一个问题需要我们注意,在训练集到子训练器的过程叫做“子抽样”。
这个子抽样是一个“随机有放回采样”,随机有放回采样(bootsrap)是从训练集里面采集固定个数的样本,每采集一个样本后,都将样本放回。之前采集到的样本在放回后有可能继续被采集到。
对于Bagging算法来讲,一般都会随机采集和训练集样本数m一样个数的样本。这样得到的采样集和训练集样本的个数相同,但是样本内容并不一定相同。以下说明为什么不一定相同:
如果对有m个样本训练集做T次的随机采样,则由于随机性,T个采样集各不相同。
一个样本,它在某一次含m个样本的训练集的随机采样中,每次被采集到的概率是1/m。不被采集到的概率为1 − 1/m。如果m次采样都没有被采集中的概率是
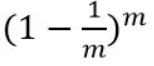
当m→∞时
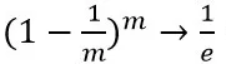
所以在bagging的每轮随机采样中,训练集中大约有37%的数据没有被采样集采集中。
因为样本被不断采样,然后不断的被放回,这样增加了样本的扰动能力,就是增加了泛化能力 bagging的集合策略也比较简单,对于分类问题,通常使用简单
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









