




 本文介绍了KMP算法用于在字符串中查找第一个匹配项,通过构建next数组和前缀表来优化暴力搜索的时间复杂度。同时讨论了前缀和后缀的概念,以及如何在重复子字符串检测中应用KMP算法。
本文介绍了KMP算法用于在字符串中查找第一个匹配项,通过构建next数组和前缀表来优化暴力搜索的时间复杂度。同时讨论了前缀和后缀的概念,以及如何在重复子字符串检测中应用KMP算法。
第九天字符串part02
LC28找出字符串中第一个匹配项的下标(未掌握)
- 暴力算法:时间复杂度O(M*N)
- KMP算法
- 作用:当字符串出现不匹配的情况,可以知道一部分之前已经匹配的文本内容,可以利用这些信息避免重头开始匹配
- 重点:如何记录已经匹配的文本内容(next数组)
- 前缀表:
- 作用:用来回退的,它记录了模式串与主串(文本串)不匹配的时候,模式串应该从哪里开始重新匹配
- 物理含义:下标{0}-{i}的字符串中,有多大长度的相同前缀后缀
- 前缀:不包含最后一个字符的所有以第一个字符开头的连续子串
- 后缀:不包含第一个字符的所有以最后一个字符结尾的连续子串
- 真实作用:aabaaf,当判断到f时,与主字符串中的字符不同,因为aabaa有两个相同长度的前缀后缀,因此可以直接跳到b
- next数组
- 前缀表(这样每次回退的时候就是回退到next[j]位置)
- 前缀表减一(这样每次回退的时候就是回退到next[j]+1位置)
- 前缀表右移一位,初始位置为-1
- 构造next数组(前缀表减一)
- 初始化
- 两个指针i和j,j指向前缀末尾位置,i指向后缀末尾位置
- j=-1
- next[0] = j
- for (int i = 1; i < s.size(); i++) :判断i位置和j+1位置
- 处理前后缀不同的情况:s[i]!=s[j+1],需要进行回退,j回退到next[j]
- 原因解释:
- {0}-{j}的前缀一定等于{i-j-1}-{i-1}的后缀,因为判断到了前缀结尾j和后缀结尾i,长度都为j+1
- {0}-{next[j]}的前缀一定等于{j-next[j]}-{j}的后缀,因为next[j]的物理含义决定(注意减了1),长度都为next[j]+1
- 因此有{0}-{next[j]}的前缀一定等于{i-next[j]-1}-{i-1}的后缀,长度都为next[j]+1
- 回退之后就是判断i和next[j]+1位置
- 原因解释:
- 处理前后缀相同的情况:s[i]==s[j+1],j++
- 最后next[i] = j
- 处理前后缀不同的情况:s[i]!=s[j+1],需要进行回退,j回退到next[j]
- 初始化
- 使用next数组进行匹配,双指针i和j,注意j从-1开始
- s[i] !=t[j + 1] ,j=next[j]
- s[i] ==t[j + 1],j++
- j指向了模式串t的末尾,j = =(t.size() - 1) 因为j从t.size() - 2变成t.size() - 1,此时i因为变成i+1,i+1-t.size(),return (i - t.size() + 1)
- 切记,先判断不等的情况,再判断相等的情况,不然相等了j++了i却没有++,会出现问题
- 错误代码
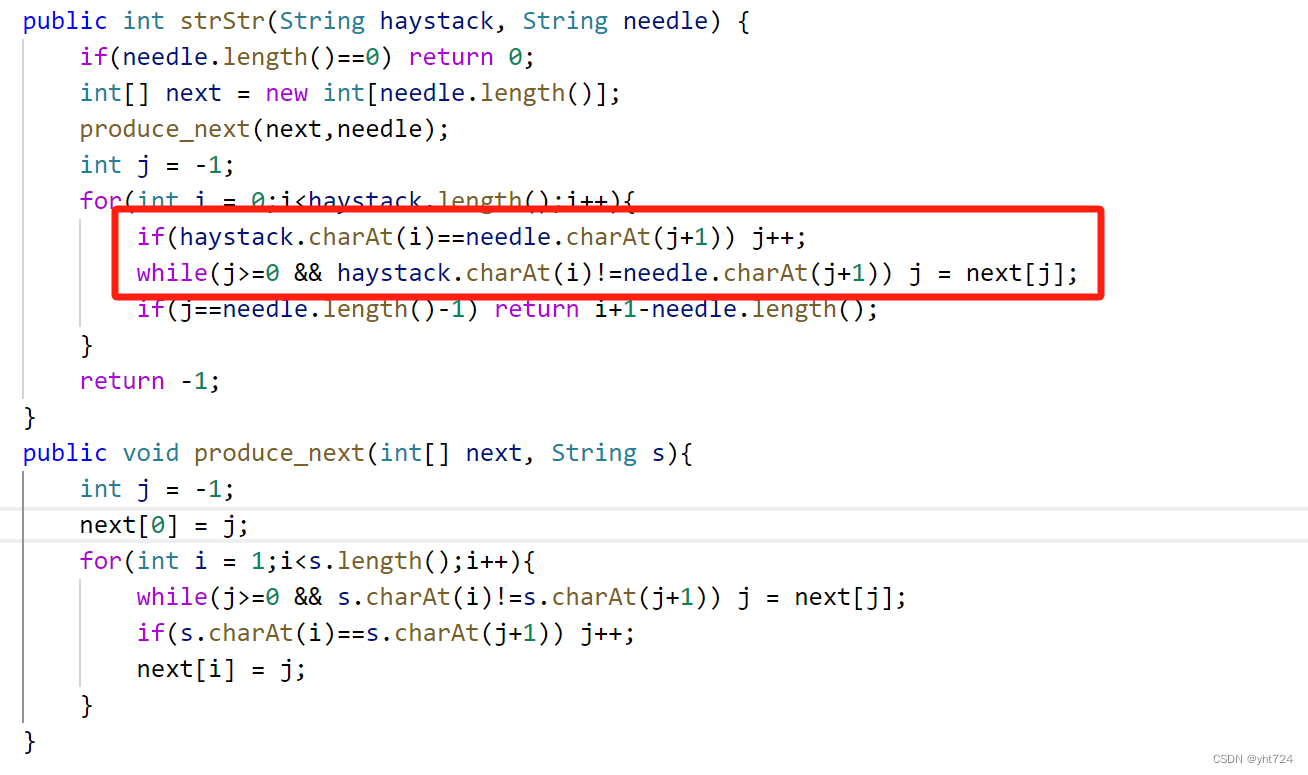
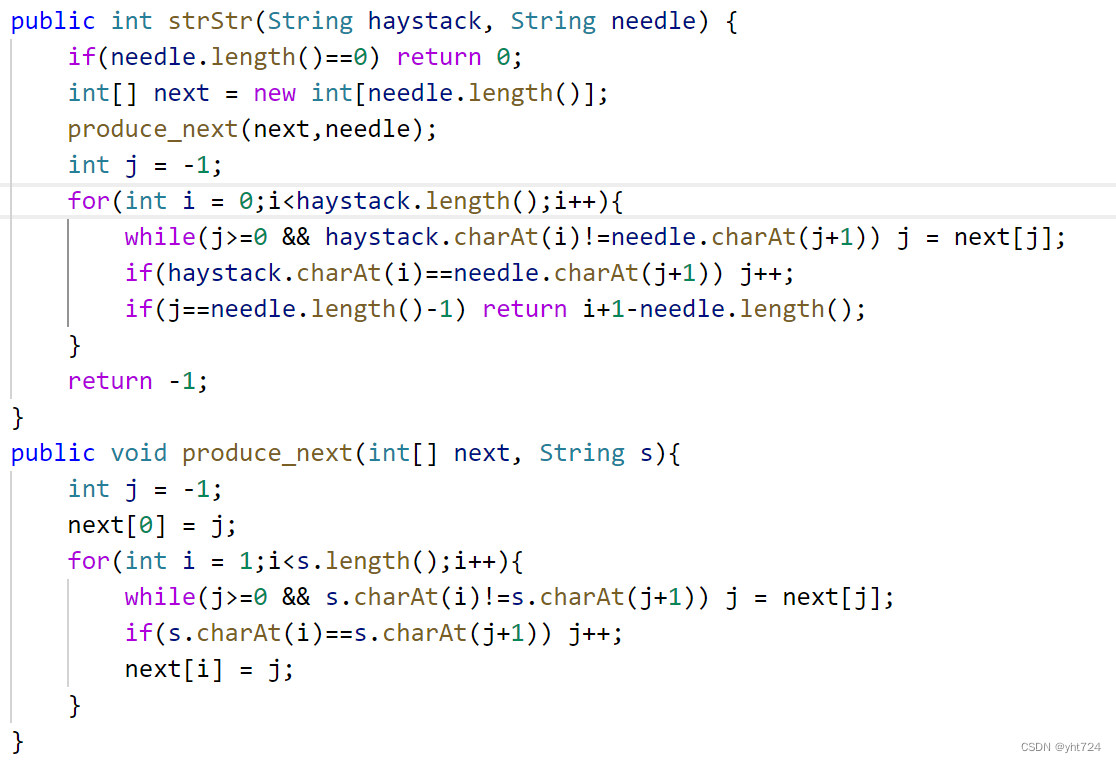
- 正确代码
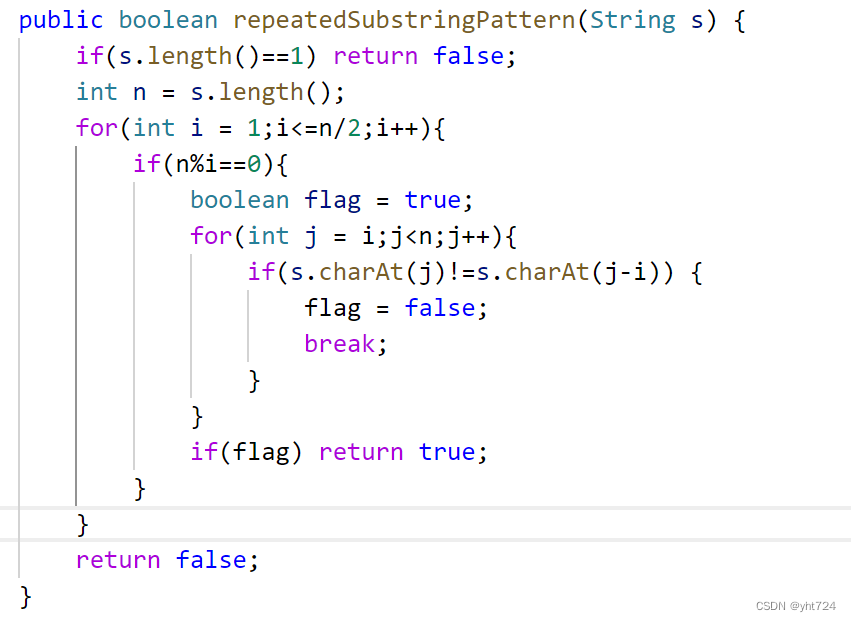
LC459重复的子字符串(未掌握)
- 思路:
- 一个长度为n的字符串M可以由长度为i的子串N组成,那么n一定是i的倍数即n%i==0
- 对于任意的j属于[i,n),一定有M[j]=M[j-i]
- 子串必须重复一次,因此i一定要小于等于n/2,只要有一个子串成功重复,就return true
- 代码
- KMP算法思想

- 代码
- 最后判断是否存在重复子串的判断条件要加上next[length-1]>=0,因为如果<0则说明最长重复前后缀长度<=0,就说明一定无重复子串
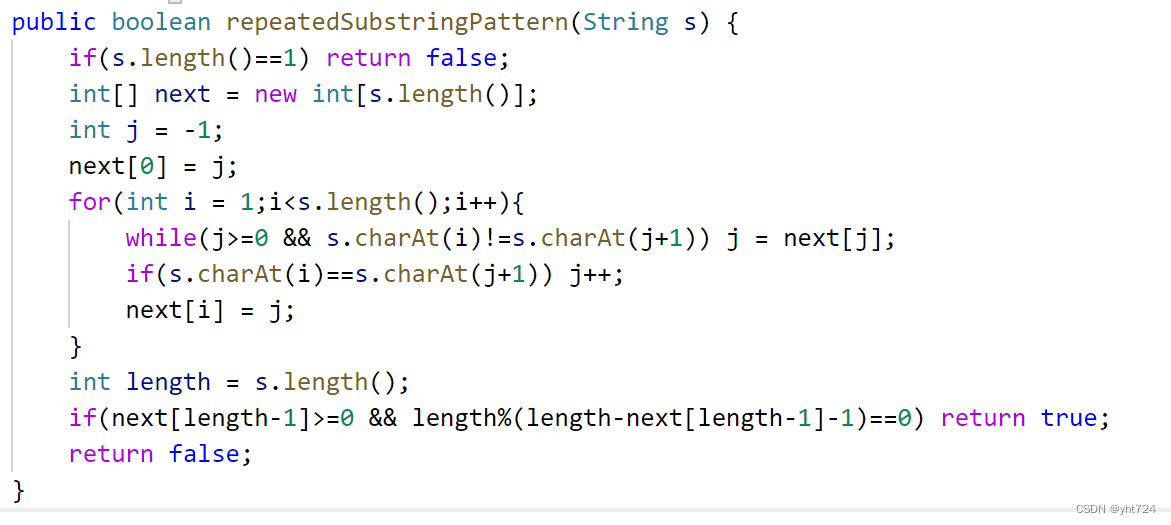
- 最后判断是否存在重复子串的判断条件要加上next[length-1]>=0,因为如果<0则说明最长重复前后缀长度<=0,就说明一定无重复子串
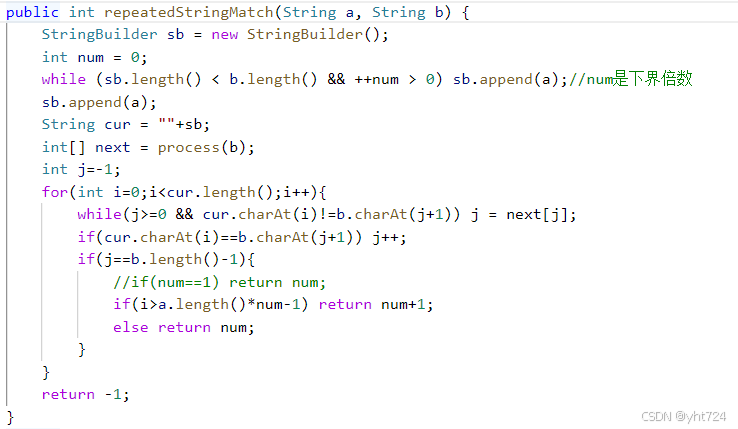
LC686重复叠加字符串匹配(KMP的拓展,未掌握)
- 本质是看将字符串a复制多少次才能够匹配子串b,因此可以先确定复制次数,最少是a.length()/b.length(),最多是a.length()/b.length()+2
- 使用StringBuild不容易搞错
- 最后还需要append(a)是为了保持上界字符串形式

- 如果最后j==b.length()-1,说明包含b子串,就需要判断此时i是否超过了num(下界倍数)*a.length(),超过了就return num+1,反之return num



















 941
941




 到【灌水乐园】发言
到【灌水乐园】发言







