







一、模型提出的背景,现有模型的不足
原来的RNN模型中,通过输入一个序列,再输出一个序列,序列的输出是有先后顺序的,说明RNN不能被并行化;
RNN不能并行,CNN可以,但是CNN不能捕捉长句子的上下文,于是有了self-attention。
二、模型改进的核心点在哪里
1)transformer的输出序列是同时计算,训练是并行的;
2)关键是可以用self-attention来取代RNN,
三、self-attention模型结构
Transfomer既不是CNN,也不是RNN,它就是一个具有多个注意力的前馈神经网络;
3.1 self-attention mechanism
input_X: [batch_size, seq_length, dim]
1) 线性变换
Q[batch_size, seq_length, dim] = input_X *Wq[dim, dim]
K[batch_size, seq_length, dim] = input_X *Wk[dim, dim]
V[batch_size, seq_length, dim] = input_X *Wv[dim, dim]
2) Q*Kt : 这个矩阵的物理意义就是序列中每个词与其他所有词的相关性,每一行代表当前词与其他词的相关性;
Q[batch_size, seq_length, dim]*KT[batch_size, dim, seq_length] = [batch_size, seq_length, seq_length]
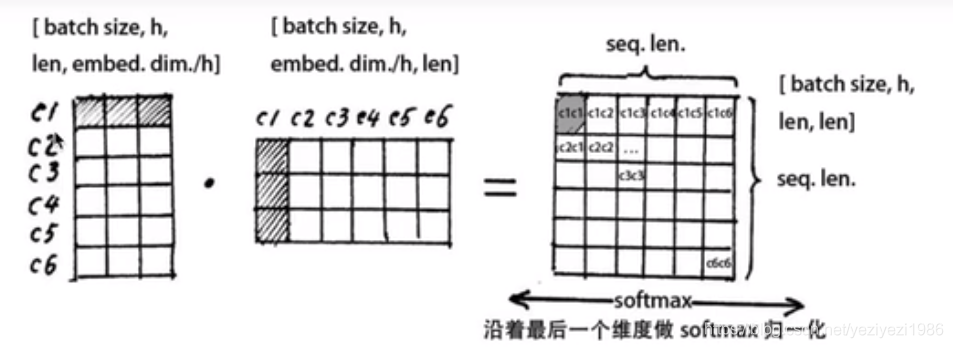
3)softmax归一化:softmax(Q*Kt/sqrt(dk))[batch_size, seq_length, seq_length],这个式子就是注意力矩阵
sqrt(dk)是为了把注意力矩阵变成标准正态分布,使得softmax归一化之后的结果更加稳定;
4)接下来,用注意力矩阵对V进行加权, softmax(Q*Kt/sqrt(dk))[batch_size, seq_length, seq_length] * V[batch_size, seq_length, dim] = [batch_size, seq_length, dim],
这一步矩阵乘法的物理意义是:使得每个词向量都含有当前句子内所有词向量的信息,求的是输入序列中每个单词与其他单词的关系;
Attention(Q,K,V) = softmax(Q*Kt/sqrt(dk))*V
意义,整体来说,这一步的输入是一个[batch_size, seq_length,dim]的词向量,输出的维度不变,但是输出矩阵的每个词向量都(注入进了)含有当前句子内所有词向量的信息。
这一步的trick,attention mask:
3.2 multi-head
将加权后的特征矩阵Zi按列拼接成一个大的特征矩阵,特征矩阵经过一层全连接后得到输出Z。
意义:多头注意力看上去是借鉴了CNN中同一卷积层内使用多个卷积核的思想,同时进行注意力的计算,彼此之间参数不共享,最终将结果拼接起来。这样可以模型在不同的表示子空间里学习到相关的信息。简而言之,就是希望每个head,只关注最终输出序列中的一个子空间,互相独立。其核心思想在于,抽取到更加丰富的特征信息。
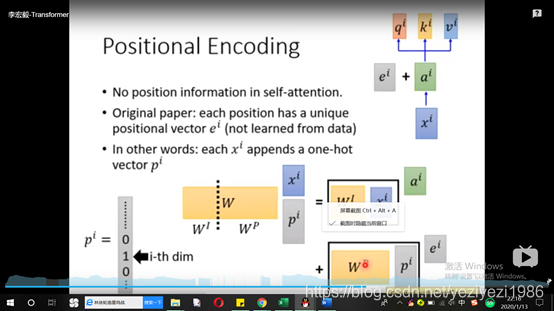
3.3 位置编码:
截止目前为止,我们介绍的transformer模型并没有捕捉序列的能力,无论句子的结构怎么打乱,transformer都会得到类似的结果。换句话说,它只是一个功能更加强大的词袋模型而已。为了解决这个问题,论文中在编码向量中加入了单词的位置信息,这样transformer就能区分不同位置的单词了。 具体怎么做:
3.4 mask self attention,什么是mask,怎么做
五、transformer整体结构
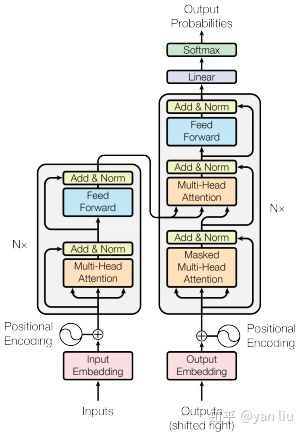
1)字向量与位置编码: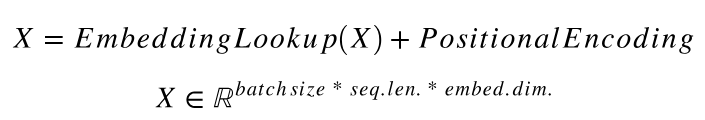
2)自注意力机制: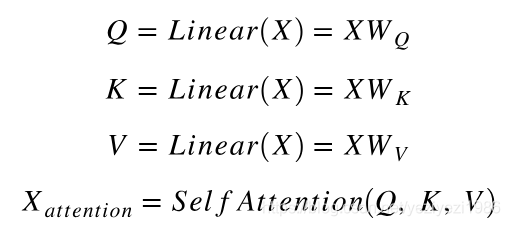
3)残差连接与Layer Normalization: 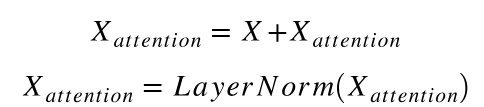
4)
FEED FORWARD层:这个全连接层有两个,第一层的激活函数是ReLU,第二层是一个线性激活函数;

















 2501
2501

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









