







 本文详细介绍了如何从零开始构建并训练FCN-16s网络,包括生成训练文件、修改网络结构、调整学习率等关键步骤。
本文详细介绍了如何从零开始构建并训练FCN-16s网络,包括生成训练文件、修改网络结构、调整学习率等关键步骤。
FCN-16s网络的训练,由于没有对应的源代码,所以一切的东西都要我们自己来做,官方提供了其他dataset的源代码,我们可以依照这些内容生成相应的训练文件.我们可以先比较一下voc-fcn16s和voc-fcn32s 相对应的net.py(用来生成.prototxt文件)代码:
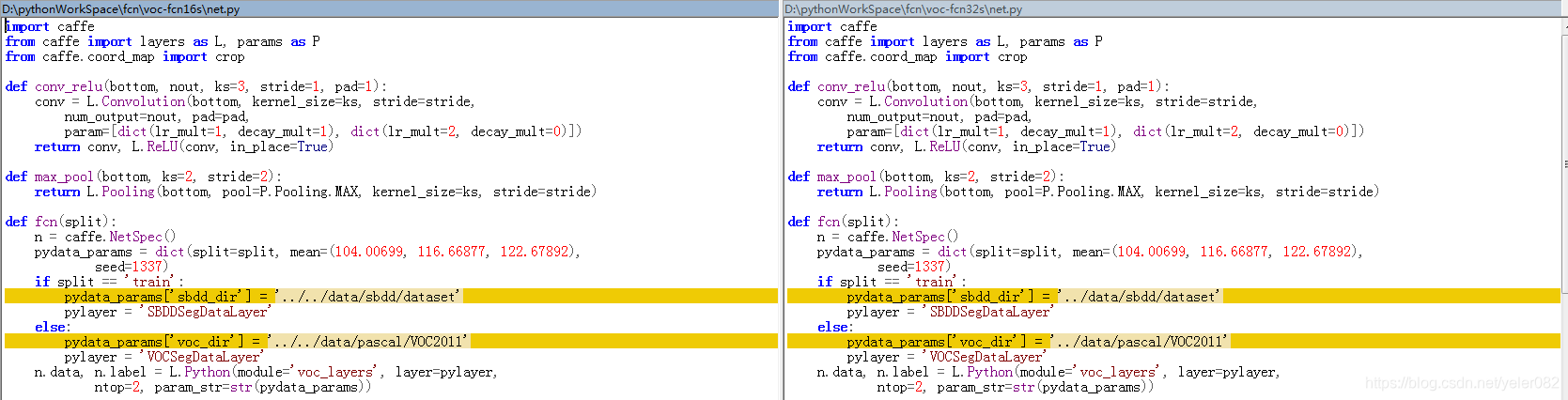
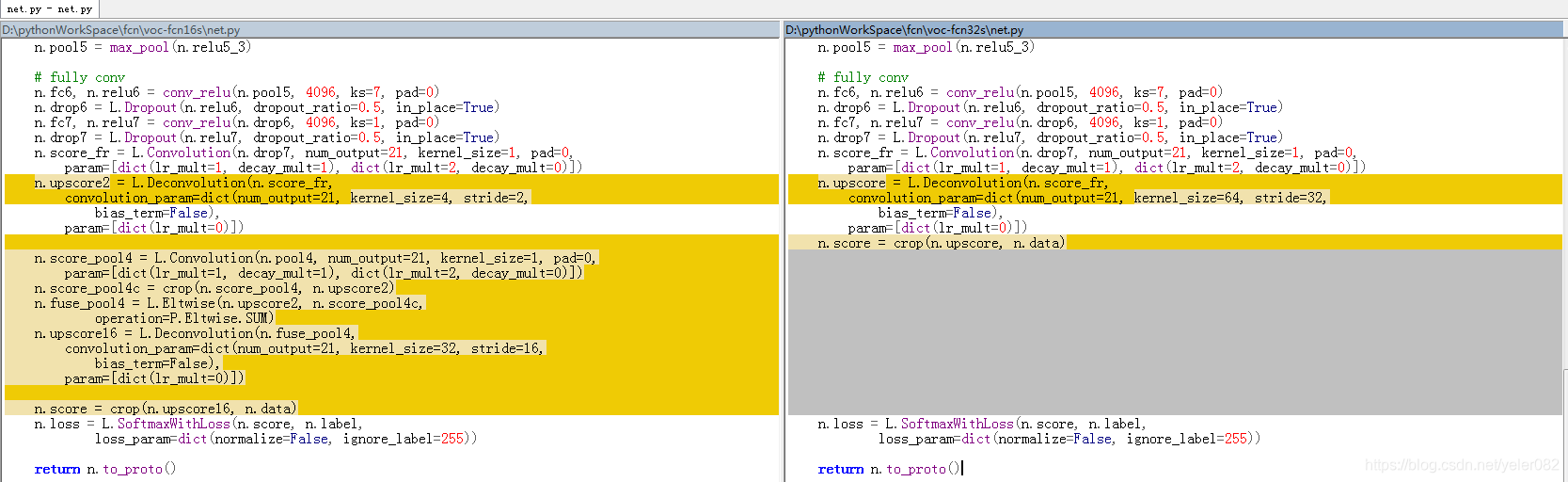
其中颜色标注的是代码的不同部分。对比两者的network结构可以清楚的看到区别,想要获取network,运行/caffe/python 文件夹下的draw_net.py文件。
所以我们可以根据上图对比的结构从nyud-fcn32s-color/net.py 修改得到新的net.py文件:
cd fcn.berkeleyvision.org
mkdir nyud-fcn16s-color
cp nyud-fcn32s-color/net.py nyud-fcn16s-color/net.py
运行net.py文件来生成.prototxt 文件:
cd nyud-fcn16s-color/
python net.py
复制并修改solve.py文件:
#!/usr/bin/env python
# encoding: utf-8
'''
@author: lele Ye
@contact: 1750112338@qq.com
@software: pycharm 2018.2
@file: solve.py
@time: 2019/1/2 17:21
@desc:nyud-fcn16s-color 网络结构的定义文件,目的是用于生成trainval.prototxt和test.prototxt文件
'''
CAFFE_ROOT = "/home/bxx-yll/caffe"
import sys
sys.path.insert(0, CAFFE_ROOT + '/python')
import caffe
import surgery, score
import numpy as np
import os
try:
import setproctitle
setproctitle.setproctitle(os.path.basename(os.getcwd()))
# 获得当前路径(返回最后的文件名)
# 比如os.getcwd()获得的当前路径为/home/zhangrf/fcn,则os.path.basename()为fcn;
# setproctitle是用来修改进程入口名称,如C++中入口为main()函数
except:
pass
# vgg_weights = '../ilsvrc-nets/VGG_ILSVRC_16_layers.caffemodel' # 用来fine-tune的FCN参数
# vgg_proto = '../ilsvrc-nets/VGG_ILSVRC_16_layers_deploy.prototxt' # VGGNet模型
# 这次我们用fcn32s的模型微调训练
weights = '../nyud-fcn32s-color/snapshot/train_iter_100000.caffemodel'
# init
# caffe.set_device(int(sys.argv[1]))
# 获取命令行参数,其中sys.argv[0]为文件名,argv[1]为紧随其后的那个参数
caffe.set_device(0) # GPU型号id,这里指定第三块GPU
caffe.set_mode_gpu()
solver = caffe.SGDSolver('solver.prototxt') # 调用SGD(随即梯度下降)Solver方法,solver.prototxt为所需参数
solver.net.copy_from(weights) # 这个方法仅仅是从vgg-16模型中拷贝参数,但是并没有改造原先的网络,这才是不收敛的根源
# surgeries
interp_layers = [k for k in solver.net.params.keys() if 'up' in k] # interp_layers为upscore层
surgery.interp(solver.net, interp_layers) # 将upscore层中每层的权重初始化为双线性内核插值。
# scoring
test = np.loadtxt('../data/nyud/test.txt', dtype=str) # 载入测试图片信息
for _ in range(50):
solver.step(2000) # 每2000次训练迭代执行后面的函数
score.seg_tests(solver, False, test, layer='score') # 测试图片
复制并修改solver.prototxt文件(主要是修改base_lr的值,也就是Learning rate):
train_net: "trainval.prototxt"
test_net: "test.prototxt"
test_iter: 200
# make test net, but don't invoke it from the solver itself
test_interval: 999999999
display: 20
average_loss: 20
lr_policy: "fixed"
# lr for unnormalized softmax
# 由于这次是微调,所以学习率变小
base_lr: 1e-12
# high momentum
momentum: 0.99
# no gradient accumulation
iter_size: 1
max_iter: 300000
weight_decay: 0.0005
snapshot: 5000
snapshot_prefix: "snapshot/train"
test_initialization: false

















 787
787

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









