



发表在KDD2024
Background:
随着社交媒体平台上如 TikTok、Triller 和 Instagram 等多模态用户生成内容(UGC)的激增,预测 UGC 的流行度变得至关重要,这对许多现实应用如在线广告、推荐、政府识别潜在舆论危机等都有重要意义。
Motivation:
- 现有方法在预测 UGC 流行度时,主要关注单个 UGC 的有限上下文信息,忽略了从相关 UGC 中挖掘有用知识的潜在益处。
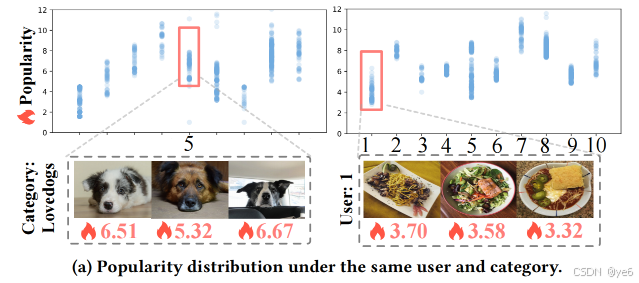
- 然而,在现实社交媒体中,即使是相同的 UGC,由于源用户的粉丝分布不同,其社交反馈也可能差异巨大,因此建模单个 UGC 提供的知识有限,可能导致预测错误。
- 人类具有通过观察相关事物来学习的能力,这启发作者通过检索相关 UGC 并利用其有意义的知识来增强 MSMPP 任务。
Challenges:
- 计算目标 UGC 与相关实例之间的相似性复杂,需要评估多模态相似性以识别 Top - K邻实例,且现有检索方法主要关注单模态知识编码和检索,无法有效利用多模态数据及其复杂相关性,同时社交媒体上的 UGC 通常包含大量噪声,如文本和视觉内容的差异以及不完整的模态信息。
- 目标 UGC 与检索实例之间的相关性通常是高阶的,现有方法通过求和或注意力操作来建模相关实例的邻域知识,无法有效建模这种复杂的高阶相关性。
Contributions:
• We propose RAGTrans, pioneering an aspect-aware retrieval augmented pipeline that bridges target multimodal UGCs and relevant instances to enhance the multimedia social media popularity prediction (MSMPP) task.
• We propose a bootstrapping hypergraph transformer that extends information aggregation to the multimodal mixture. Intra-modal and inter-modal propagations are designed to capture correlations within and across modalities as well as fine-grained and aligned UGC representations.
• We conduct extensive experiments on real-world multimodal datasets to evaluate RAGTrans. The results demonstrate that RAGTrans can effectively learn multimodal representations from visual and textual UGC modalities, and achieve up to a 20% gain over strong baseline approaches on the ICIP dataset. The code for reproducing the results is available at https://github.com/CZTAO12/RAGTrans
Related Works
- Feature-engineering
- deep-learning based
Methodology
问题定义:
C = {𝑐1, · · · , 𝑐𝑁 } 表示一系列社交媒体中的 user-generated content (UGC)
这些UGC包含 文本描述(t)与图片(v).
问题的目标是学习3种表示[ 文本表征,图片表征,用户表征]
真实流行度是用户对未来的总交互数,如转发、点赞和评论的数量。
超图的构造是由目标 UGC 在内存库中检索到的与其最接近的实例(对应超图中的点)构成,超边表示 UGC 的aspect information(如用户、类别)。
方法框架:
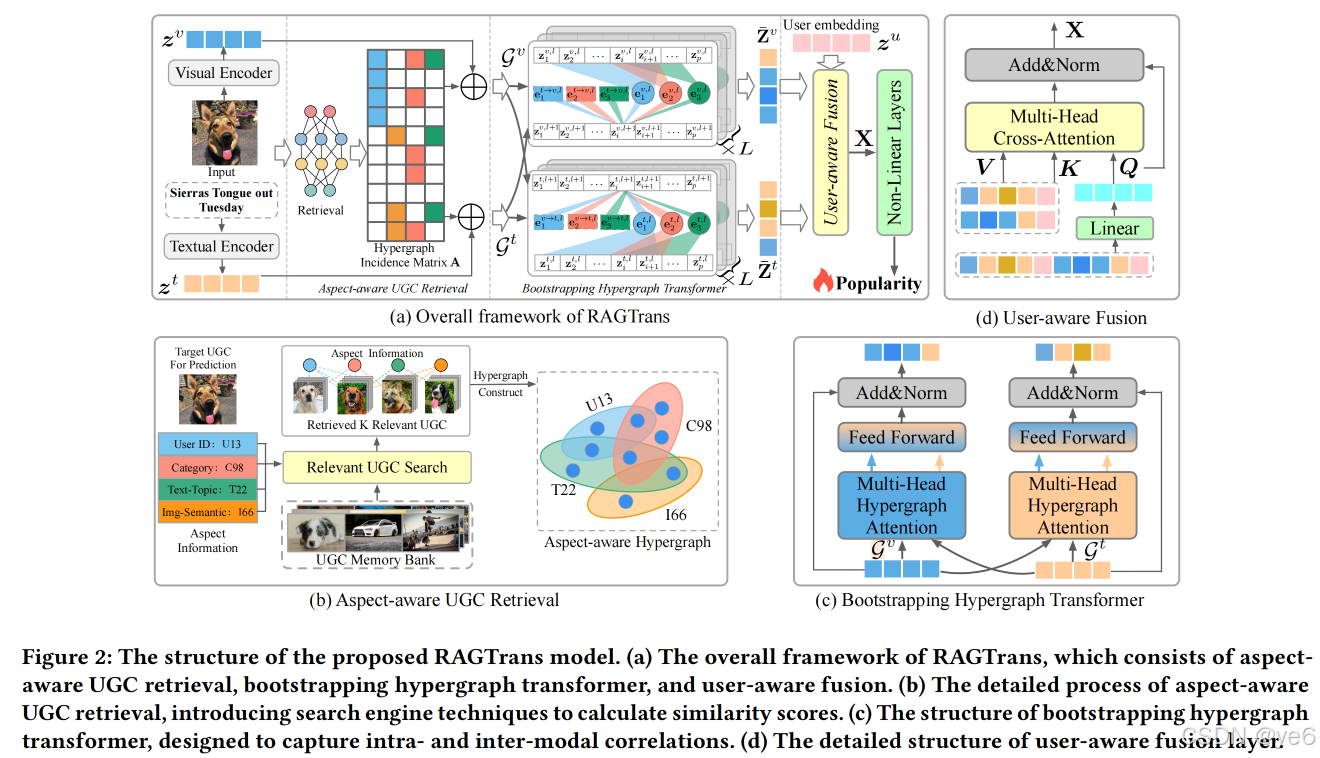
方法模块1:Aspect - aware UGC Retrieval
- 构建内存库:构建包含大量 UGC 的视觉、文本和方面信息的内存库,由 <图像、文本、方面> 三元组组成。
- 检索相关实例:将目标 UGC 作为查询,内存库中的每个 UGC 作为文档,通过计算方面信息的相似性分数,使用搜索引擎技术(elasticsearch)和排名函数(如 BM25)从内存库中检索 Top - K个最相关的 <图像、文本、方面> 三元组实例

方法模块2:Bootstrapping Hypergraph Transformer
1. Aspect-aware Multimodal Hypergraph Construction
把上一步检索到的实例转换为超图。根据𝑐𝑞的方面信息中的每个特性都构造了一个超边来连接所涉及的检索实例,以表示目标UGC和检索实例之间的相关高阶关系。
2. Intra-modal Propagation
BHT首先在单模态超图上传播,以捕获模态内邻域知识。这篇工作定义了两个操作:
节点->超边

其中注意力系数ajk注入了跨模态传播的信息,用于确保只有来自模态的最具影响力和信息性的消息能够传递到模态,计算公式在文章中。
超边->节点

3. Inter-modal Propagation
受到前缀调优的优点的启发,BHT将信息传播过程重构为前缀引导的多模态信息传播,以预先减少模态异质性,并捕获跨模态交互。
(这一部分给传播公式,但比较难对应到框架图中,读起来比较吃力难理解)
大概的作用是:
- 从文本模态节点-》图片模态超边
这里用到了前面提到的在视觉模态超边中的文本模态节点的 attention coefficient(a) .
- 从图片模态超边-》文本模态节点
4. Feed-forward Network (FFN)
为了缓解模态的异质性,并获得包括内部和多模态相关性在内的细粒度表示,文章合并了前缀引导的交互模块的相应输出特征.

方法模块3:User-Aware Fusion
对应上一个模块最终输出的两个模态输出的表征,将用户表征与它们分别做拼接。得到两个向量: T 和 V
注意力计算:将这两个表示投影到维度d作为query,使用视觉和文本表示作为key和value,输入到用户感知融合层进行注意力计算

Experiments
datasets:


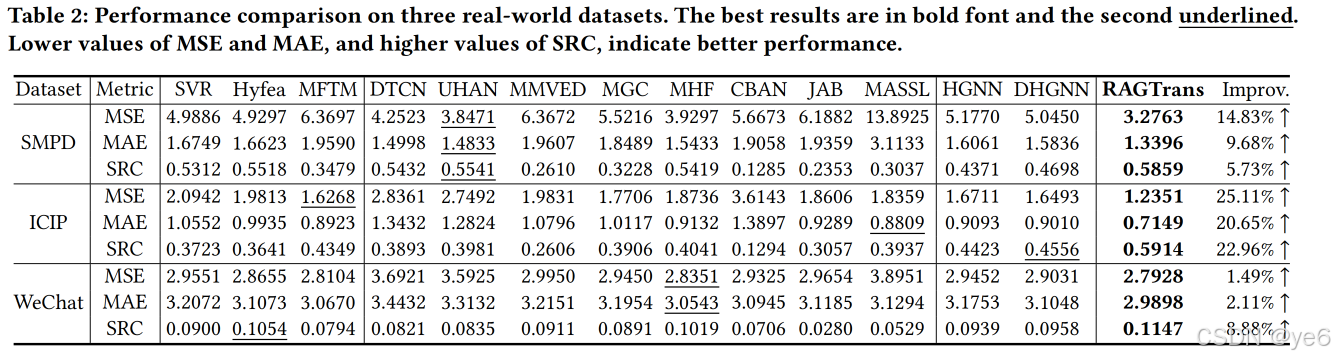
Overall performance
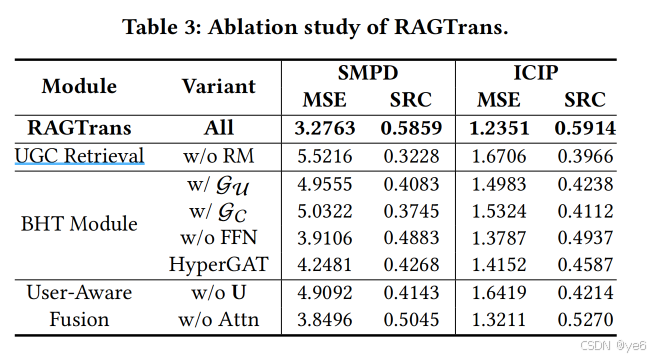
 Ablation experiments
Ablation experiments
Conclusions:
设计提出了RAGTrans-一种具有方面感知功能的检索增强的多模态超图转换器,以检索-预测的方式重新定义预测过程。


















 1924
1924



 到【灌水乐园】发言
到【灌水乐园】发言








