



 本文探讨了在社交媒体中检测异常用户,尤其是针对虚假信息和网络欺凌的挑战。作者提出了SeGA,一种基于用户偏好感知的自对比学习方法,通过伪偏好生成和自监督学习来识别不同恶意策略的用户。实验结果显示SeGA在Twitter基准测试中表现出色,证实了其有效性和模型设计。
本文探讨了在社交媒体中检测异常用户,尤其是针对虚假信息和网络欺凌的挑战。作者提出了SeGA,一种基于用户偏好感知的自对比学习方法,通过伪偏好生成和自监督学习来识别不同恶意策略的用户。实验结果显示SeGA在Twitter基准测试中表现出色,证实了其有效性和模型设计。
背景介绍:
社交媒体中检测异常用户的重要性,特别是针对恶意活动如虚假信息和网络欺凌。
挑战:
现有方法主要关注机器人检测,但难以捕捉用户、bot、trolls(人类控制,表现的更像normal user)之间微妙差异。
troll用户:
- 之前的工作虽然使用follower count作为自监督信号,但是troll用户可以模仿普通用户的follower count特征来避免被发现
- troll也是人类控制的,所以表现的更加像人。这启发文章利用LMM来分析用户的posts,提取user preferences来总结用户多方面的行为
提出的方法:
SeGA,一种偏好感知的自对比学习方法,利用Twittersphere中的异构实体和它们之间的关系来检测具有不同恶意策略的异常用户。
模型架构:
包括节点特征编码、预训练阶段和微调阶段,利用自对比学习学习用户偏好并分类异常用户。
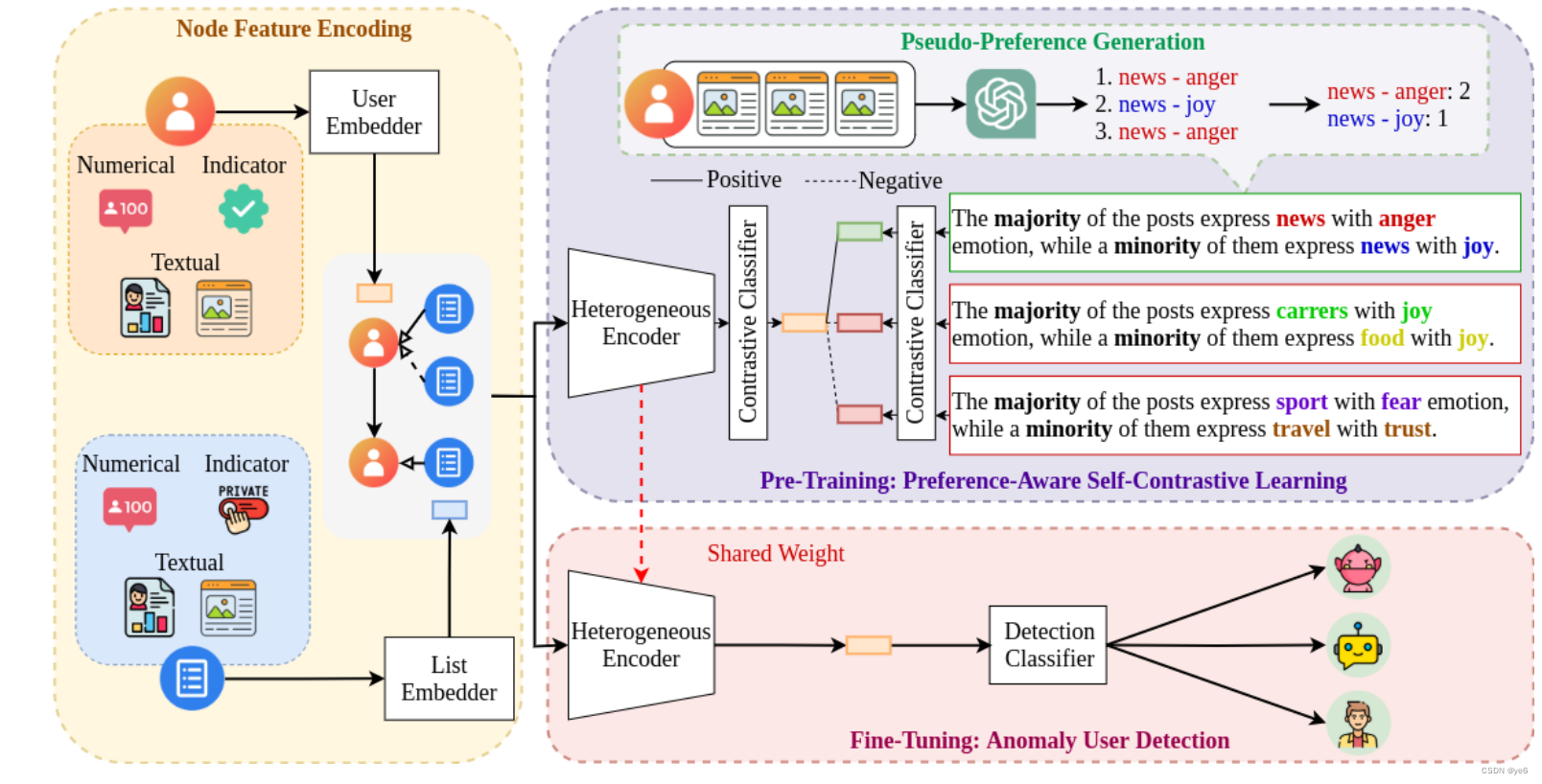
节点特征编码:
目的:构图与生成user embedding
为了对不同重要程度的实体及其关系进行建模,丰富用户嵌入; 文章使用RGT和一层MLP作为Heterogeneous encoder,输入user embedding和list embedding,输出融合了list embedding的user embedding。
自对比学习:
目的:通过偏好感知的自对比学习方法,结合提示信息来增强学习,以捕捉用户偏好。
做法:
- **伪偏好生成;**样本形式:主题-情感对 来代表每个用户在相应帖子中的偏好,因为异常用户可能会利用它们来实现恶意意图。对于用户的每条post使用LLM生成topic和emotion; topic(16类,来自twitter分类)与emotion(8类,来自文章)。
- **生成正负样本与自监督对比学习;**在获得每个用户的主题-情感对后,目标是用这个伪信息预先训练模型来描述用户的偏好。
文章定义的用户偏好是:最频繁的topic-emotion对与最少出现的topic-emotion对;
生成伪正负样本:
对于这些样本,文章设计类一个提示词模版,每个样本由该模板生产。
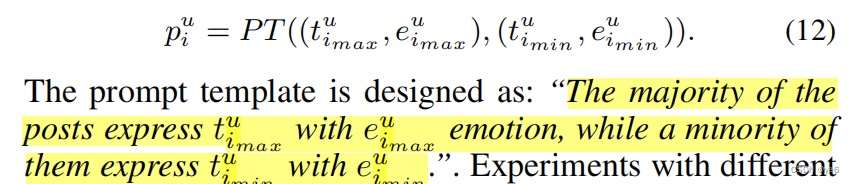
自监督对比学习部分:
文章定义了自监督对比的loss方法,过程就是拉近anchor(样本)与positive samples的距离;推远与负样本的距离。
微调阶段:
利用预训练模型中的用户嵌入来进行异常用户检测。
使用softmax函数+交叉熵与L2正则项。
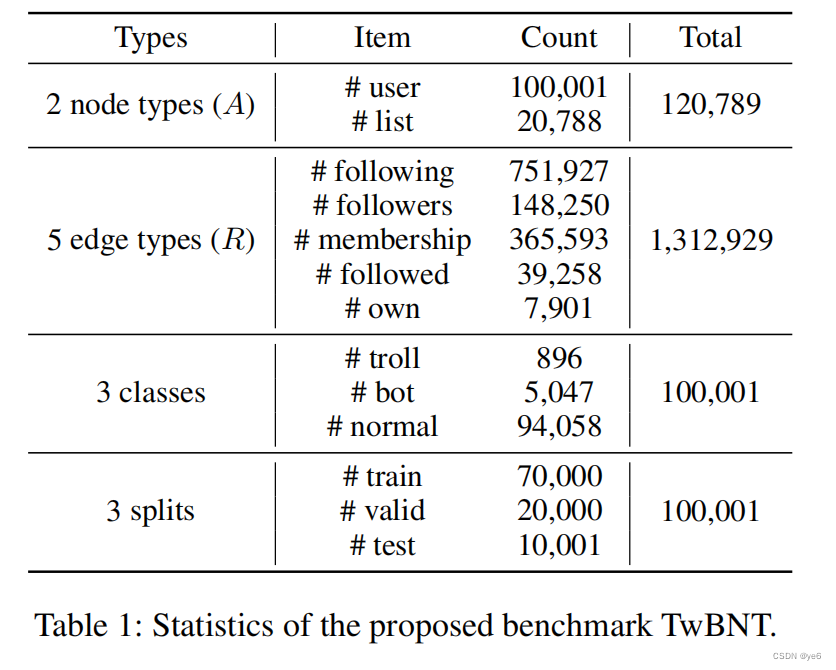
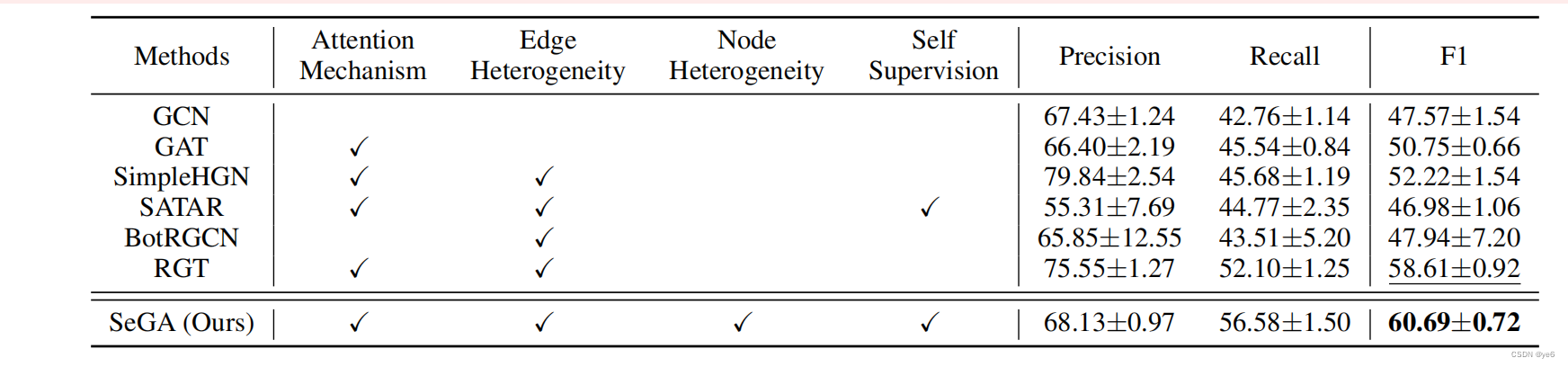
实验结果:
在TwBNT基准测试上,SeGA明显优于现有方
法,并验证了模型设计和预训练策略的有效性。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









