






1.latex中的引号:
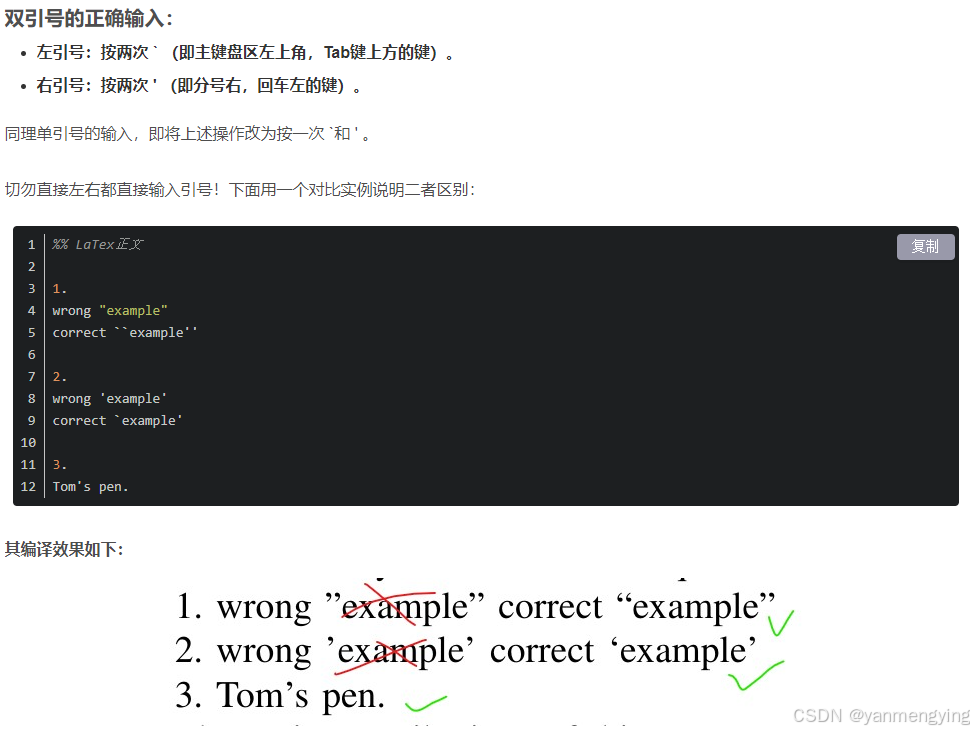
引自LaTex写英文论文时 如何输入单引号、双引号、省略号,及其他特殊符号_latex省略号-优快云博客
2.打特殊字符
& :\&
3.公式中的空格
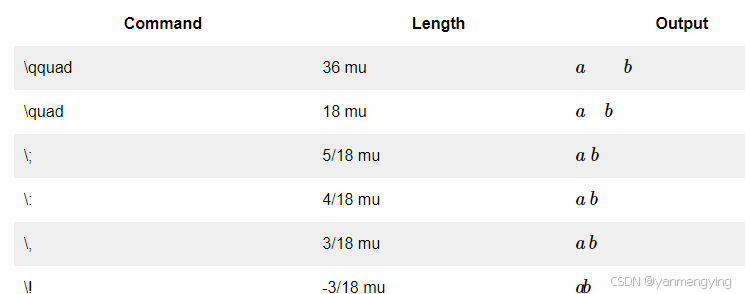
例:
 4.常用的希腊字母
4.常用的希腊字母
LaTeX中插入常用的希腊字母_latex输入希腊字母-优快云博客
5.表格中换行
首先在main.tex引入makecell包:
\usepackage{makecell}
之后,在表格中使用,方式如下:
\makecell[居中情况]{第1行内容 \\ 第2行内容 \\ 第3行内容 ...}
[居中情况] 包括 r,c,l,分别表示靠右、居中、靠左
例:

6.去掉当前日期:在document前面加入\date{}
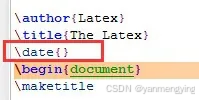
7.去掉首行缩进:在document前面加:
\setlength{\parindent}{0pt} % 设置段落缩进为0
8.加粗:\textbf{}
9.\item[] aaaaabbbbbb让本条前没内容,不加[]默认黑圈
10.正文中的数学表达式,要用$a_i$表示,打一些特殊字符用\加特殊字符表示(比如&:\&)

















 1059
1059

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









