







 本文深入探讨RabbitMQ的高级特性,包括TTL队列/消息、死信队列的原理与应用案例,以及Spring框架整合RabbitMQ的方法。同时介绍了SET部署策略,为大规模分布式系统的容灾和扩展提供了有效方案。
本文深入探讨RabbitMQ的高级特性,包括TTL队列/消息、死信队列的原理与应用案例,以及Spring框架整合RabbitMQ的方法。同时介绍了SET部署策略,为大规模分布式系统的容灾和扩展提供了有效方案。
RabbitMQ学习笔记
RabbitMQ进阶
TTL队列/消息
- TTL 是 Time To Live 的缩写,也就是生存时间。
- RabbitMQ 支持消息的过期时间,在消息发送时可以进行指定。
- RabbitMQ 支持队列的过期时间,从消息入队列开始计算,只要超过了队列的超时时间配置,那么消息会自动地清除。
案例demo
- 生产者:
public class Producer {
public static void main(String[] args) throws Exception {
// 1. 创建一个 ConnectionFactory 工厂
ConnectionFactory factory = new ConnectionFactory();
factory.setHost(RABBITMQ_HOST_IP);
factory.setPort(RABBITMQ_HOST_PORT);
factory.setVirtualHost(RABBITMQ_VIRTUAL_HOST);
// 2. 创建一个 Connection 连接
Connection conn = factory.newConnection();
// 3. 获取一个 Channel 信道
Channel channel = conn.createChannel();
// 4. 发送消息
String msg = "hello rabbitmq ttl";
Map<String, Object> headers = new HashMap<>();
headers.put("name", "yw");
AMQP.BasicProperties props = new AMQP.BasicProperties().builder()
// 设置编码为UTF8
.contentEncoding("UTF-8")
// 设置自定义Header
.headers(headers)
// 设置消息失效时间
.expiration("5000").build();
// 设置了消息超时时间为5秒, 5秒后消息自动删除
channel.basicPublish(RABBITMQ_TTL_EXCHANGE, RABBITMQ_TTL_ROUTING_KEY_PRODUCER, props, msg.getBytes());
// 没有设置消息存活时间,消息存活时间根据队列来决定
channel.basicPublish(RABBITMQ_TTL_EXCHANGE, RABBITMQ_TTL_ROUTING_KEY_PRODUCER, null, msg.getBytes());
}
}
- 消费者:
public class Consumer {
public static void main(String[] args) throws Exception {
// 1. 创建一个 ConnectionFactory 工厂
ConnectionFactory factory = new ConnectionFactory();
factory.setHost(RABBITMQ_HOST_IP);
factory.setPort(RABBITMQ_HOST_PORT);
factory.setVirtualHost(RABBITMQ_VIRTUAL_HOST);
// 2. 创建一个 Connection 连接
Connection conn = factory.newConnection();
// 3. 获取一个 Channel 信道
Channel channel = conn.createChannel();
// 4. 声明一个交换机
channel.exchangeDeclare(RABBITMQ_TTL_EXCHANGE, BuiltinExchangeType.TOPIC, true, false, null);
// 5. 声明&绑定队列
Map<String, Object> arguments = new HashMap<>();
// 设置队列超时时间为10秒
arguments.put("x-message-ttl", 10000);
channel.queueDeclare(RABBITMQ_TTL_QUEUE, true, false, false, arguments);
channel.queueBind(RABBITMQ_TTL_QUEUE, RABBITMQ_TTL_EXCHANGE, RABBITMQ_TTL_ROUTING_KEY_CONSUMER);
// 6. 手工签收。必须要关闭 autoAck =false
channel.basicConsume(RABBITMQ_TTL_QUEUE, false, new MyConsumer(channel));
}
}
- BaseInfo:
public interface BaseInfo {
String RABBITMQ_HOST_IP = "192.168.254.106";
int RABBITMQ_HOST_PORT = 5672;
String RABBITMQ_VIRTUAL_HOST = "/";
String RABBITMQ_TTL_EXCHANGE = "ttl-exchange";
String RABBITMQ_TTL_ROUTING_KEY_PRODUCER = "ttl.key";
String RABBITMQ_TTL_ROUTING_KEY_CONSUMER = "ttl.#";
String RABBITMQ_TTL_QUEUE = "ttl-queue";
}
死信队列
死信队列 DLX, Dead-Letter-Exchange
- 利用 DLX,当消息在一个队列中变成死信(dead message)之后,它能被重新 pulish 到另一个 Exchange,这个 Exchange 就是 DLX。
- DLX 也是一个正常的 Exchange,和一般的 Exchange 没有区别,它能在任何的队列上被指定,实际上就是设置某个队列的属性。
- 当这个队列中有死信时,RabbitMQ 就会自动的将这个消息重新发布到设置的 Exchange 上去,进而被路由到另一个队列。
- 可以监听这个队列中消息做响应的处理,这个特性可以弥补 RabbitMQ 3.0 以前支持的 imediate 参数的功能。
消息变成死信队列的几种情况
- 消息被拒绝(basic.reject / basic.nack)并且 requeue = false。
- 消息 TTL 过期。
- 队列达到最大长度
死信队列设置
- 首先需要设置死信队列的 exchange 和 queue,然后进行绑定:
* Exchange:dlx.exchange
* Queue:dlx.queue
* RoutingKey:#
- 然后进行正常声明交换机:队列、绑定,只不过需要在队列上加一个参数 arguments.put(“x-dead-letter-exchange”, “dlx.exchange”);
- 这样消息在过期、requeue、队列在达到最大长度时,消息就可以直接路由到死信队列
案例demo
- 生产者:
public class Producer {
public static void main(String[] args) throws Exception {
// 1. 创建一个 ConnectionFactory 工厂
ConnectionFactory factory = new ConnectionFactory();
factory.setHost(RABBITMQ_HOST_IP);
factory.setPort(RABBITMQ_HOST_PORT);
factory.setVirtualHost(RABBITMQ_VIRTUAL_HOST);
// 2. 创建一个 Connection 连接
Connection conn = factory.newConnection();
// 3. 获取一个 Channel 信道
Channel channel = conn.createChannel();
// 4. 发送消息
for (int i=0; i<6; i++) {
AMQP.BasicProperties props = new AMQP.BasicProperties().builder()
.deliveryMode(2)
.contentEncoding("UTF-8")
.expiration("10000")
.build();
String msg = "hello rabbitmq dlx message" + i;
channel.basicPublish(RABBITMQ_TEST_DLX_EXCHANGE, RABBITMQ_DLX_ROUTING_KEY_PRODUCER, props, msg.getBytes());
}
}
}
- 消费者:
public class Consumer {
public static void main(String[] args) throws Exception {
// 1. 创建一个 ConnectionFactory 工厂
ConnectionFactory factory = new ConnectionFactory();
factory.setHost(RABBITMQ_HOST_IP);
factory.setPort(RABBITMQ_HOST_PORT);
factory.setVirtualHost(RABBITMQ_VIRTUAL_HOST);
// 2. 创建一个 Connection 连接
Connection conn = factory.newConnection();
// 3. 获取一个 Channel 信道
Channel channel = conn.createChannel();
// 4. 声明一个交换机
channel.exchangeDeclare(RABBITMQ_TEST_DLX_EXCHANGE, BuiltinExchangeType.TOPIC, true, false, null);
// 5. 声明&绑定队列
Map<String, Object> arguments = new HashMap<>();
arguments.put("x-dead-letter-exchange", RABBITMQ_DLX_EXCHANGE);
channel.queueDeclare(RABBITMQ_TEST_DLX_QUEUE, true, false, false, arguments);
channel.queueBind(RABBITMQ_TEST_DLX_QUEUE, RABBITMQ_TEST_DLX_EXCHANGE, RABBITMQ_DLX_ROUTING_KEY_CONSUMER);
// 6. 进行死信队列的声明
channel.exchangeDeclare(RABBITMQ_DLX_EXCHANGE, BuiltinExchangeType.TOPIC, true, false, null);
channel.queueDeclare(RABBITMQ_DLX_QUEUE, true, false, false, null);
channel.queueBind(RABBITMQ_DLX_QUEUE, RABBITMQ_DLX_EXCHANGE, RABBITMQ_DLX_ROUTING_KEY);
// 7. 消费消息
channel.basicConsume(RABBITMQ_TEST_DLX_QUEUE, false, new MyConsumer(channel));
}
}
- BaseInfo:
public interface BaseInfo {
String RABBITMQ_HOST_IP = "192.168.254.106";
int RABBITMQ_HOST_PORT = 5672;
String RABBITMQ_VIRTUAL_HOST = "/";
String RABBITMQ_TEST_DLX_EXCHANGE = "test-dlx-exchange";
String RABBITMQ_DLX_ROUTING_KEY_PRODUCER = "dlx.key";
String RABBITMQ_DLX_ROUTING_KEY_CONSUMER = "dlx.#";
String RABBITMQ_TEST_DLX_QUEUE = "test-dlx-queue";
String RABBITMQ_DLX_EXCHANGE = "dlx.exchange";
String RABBITMQ_DLX_ROUTING_KEY = "#";
String RABBITMQ_DLX_QUEUE = "dlx.queue";
}
Spring整合RabbitMQ
- 添加依赖:
<!-- Spring整合rabbitmq依赖 -->
<dependency>
<groupId>org.springframework.amqp</groupId>
<artifactId>spring-rabbit</artifactId>
<version>2.1.7.RELEASE</version>
</dependency>
- 配置文件:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:rabbit="http://www.springframework.org/schema/rabbit"
xsi:schemaLocation="http://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/rabbit
https://www.springframework.org/schema/rabbit/spring-rabbit.xsd">
<!-- 管理 HelloMessageListener -->
<bean id="helloMessageListener" class="com.yw.rabbitmq.HelloMessageListener"/>
<!-- 配置连接 -->
<rabbit:connection-factory id="connectionFactory" host="192.168.254.106" port="5672" username="guest" password="guest" virtual-host="/" requested-heartbeat="60"/>
<!-- 配置 RabbitTemplate -->
<rabbit:template id="rabbitTemplate" connection-factory="connectionFactory" exchange="spring-exchange"
routing-key="spring.key"/>
<!-- 配置 RabbitAdmin -->
<rabbit:admin connection-factory="connectionFactory"/>
<!-- 配置队列名称 -->
<rabbit:queue name="spring-queue"/>
<!-- 配置 Topic 类型的交换器 -->
<rabbit:topic-exchange name="spring-exchange">
<rabbit:bindings>
<rabbit:binding pattern="spring.*" queue="spring-queue"/>
</rabbit:bindings>
</rabbit:topic-exchange>
<!-- 配置监听器 -->
<rabbit:listener-container connection-factory="connectionFactory">
<rabbit:listener ref="helloMessageListener" queue-names="spring-queue"/>
</rabbit:listener-container>
</beans>
- 发送消息:
public class MessageProducer {
public static void main(String[] args) {
ClassPathXmlApplicationContext ctx = new ClassPathXmlApplicationContext("beans.xml");
RabbitTemplate template = ctx.getBean(RabbitTemplate.class);
template.convertAndSend("hello spring rabbitmq message");
}
}
- 消费消息:
public class HelloMessageListener implements MessageListener {
@Override
public void onMessage(Message message) {
System.out.println("接收到的消息:" + new String(message.getBody()));
}
}
SET部署
随着业务的多元化发展,拿滴滴,美团等大厂来说,如滴滴打车,外卖,酒店,旅行等持续高速增长,单个大型分布式的集群,通过机器+集群内部拆分,虽然具备了一定的可扩展性。但随着业务量的进一步增长,整个集群规模主键变得巨大,从而会在某个点达到瓶颈,无法满足扩展性需要,并且大集群内核心服务出现了问题,会影响全网用户。
- 以滴滴打车、美团外卖举例:打车业务量巨大,尤其是早晚高峰,全年订单已越10亿。外卖业务量庞大,目前单量突破1700w/天。
单元化
想把一个大的集群拆分开,不要直接做成一个太大的集群,如果集群太大的话,一旦出现问题,整个业务线都会崩溃。
概述
- 了解 SET 架构的演进
- 大企中 SET 化架构是如何推进的
- 理解 SET 化架构的设计和具体的解决方案是怎么实现的?
- 主要避免多个业务线,在某个功能出了问题之后,导致整个业务线产生一个非常巨大的影响。
- 如何避免?调整你的架构设计
巨大的订单量,在高峰期会导致几个问题
容灾问题
- 核心服务(比如订单服务)挂掉,会影响全网所有用户,导致整个业务不可用
- 数据库主库集中在一个IDC,主机房挂掉,会影响全网所有用户,整个业务无法快速切换和恢复
资源扩展问题
- 单IDC的资源(机器、网络带宽等)已经无法满足,扩展ICD时,存在跨机房访问时延问题(增加异地机房时,时延问题更加严重)
- 数据库主库单点,连接数有限,不能支持应用程序的持续扩展
- 可能影响的地方:服务端、前端、核心的链路、数据库
大集群中拆分
- 分布式集群规模开大后,会相应的带来资源扩展、大集群拆分及容灾问题
- 所以对业务扩展及容灾需求考虑,我们需要一套从底层架构彻底解决问题的方案,业界主流解决方案:单元化架构方案(阿里、支付宝、饿了么、微信 等)
同城“双活”
- 比如部署了两套中心、两个机房:相互切换
- 分担了流量:在业务的高峰期就可以去做一个分流
- 数据持久层:任务缓存、持久化、持久层数据分析
两地三中心
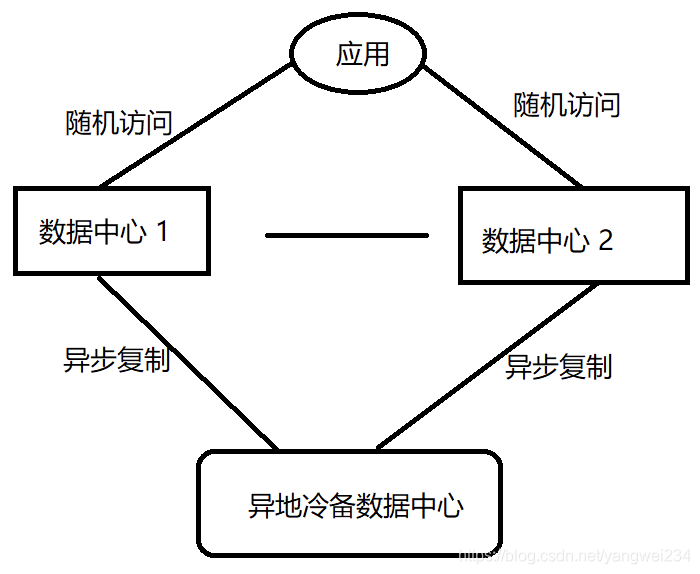
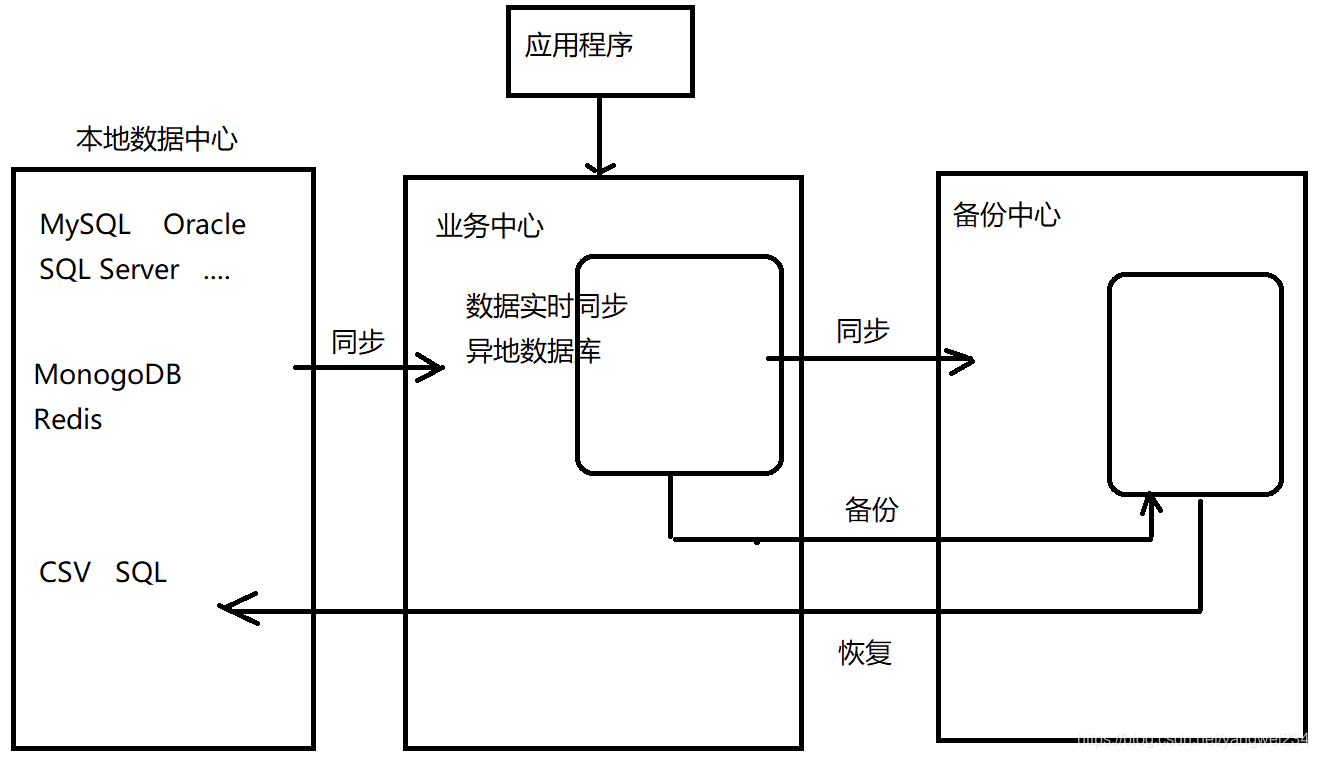
- 冷备中心不工作了,你敢切吗?并没有解决前面提到的三个问题,只是起到了一个缓冲作用,所以比较鸡肋。
SET架构
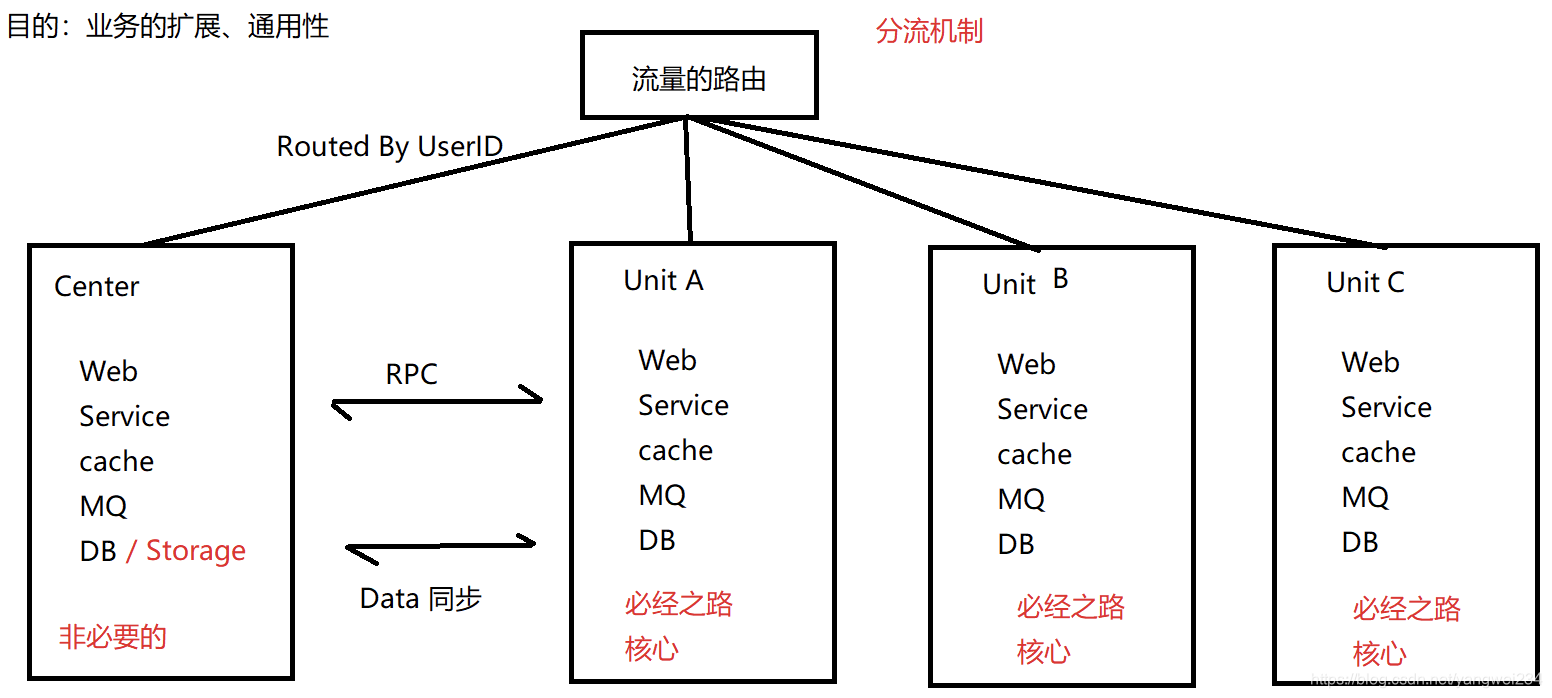
目标:
- 业务:解决业务遇到的扩展性和容灾问题,支撑业务的高速发展
- 通用性:架构侧形成统一通用的解决方案,方便个业务线接入使用

- 解决容灾问题:UnitA一套业务的核心组件,比如网购,从加入购物车到下单,经过A、B、C、D等步骤,全部部署到UnitA的一个机房中,UnitB和UnitC是UnitA的备份,如果UnitA的服务或MQ发生故障,就会路由到UnitB或UnitC中。非核心的业务组件部署到center中。
- 解决扩展问题:UnitA可以是旅游,UnitB可以是外卖,将来还可以扩展
SET 部署策略
流量路由
按照特殊的key(通常为userid)进行路由,判断某次请求该路由到中心集群还是单元化集群
中心集群
为进行单元化改造的服务(通常不在核心交易链路)成为中心集群,跟当前架构保存一致
单元化集群
- 每个单元化集群,只负责本单元内的流量处理,以实现流量拆分以及故障隔离
- 每个单元化集群前期,只存储本单元产生的交易数据,后续会做双向数据同步,实现容灾切换需求
中间件
RPC、KV、MQ 等等
- RPC:对于 SET 服务,调用封闭在 SET 内,对于非 SET 服务,沿用现有路由逻辑
- KV:支持分 SET 的数据生产和查询
- MQ:支持分 SET 的消息生产和消费
数据同步
- 全局数据,比如是数据量小,而且变化不大的数据,比如饭店菜单数据,部署在中心集群,其他单元化集群同步全局数据到本单元化内
- 未来演变为异地多活架构时,各单元化集群数据需要进行双向同步来实现容灾需要
SET 化路由策略及其能力
- 异地容灾
- 通过 SET 化架构的流量调度能力,将 SET 分别部署在不同地区的数据中心,实现跨地区容灾支持
高效本地化服务
- 利用前端位置信息采集和域名解析策略,将流量路由到最近的 SET,提供最高效的本地化服务
- 比如 O2O 场景就具有本地生产,本地消费的特点,所以更加需要 SET 化支持
集装箱式扩展
- SET 的封装性支持更加灵活的部署扩展性,比如 SET 一键创建 / 下线,SET 一键发布等
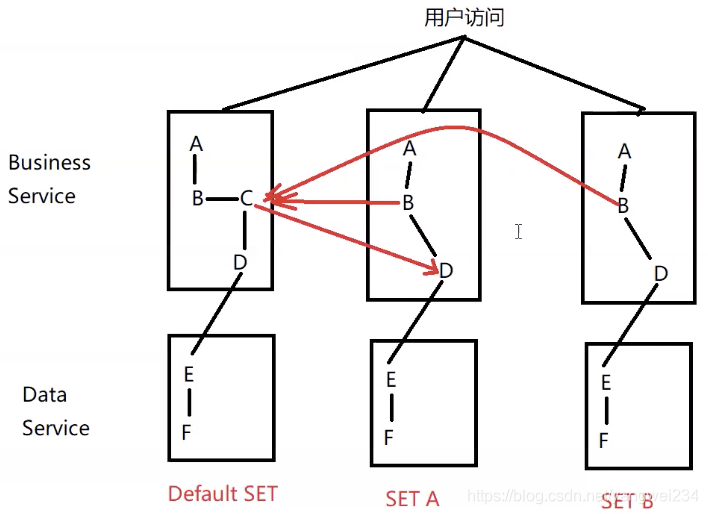
SET 部署原则
对业务透明
- SET 化架构的实现对业务代码一定要透明,业务代码不需要关心 SET 化的规则、SET化部署的问题
SET 切分
- 理论上:切分的时候,要由业务层去根据需求定制
- 实现上:优先选择最大的业务纬度,然后进行划分
- 我们在接入层、逻辑层和数据层,都可以进行独立的 SET 切分,规则要根据自身的业务去考虑,在实现部署和将来的运维成本上,能够达到最大的优化
部署规范
一个SET并不一定只限制在一个机房,也可以跨机房或者跨地区部署;为保证灵活性,单个SET内机器数不宜过多(如不超过100台物理机)
SET化架构实现
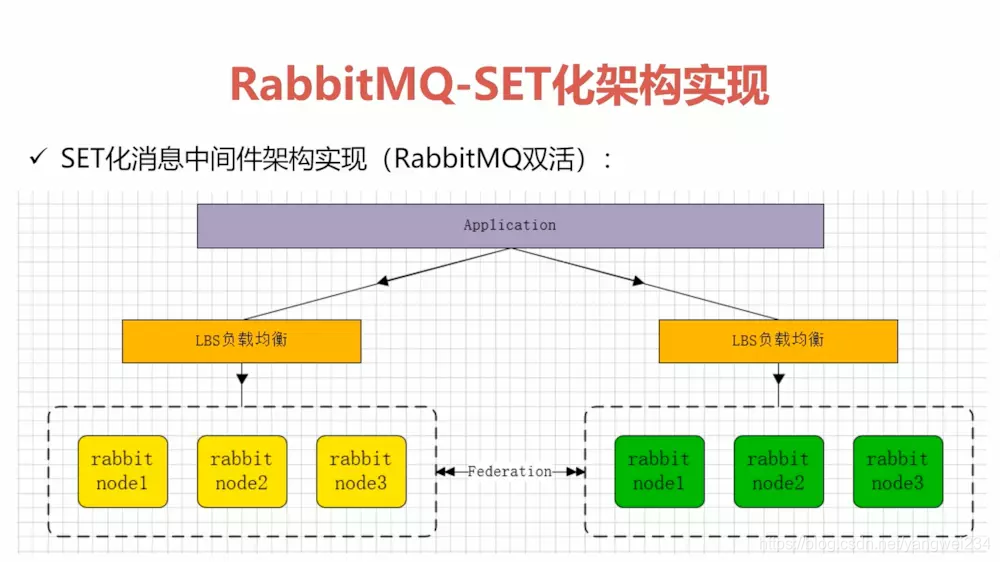
- Federation插件:用于 RabbitMQ 进行消息的异步通信的一个插件。它能够实现节点与节点之间的通信,包括集群之间的数据的同步通信。
- Federation插件安装:
rabbitmq-plugins enable rabbitmq_federation
rabbitmq-plugins enable rabbitmq_federation_management


















 1034
1034

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











