




 本文介绍线性回归算法及梯度下降法在监督学习中的应用,详细解析代价函数概念,梯度下降算法原理及其在线性回归问题中的具体实现。
本文介绍线性回归算法及梯度下降法在监督学习中的应用,详细解析代价函数概念,梯度下降算法原理及其在线性回归问题中的具体实现。
- 模型表示
第一个学习算法是线性回归算法。例如一个预测住房价格,我们要使用一个数据集,根据不同房屋尺寸所售出的价格,画出数据集在图上的表示。比方说,如果你朋友的房子是1250平方尺大小,你要告诉他们这房子能卖多少钱。那么,你可以做的一件事就是构建一个模型,也许是条直线,从下图数据模型上来看能以大约220000(美元)左右的价格卖掉这个房子。这就是监督学习算法的一个例子,对于不同尺寸的房屋,给出了对应的“正确的答案”,即房子实际的价格。在监督学习中这个数据集被称训练集。

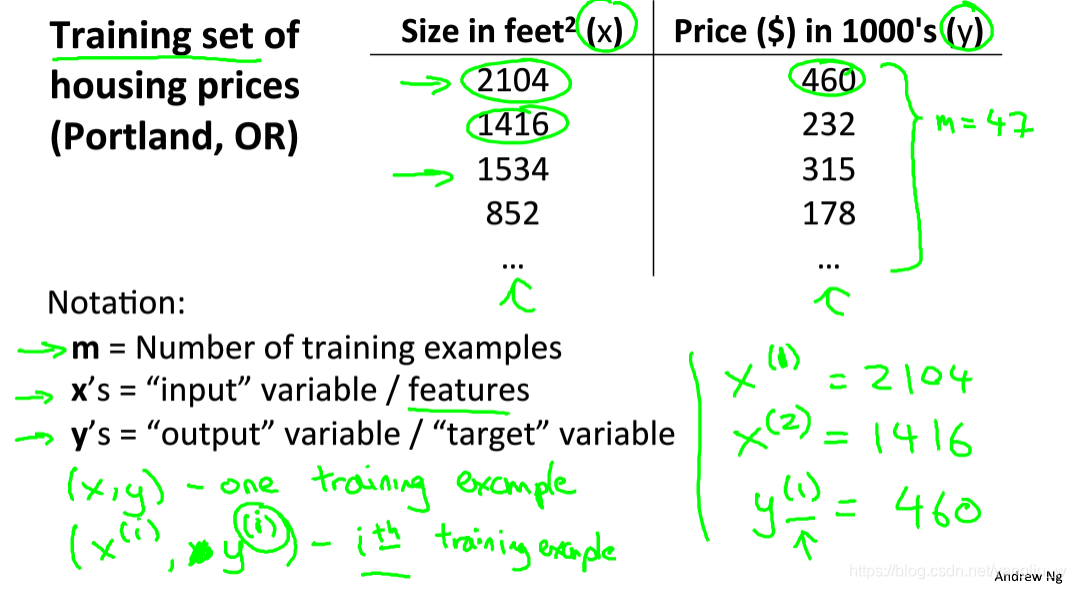
假使我们回归问题的训练集(Training Set)如上表所示,用小写的m来表示训练样本的数目、x代表特征/输入变量、y代表目标变量/输出变量、(x,y)代表训练集中的实例、![]() 代表第i个观察实例、h代表学习算法的解决方案或函数也称为假设(hypothesis)
代表第i个观察实例、h代表学习算法的解决方案或函数也称为假设(hypothesis)
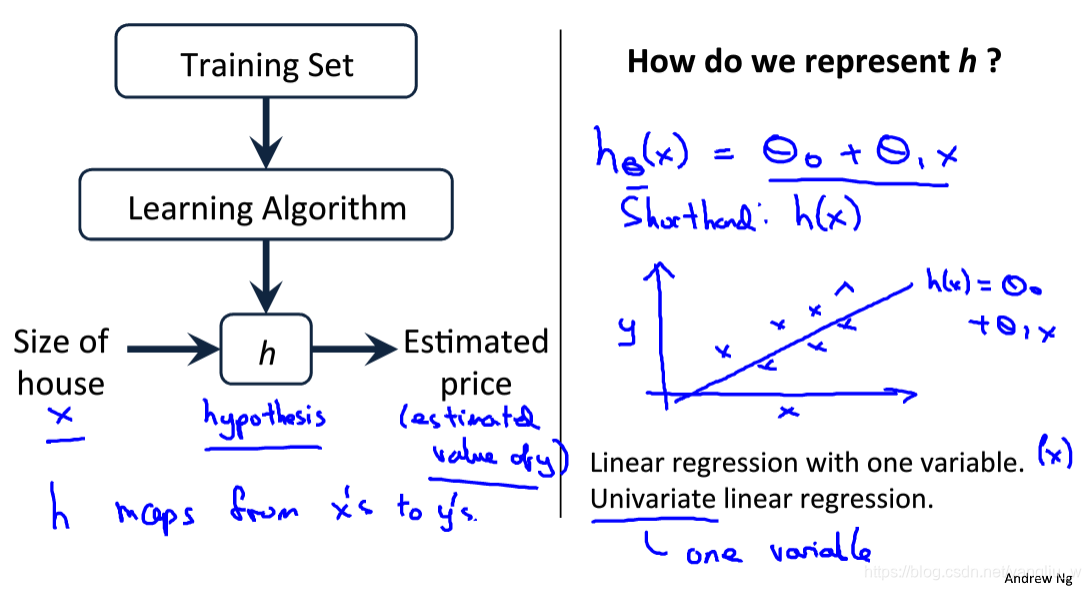
上面是一个监督学习算法的工作方式,输入训练集,通过学习算法得到一个函数,通常表示为小写h表示,表示一个函数。根据输入的x值来得出y值,h是一个从x到y的函数映射。对于我们该如何表达 h?一种可能的表达方式为:![]() ,因为只含有一个特征/输入变量,因此这样的问题叫作单变量线性回归问题。
,因为只含有一个特征/输入变量,因此这样的问题叫作单变量线性回归问题。
- 代价函数
定义代价函数的概念,是为了把最有可能的直线与我们的数据相拟合。要选择最合适的参数,让我们的假设函数得到的值最接近真实值。


对于上图假设函数,也就是用来进行预测的函数,给出了线性函数形式:![]() 。对于模型中参数
。对于模型中参数![]() 的选择的参数决定了我们得到的直线相对于我们的训练集的准确程度。如下图是一些参数模型的选择。
的选择的参数决定了我们得到的直线相对于我们的训练集的准确程度。如下图是一些参数模型的选择。
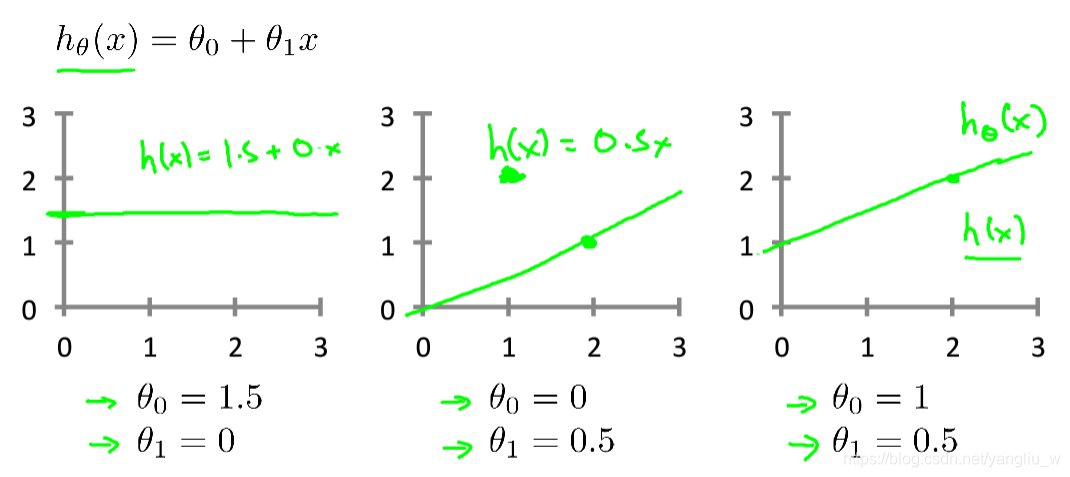
模型所预测的值![]() 与训练集中实际值y之间的差距(下图中蓝线所指)就是建模误差(modeling error)。我们定义代价函数为:
与训练集中实际值y之间的差距(下图中蓝线所指)就是建模误差(modeling error)。我们定义代价函数为:![]() ,我们的目标便是选择出可以使得建模误差的平方和能够最小的模型参数,即使得代价函数
,我们的目标便是选择出可以使得建模误差的平方和能够最小的模型参数,即使得代价函数![]() 最小。
最小。
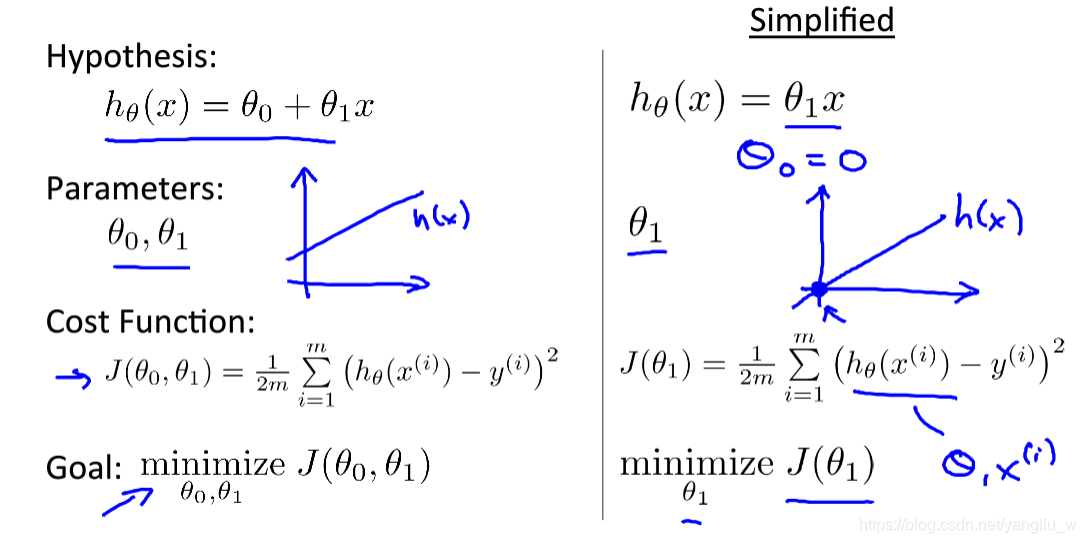

- 代价函数的直观理解1
上面我们给了代价函数一个数学上的定义。让我们通过一些例子来获取一些直观的感受,看看代价函数到底是在干什么。我们可以试着画一下简化后的![]() 的代价函数
的代价函数![]() ,如下图所示。已知红叉叉是所给数据集,当右边代价函数取得最小时即参数等于1时,这个时候假设函数对于数据的拟合是最好的。
,如下图所示。已知红叉叉是所给数据集,当右边代价函数取得最小时即参数等于1时,这个时候假设函数对于数据的拟合是最好的。

- 代价函数的直观理解2
对于代价函数![]() ,我们可以绘制出来图形,如下图所示。
,我们可以绘制出来图形,如下图所示。

可以看出在三维空间中存在一个使得代价函数最小的点。我们真正需要的是一种有效的算法,能够自动地找出这些使代价函数取最小值的参数来。下面是等高线图代价函数的样子,可以看出随着代价函数不断地接近最小值时,假设函数拟合的效果也越来越好。
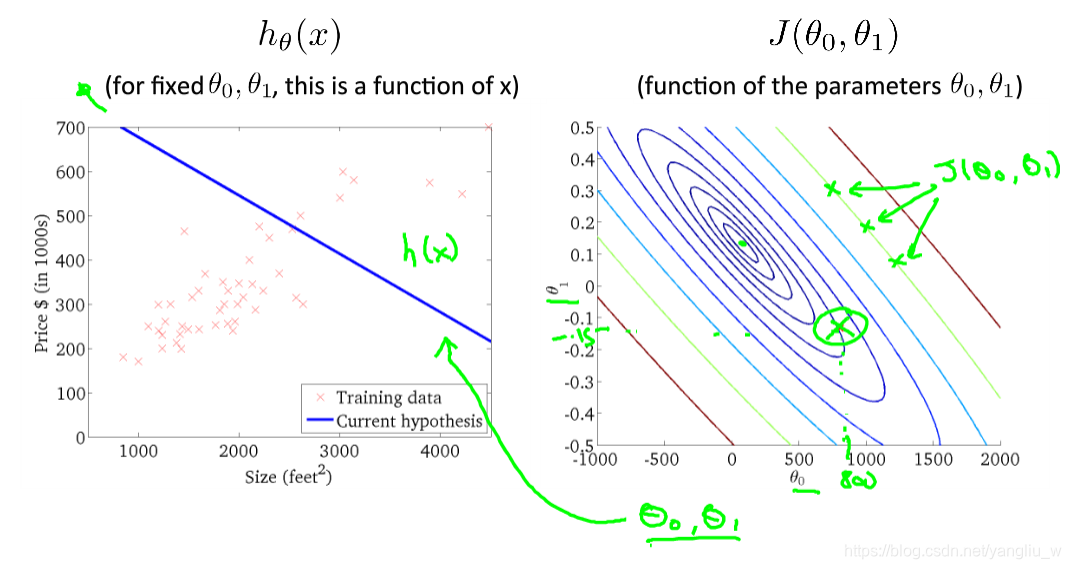


- 梯度下降
梯度下降是一个用来自动求函数最小值的算法,我们将使用梯度下降算法来求出代价函数的最小值。梯度下降背后的思想是:开始时我们随机选择一个参数的组合![]() ,计算代价函数,然后我们寻找下一个能让代价函数值下降最多的参数组合。直到一个局部最小值(local minimum),因为并没有尝试完所有的参数组合,所以不能确定我们得到的局部最小值是否便是全局最小值(global minimum),选择不同的初始参数组合,可能会找到不同的局部最小值。
,计算代价函数,然后我们寻找下一个能让代价函数值下降最多的参数组合。直到一个局部最小值(local minimum),因为并没有尝试完所有的参数组合,所以不能确定我们得到的局部最小值是否便是全局最小值(global minimum),选择不同的初始参数组合,可能会找到不同的局部最小值。
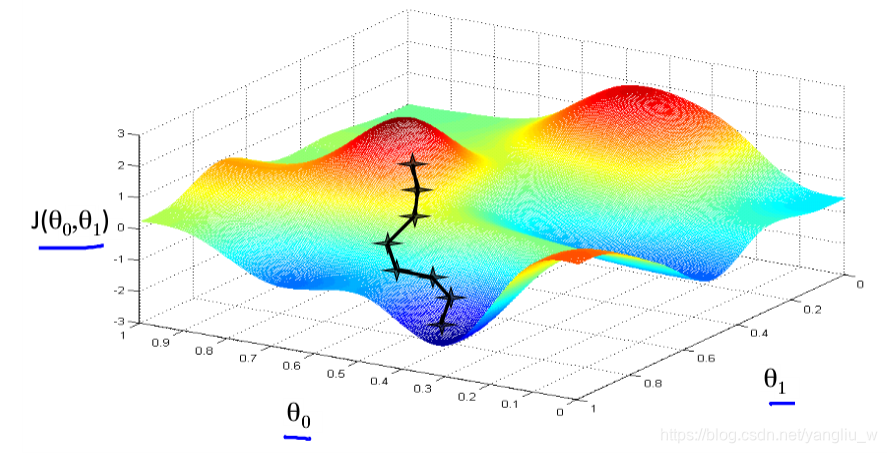

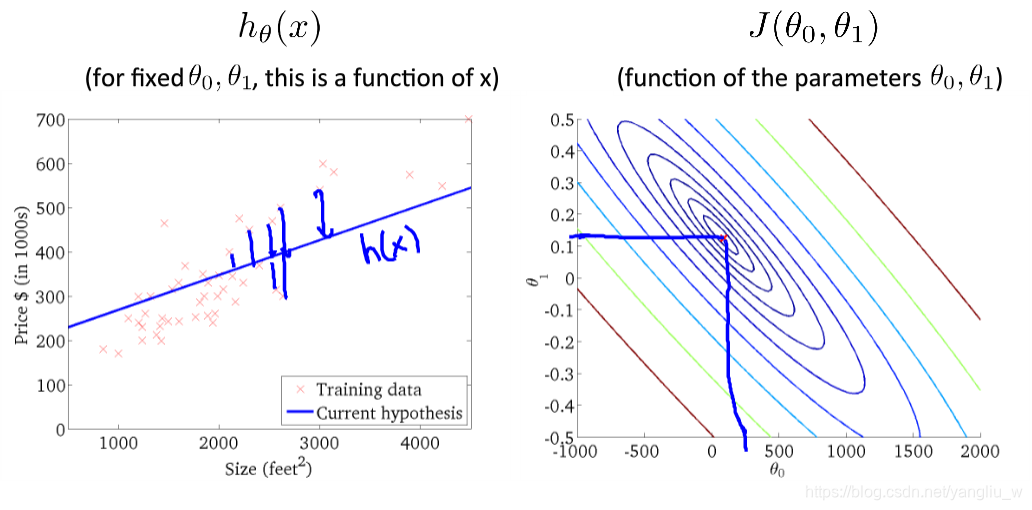
如上图所示,在梯度下降算法中,在自己所处的地方,旋转360度,发现最佳的下山方向,走一步,再从这个新的点,环顾四周,并决定从什么方向将会最快下山,然后又迈进了一小步,并依此类推,直到你接近局部最低点的位置。不同的走法可能会到达不同的局部最小点。
批量梯度下降(batch gradient descent)算法的公式和参数更新过程如下:

其中α是学习率(learning rate),它决定了代价函数下降程度最大的方向向下迈出的步子有多大,在批量梯度下降中,我们每一次都同时让所有的参数减去学习速率乘以代价函数的导数。在梯度下降时,对于参数的更新,应该计算公式右边的部分,通过那一部分计算出参数的值,然后同时更新![]() 。同步更新是更自然的实现方法。当人们谈到梯度下降时,他们的意思就是同步更新。对于微分项
。同步更新是更自然的实现方法。当人们谈到梯度下降时,他们的意思就是同步更新。对于微分项![]() ,就是数学定义中假设函数的偏导数。
,就是数学定义中假设函数的偏导数。
- 梯度下降的直观理解
梯度下降算法如下 :

下面深入研究这个算法是做什么的,以及梯度下降算法的更新过程直观上有什么意义。如下图所示,某点求导的目的,就代表该点的切线的斜率,第一个图这条线有一个正斜率,也就是说它有正导数,因此,新的参数更新后会减去一个正数乘学习率α,往坐标轴左移,接近最小值点。 反之,第二个图,负斜率,参数更新的方向坐标轴右移,也在接近最小值点。
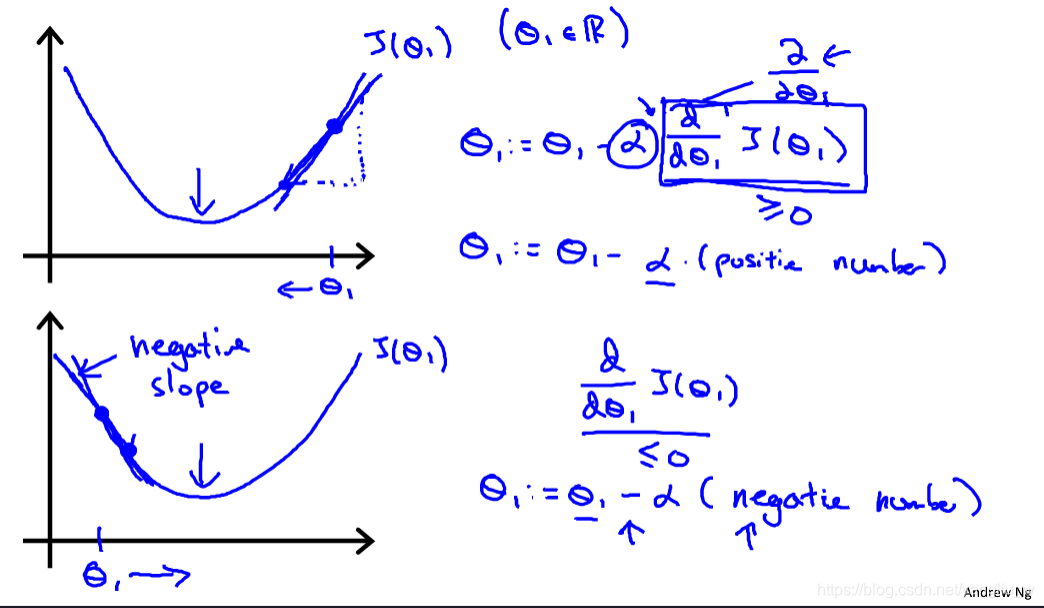
其次,让我们讨论一下α值太小或太大会出现什么情况。如下图所示,如果学习速率α太小,结果就是只能一点点地挪动,去努力接近最低点,梯度下降速度会很慢,需要很多步才能到达全局最低点。如果太大,那么梯度下降法可能会越过最低点,甚至可能无法收敛,第一次越过了最低点,第二次移动会变大,一次次越过最低点,实际上离最低点越来越远,所以,如果太大,它会导致无法收敛,甚至发散。
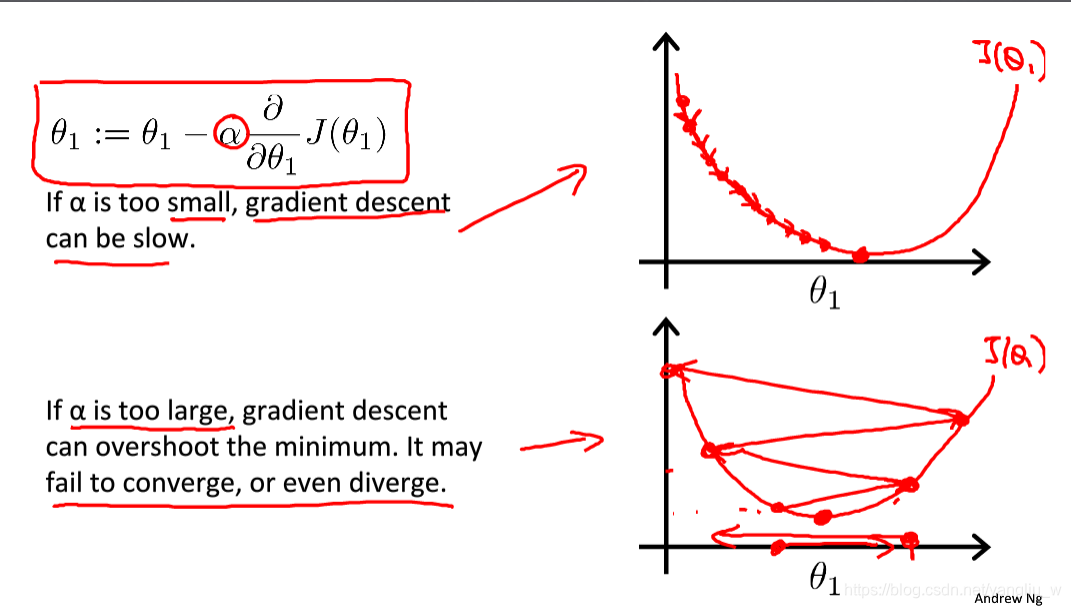
注意一下,假设你将初始化在局部最低点,这个时候局部最优点的导数将等于零,不再改变,梯度下降法更新没发生变化,不会改变参数的值。故即使学习速率保持不变时,梯度下降也可以收敛到局部最低点。

再次直观的感受梯度下降步骤,要找到最小值,首先初始化我的梯度下降算法,如图初始化为第一个点,我更新一步梯度下降,到达第二个点,由于第一个点的导数是相当陡的,所以更新距离较大再更新一步,你会发现我的导数,也即斜率,是没那么陡的。随着越接近最低点,导数越来越接近零,所以,梯度下降一步后,新的导数会变小一点点,更新的幅度就会更小。所以随着梯度下降法的运行,你移动的幅度会自动变得越来越小,直到最终移动幅度非常小于非常小的数,认为收敛到局部极小值。这就是梯度下降算法,你可以用它来最小化任何代价函数,不只是线性回归中的代价函数。接下来,对于线性回归中的代价函数,结合梯度下降法,我们将会会得出第一个机器学习算法,即线性回归算法。
- 梯度下降的线性回归
梯度下降算法和线性回归算法如图:

线性回归问题运用梯度下降法,关键在于求出代价函数的导数:
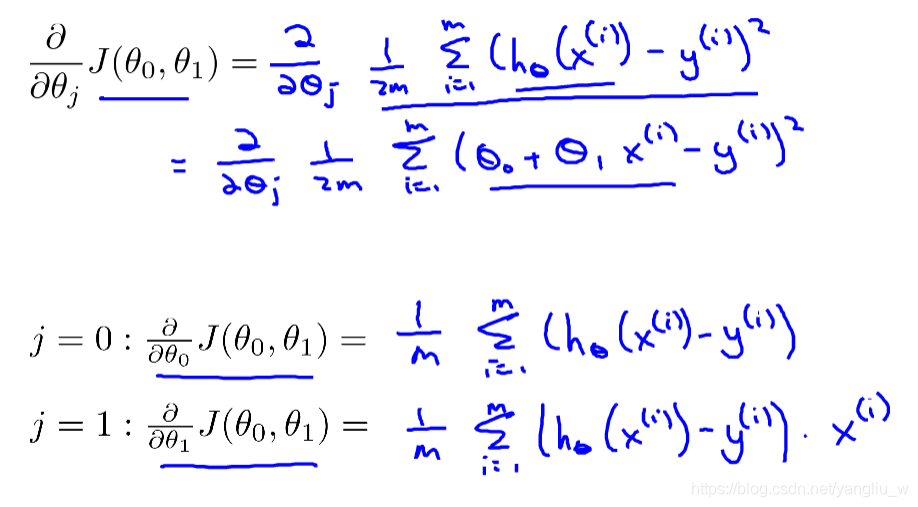
则批量梯度下降算法为:

批量梯度下降算法指的是在梯度下降的每一步中,我们都用到了所有的训练样本。在计算微分求导项时,由于有求和运算,所以,在每一个单独的梯度下降中,我们最终都要计算这样一个东西,这个项需要对所有个训练样本求和。事实上,也有其他类型的梯度下降法,不考虑整个的训练集,而是只关注训练集中的一些小的子集。
如果你之前学过线性代数,会知道有一种计算代价函数最小值的数值解法,不需要梯度下降这种迭代算法。它可以在不需要多步梯度下降的情况下,也能解出代价函数的最小值,这是另一种称为正规方程(normal equations)的方法。实际上在数据量较大的情况下,梯度下降法比正规方程要更适用一些。

















 149
149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









