






 本文介绍了基于YOLO-V3的缺陷检测方法,探讨了YOLO-V3算法的改进点,包括多尺度特征利用和darknet-53网络。在Darknet框架下,详细阐述了数据准备、训练过程以及Windows环境下Darknet的使用,并提供了训练所需资源链接。后续将讨论工程化应用。
本文介绍了基于YOLO-V3的缺陷检测方法,探讨了YOLO-V3算法的改进点,包括多尺度特征利用和darknet-53网络。在Darknet框架下,详细阐述了数据准备、训练过程以及Windows环境下Darknet的使用,并提供了训练所需资源链接。后续将讨论工程化应用。
1.前言
YOLO-V3是在速度和准确率之间tradeoff。在缺陷检测中,YOLO-V3算法也是非常常见且取得非常好效果的一种。
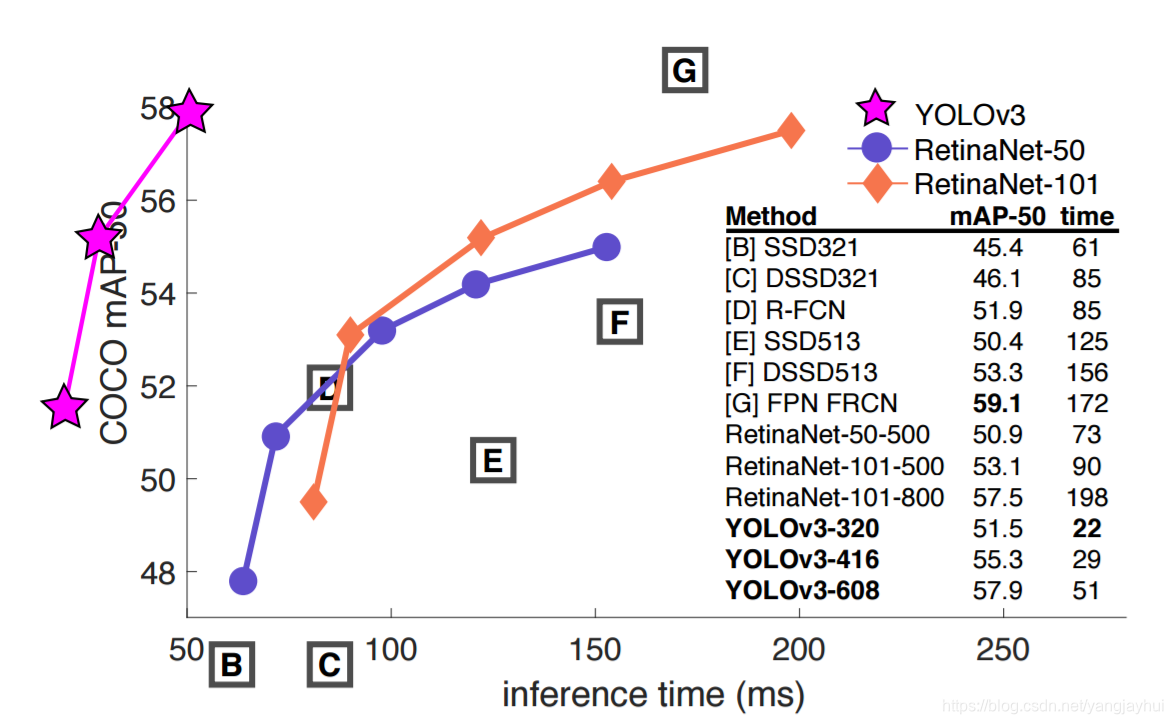
2.YOLO-V3算法
YOLO-V3(论文:https://arxiv.org/abs/1804.02767)是在YOLO-V1和YOLO-V2的基础上改进的,主要改进是1)利用多尺度特征进行对象检测;
2)更好的基础分类网络(如ResNet)和分类器 darknet-53;
3)延续9种尺度的先验框:采用K-means聚类的方法得到先验框的尺寸,为每种下采样尺度设定3种先验框,最终聚类出9种尺寸的先验框;
在Darknet(https://pjreddie.com/darknet)框架下展开YOLO-V3算法的开发,
Windows 版本 Darknet: GitHub - AlexeyAB/darknet: YOLOv4 / Scaled-YOLOv4 / YOLO - Neural Networks for Object Detection (Windows and Linux version of Darknet ),由C和CUDA实现,对第三方库的依赖较少,易移植到其它平台,如Windows或嵌入式设备。
3.Darknet下训练数据(Pascal VOC Data)
1)首先制作VOC数据集
2)生成适合与YOLO-V3的数据集
python ./scripts/voc_label.py
3)生成适合于自己数据集的anchor大小
darknet.exe detector calc_anchors data/obj.data -num_of_clusters 9 -width 416 -height 4164)共有一种缺陷,修改yolov3-voc.cfg,filters=3*(classes+5)
[convolutional]
filters=18
[yolo]
classes=1
修改合适于自己显卡性能的width、height、batch、subdivisions
#Testing
#batch=1
#subdivisions=1
Training
batch=64
subdivisions=16 #16
width=416 #608,416
height=4165)开始训练
darknet.exe detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74darknet53.conv.74下载链接:https://pjreddie.com/media/files/darknet53.conv.74
多GPU训练:
darknet.exe detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74 -gpu 0,1,2,3显示map训练方法:
darknet.exe detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74 -map4.测试
批量测试图片可参考博客:Windows环境下yolov3+darknet批量处理图片_middle_rookie的博客-优快云博客
5.下一步工程化
PS:见下一篇博客,有问题欢迎交流互相学习(写的比较简单)。

















 8865
8865




 到【灌水乐园】发言
到【灌水乐园】发言







