







 超级会员免费看
超级会员免费看
一、创建一个Pod的工作流程
1. k8s架构解析
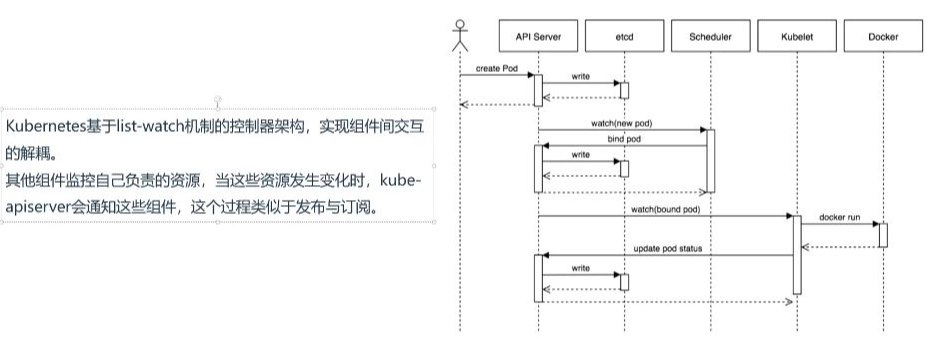
- 组件交互模式: Kubernetes采用list-watch机制的控制器架构,实现组件间交互的解耦。各组件通过监控自己负责的资源,当资源发生变化时由kube-apiserver通知相关组件。
- 类比说明: 类似小卖铺场景,API Server相当于老板,其他组件(控制器、调度器、kubelet)相当于学生。当有新Pod需要处理时,API Server会主动通知对应组件,避免组件不断轮询检查的低效行为。
- 架构特点:
- 各组件之间不直接通信,全部通过API Server进行协调
- 采用发布-订阅模式实现事件通知
- 相比轮询机制更高效,是现代事件通知系统的常见实现方式
二、Pod中影响调度的主要属性
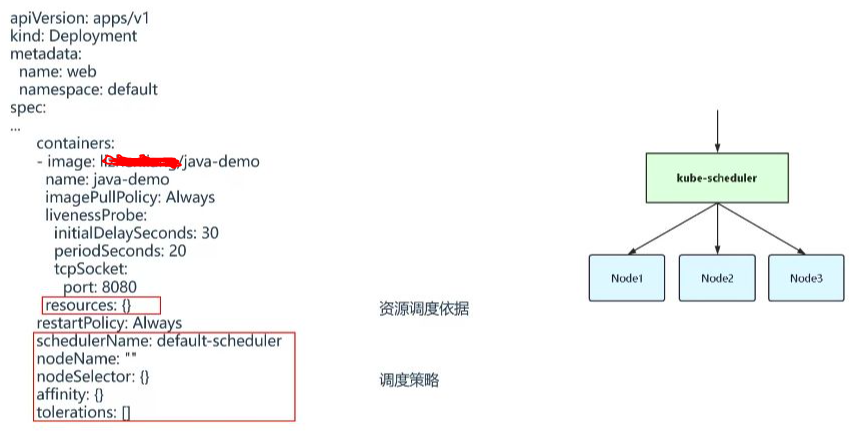
1. 资源配额与调度依据
- 资源配置: 通过resources字段设置容器的CPU和内

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 1243
1243

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









