




首先回顾ResNetv1, 这里把第一版本的ResNet叫做原始版本,原始版本中的网络结构由大量残差单元(“Residual Units”)组成,原文中的残差单元有两种(见图1),一种是building block,一种是“bottleneck” building block,本文中以building block为例。
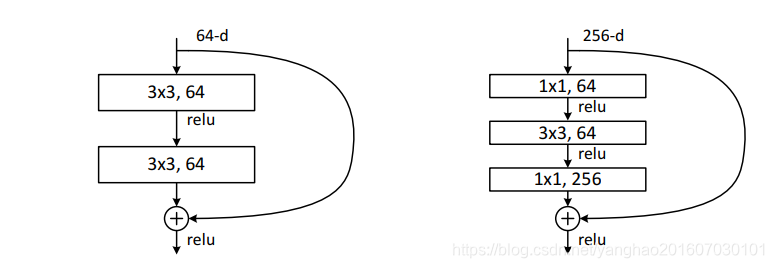
图1.原版本ResNet中提到的两种残差单元。左边是building block,右边是“bottleneck” building block。二者计算量接近,但是右边能取得更好性能。
这些残差单元,可由以下公式表示:
yl=h(xl)+F(xl,Wl),(1)y_l = h(x_l) + F(x_l, W_l) , (1)yl=h(xl)+F(xl,Wl),(1)xl+1=f(yl),(2)x_{l+1} = f(y_l),(2)xl+1=f(yl),(2)
xl和xl+1分别为第l个单元的输入和输出, FFF代表残差函数,h(xl)=xlh(x_l)=x_lh(xl)=xl代表恒等映射(identity mapping ),fff代表ReLU。
该篇论文主要聚焦于构建一条贯通全网络的直通车道,使得前向传播和反向传播都能在这条通道上很好的传播信息,减少因网络层增加而带来的信息损失,也即梯度信息损失等,使得网络能够够造更深层的网络。
作者推导得出,如果h(xl)h(x_l)h(xl)和 f(yl)f(y_l)f(yl)都是恒等映射,那么前向传播和反向传播的信号就能直接从一个单元传到任意一个其他单元。并且实验证明,但网络接近以上两个条件时网络更容易训练。
下面是推理:
当h(xl)h(x_l)h(xl)和 f(yl)f(y_l)f(yl)都是恒等映射时,即h(xl)=xlh(x_l)=x_lh(xl)=x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2002
2002

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









