




 本文介绍了数据预处理的基本步骤,包括处理缺失值、编码分类数据、划分训练集与测试集及特征缩放等。提供了Python和R语言的具体实现示例。
本文介绍了数据预处理的基本步骤,包括处理缺失值、编码分类数据、划分训练集与测试集及特征缩放等。提供了Python和R语言的具体实现示例。
Data Preprocessing
It’s a studying note to self.
Data preprocessing: we need to do some data preprocessing to make the raw dataset to be the dataset that can be used in the next steps.
I just list a few steps of preprocessing.
- Taking care of missing data
- Encoding categorical data
- Encoding the independent variable
- Encoding the dependent variable
- Splitting the dataset into the Training set and Test set
- Feature scaling
Here, I use Spyder and Rstudio.
Python
# Data Preprocessing
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Importing the dataset
# iloc: index; loc: the name of row or column
# X is the values that choose all columns except the last column.
# y is the values of the last column in dataset (labelled value)
dataset = pd.read_csv('Data.csv')
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:, 3].values
Show the results:
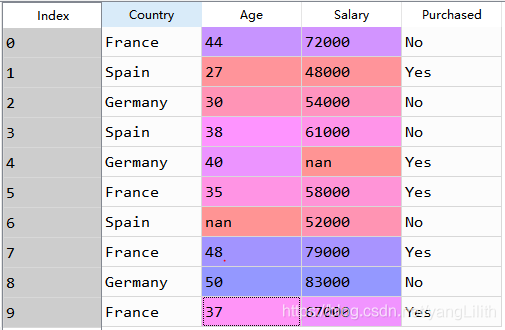

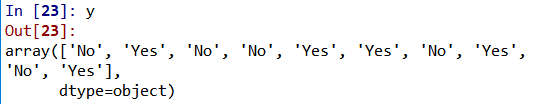
# Taking care of missing data
# Imputer is a class,
from sklearn.preprocessing import Imputer
imputer = Imputer(missing_values = 'NaN', strategy = 'mean', axis = 0)
imputer = imputer.fit(X[:, 1:3])
X[:, 1:3] = imputer.transform(X[:, 1:3])
Show the results:
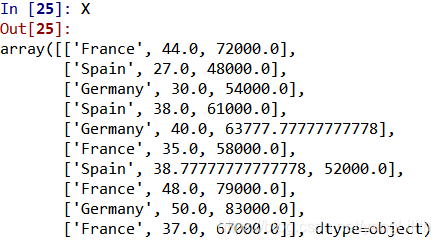
# Coz the first col and the last col are String
# We need to transform them into int
# Encoding categorical data
# Encoding the Independent Variable
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
labelencoder_X = LabelEncoder()
X[:, 0] = labelencoder_X.fit_transform(X[:, 0])
onehotencoder = OneHotEncoder(categorical_features = [0])
X = onehotencoder.fit_transform(X).toarray()
# Encoding the Dependent Variable
labelencoder_y = LabelEncoder()
y = labelencoder_y.fit_transform(y)
There is one tip. We can use dumy varibales here. That means we have three characters named “Frech”, “Spain” and “German”. We can use 100 to be “Frech”.
Using three cols to represent one city.
Show the results of the code:
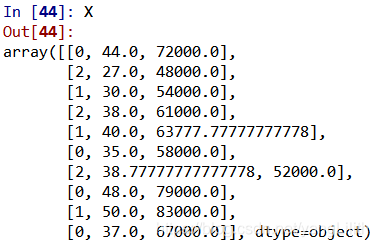
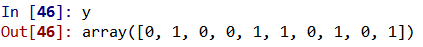
# We only hava one dataset, so wo need to split it into two parts
# If you use the different library,
# you need to change sklearn.model_selection to sklearn.cross_validation
# Splitting the dataset into the Training set and Test set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
# Feature Scaling
# if there are two values: 100000 and 43, 43 will be discarded.
# let the variables to be same scale
# Also, the program can run faster after implementing this
# same basis: first run X_train then X_test
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test)
# Classification: DO NOT applt feature scaling
# Regression: NEED
sc_y = StandardScaler()
y_train = sc_y.fit_transform(y_train)
There is one question: do we need to feature scaling the domain variables. You can find a lot of answers using Google. Different situations you can choose different strategies.
And for y, in classification problem we DO NOT apply it. In regression problem, we need to apply.
R:
# Data Preprocessing
# Importing the dataset
dataset = read.csv('Data.csv')
# Taking care of missing data
dataset$Age = ifelse(is.na(dataset$Age),
ave(dataset$Age, FUN = function(x) mean(x, na.rm = TRUE)),
dataset$Age)
dataset$Salary = ifelse(is.na(dataset$Salary),
ave(dataset$Salary, FUN = function(x) mean(x, na.rm = TRUE)),
dataset$Salary)
# Encoding categorical data
dataset$Country = factor(dataset$Country,
levels = c('France', 'Spain', 'Germany'),
labels = c(1, 2, 3))
dataset$Purchased = factor(dataset$Purchased,
levels = c('No', 'Yes'),
labels = c(0, 1))
# Splitting the dataset into the Training set and Test set
# install.packages('caTools')
library(caTools)
set.seed(123)
split = sample.split(dataset$DependentVariable, SplitRatio = 0.8)
training_set = subset(dataset, split == TRUE)
test_set = subset(dataset, split == FALSE)
# Feature Scaling
training_set = scale(training_set)
test_set = scale(test_set)
PS: I don’t know how to insert R code with correct way using Markdown. If someone knows, please command below. I really appreciate it.
If you have any questions, please comment below and I will get back to you as soon as possible. And you also can find the answer in Udemy class “Machine Learning A-Z™: Hands-On Python & R In Data Science”.
All the codes come from the class of udemy called “Machine Learning A-Z™: Hands-On Python & R In Data Science”.

















 1069
1069

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









