



 GitHub上出现了一个包含20多万张图片的数据集,分为hentai、sexy、neutral、drawings、porn五类,可用于图像分类器训练,准确度可达91%。
GitHub上出现了一个包含20多万张图片的数据集,分为hentai、sexy、neutral、drawings、porn五类,可用于图像分类器训练,准确度可达91%。
三井 发自 凹非寺
量子位 出品 | 公众号 QbitAI
近日,GitHub上悄然出现一个内含20多万张“不可描述”图片的数据集。
这份数据集一共将内容分为5类,分别是:
hentai、sexy、neutral、drawings、porn。

这份资源的贡献者是一位名叫Alexander Kim的数据科学家。
他说,这些数据集可以用来训练图像分类器,使用CNN做出来的分类器,分辨上述的5种图像准确度可以达到91%。

当然,这份数据集的价值并不仅限于此。不论是做敏感内容过滤工具(比如鉴黄工具),还是各种图像生成模型,相关的数据集都是必不可少的。
如果你有什么想法,可以用这个数据集来练手了。
这个数据集资源,现在已经在GitHub Trending上排名第3。
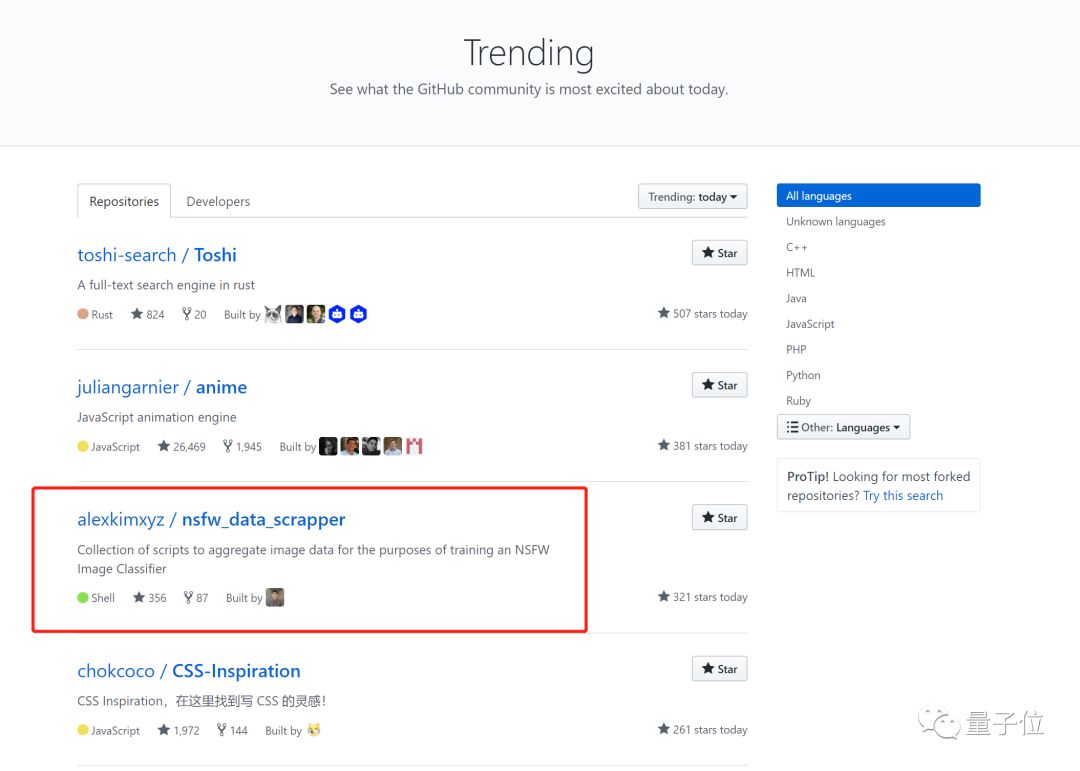
数据集里都有什么?
数据集中,一共有227995张图片。
其中,hentai类别中有45228张;sexy类别19554张;neutral有20960张、drawings有25732张;porn类别最多,有116521张。
这些图片,是以链接的方式呈现的。以sexy类别为例:

这些链接并不都是完全有效的,也有一些会出现404的情况。
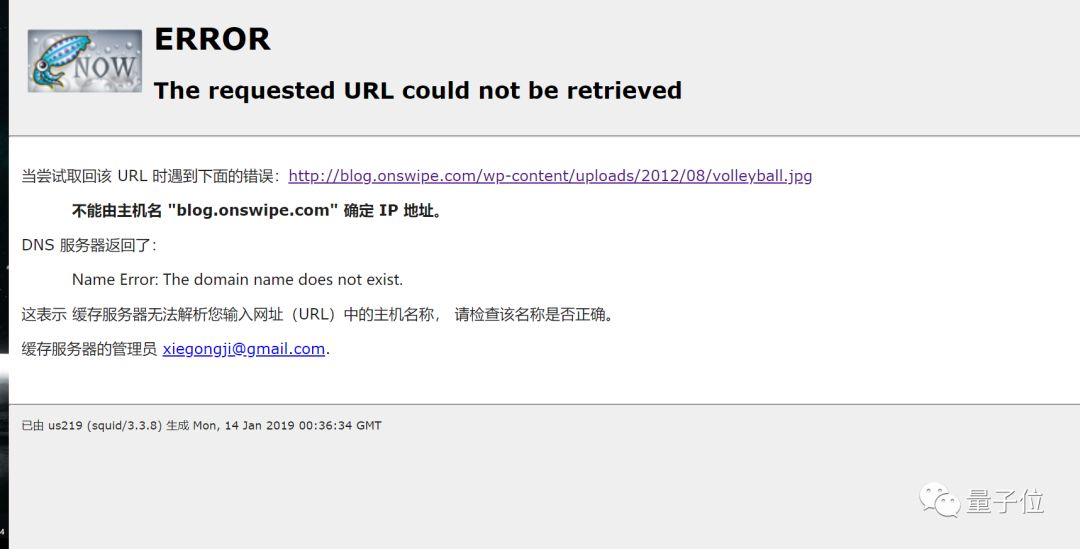
不要问我是怎么知道的……
怎么使用这个数据集?
数据集的使用,主要依靠一些脚本(位于scripts目录下)。分别是:
1_get_urls.sh:遍历文本文件,在scripts / source_urls中下载上述5个类别中的每个类别的图像URL。不过,这个脚本已经运行过了,输出结果在raw_data文件中。如果没有特殊需求,可以直接从下面的脚本开始运行。
2_download_from_urls.sh:下载raw_data目录中文本文件中找到的URL的实际图像。
3_optional_download_drawings.sh:(可选)脚本,从Danbooru2018数据集下载适合工作场所的动漫图像。
4_optional_download_neutral.sh:(可选)脚本,从Caltech256数据集下载适合工作场所的中性图像。
5_create_train.sh:创建data/train目录,将所有raw_data中的.jpg和.jpeg文件复制进去,并删除损坏的图像。
6_create_test.sh:创建data/test目录,从data/train中随机为每一类移动N=2000个文件。(如果需要不同的训练/测试分割,可以在脚本里改变这个数字)。也可以多次运行这个脚本,每次从data/train中移动每个类别的N个图片到data/test中。
具体的运行方式如下:
$ bash 1_get_urls.sh # has already been run
$ find ../raw_data -name "urls_*.txt" -exec sh -c "echo Number of URLs in {}: ; cat {} | wc -l" \;
Number of URLs in ../raw_data/drawings/urls_drawings.txt:
25732
Number of URLs in ../raw_data/hentai/urls_hentai.txt:
45228
Number of URLs in ../raw_data/neutral/urls_neutral.txt:
20960
Number of URLs in ../raw_data/sexy/urls_sexy.txt:
19554
Number of URLs in ../raw_data/porn/urls_porn.txt:
116521
$ bash 2_download_from_urls.sh
$ bash 3_optional_download_drawings.sh # optional
$ bash 4_optional_download_neutral.sh # optional
$ bash 5_create_train.sh
$ bash 6_create_test.sh
$ cd ../data
$ ls train
drawings hentai neutral porn sexy
$ ls test
drawings hentai neutral porn sexy
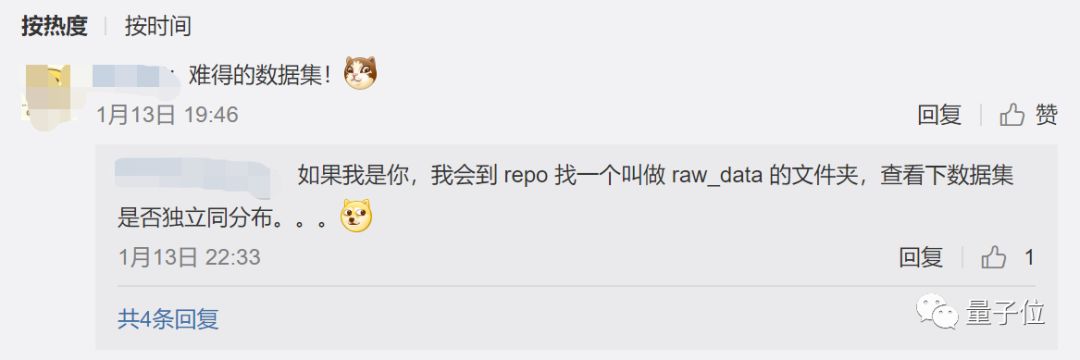
不过,也有热心的微博网友给出了一个使用方法:
运行环境
目前,这些脚本只在Ubuntu 16.04 Linux发行版中进行了测试。
需要的环境配置是:
Python3 环境:conda env create -f environment.yml
Java 运行环境:
(Ubuntu linux):sudo apt-get install default-jreLinux 命令行工具:wget、convert、rsync、shuf
传送门
在给出传送门之前,还是很有必要先发出预警:
上班时,不宜观看数据集内容。
https://github.com/alexkimxyz/nsfw_data_scrapper
— 完 —
加入社群
量子位AI社群开始招募啦,欢迎对AI感兴趣的同学,在量子位公众号(QbitAI)对话界面回复关键字“交流群”,获取入群方式;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进专业群请在量子位公众号(QbitAI)对话界面回复关键字“专业群”,获取入群方式。(专业群审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「好看」吧 !

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









