



基于加密大数据云的高效隐私保护多因素排名与近似搜索
摘要
在将数据外包之前加密数据已成为使用传统搜索算法的一个挑战。许多技术被提出以满足这一需求。然而,由于云服务采用按需付费模式,这些技术效率低下。本文通过提出一种针对加密云数据的近似多关键词搜索与多因素排序方法来解决这一难题。此外,我们建立了严格的隐私要求,并证明所提出的方案在隐私性方面是安全的。据我们所知,我们是首次在语义搜索中提出近似匹配技术的研究者。进一步地,为了提高搜索效率,我们采用了多因素排序技术对文档查询进行排名。通过结合真实世界数据的全面实验分析,我们所提出的方案表现出更高的效率,能够检索出更准确的结果,同时通过在查询数据中引入随机性来提升隐私保护水平。
引言
为了提供按需资源访问,许多公司正在将服务迁移到云。然而,由于用户可以在远程位置使用这些数据,导致大量数据分散在各个地方[1]。研究人员已提出一些将数据加密并外包到云中的技术[2]。鉴于高昂的带宽成本,下载并在本地解密所有数据是不可行的,而我们可以通过先在加密数据上搜索,再下载确切信息来解决。然而,通过这种方法满足准确性、隐私和效率等性能要求可能极具挑战性。
特别地,我们总结了本文的贡献如下:
- 使用词干提取算法进行近似匹配,以降低搜索时间复杂度;
- 考虑多因素计算近似评分,以更准确地生成排序结果;
- 通过消除不重要词汇实现高效索引构建,达到优化存储的目的;
- 在索引和查询中引入动态虚拟字段,以增强隐私保护;
- 在搜索时间、准确性和隐私保护方面,与最先进的技术进行实验结果比较[3]在搜索时间、准确性以及隐私保护方面的实验结果。
2 问题定义
2.1 系统模型
系统模型1中进行了说明。在本文中,我们使用向量空间模型对存储在云服务器中的文档进行建模,其中当提及数据和文档向量时,每个数据都被表示为数据向量。我们解释了高维空间中多关键词搜索的概念,即维度矩阵中的特定数据可以称为数据向量。在多关键词搜索算法的背景下,我们将数据建模为维度矩阵,以对特定查询执行排名并检索排名得分。请注意,我们不以矩阵形式存储索引,而是使用二叉树索引[3]技术来创建索引。
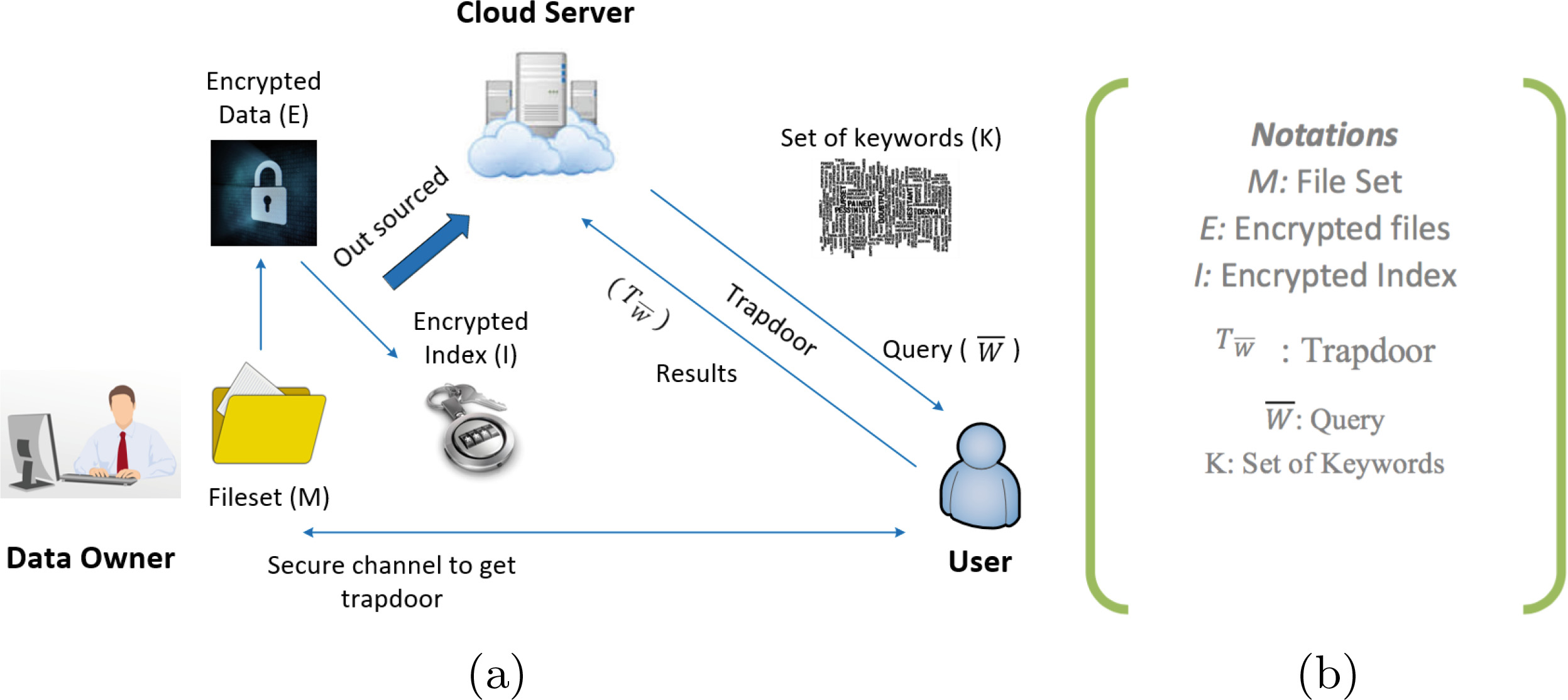
2.2 符号说明
本节我们总结论文中使用的符号说明。我们在整篇论文中采用相同的符号说明:
- M :表示为n个数据文档集合的明文文档集合M:{m₁, m₂, …, mₙ}。其中n是文档集合中的文件数量。
- E :存储在云服务器中的加密文档,可表示为 E:{e₁, e₂,....eₙ}。
- W :从文档集合M中提取的不同关键词,表示为 W = {w₁, w₂, …, wₙ}。
- I :与E相关联的可搜索加密索引,表示为 E:{i₁, i₂, i₃…iₙ},其中每个索引 ii为文档集合中每个文档 mi构建。
- W̃ :搜索查询中的关键词集合,也可视为W的子集,表示为 W̃:{w_{j1}, w_{j2}, w_{j3}......w_{ji}},其中j表示查询中的第 jth个关键词,i=1, 2,3,n 表示第 ith个字母在 jth关键词中。
- TW :为 W̃ 生成的陷门。
- MidW :针对 W̃ 的所有文档的排序的ID列表,其中下标表示为 W̃ 检索到的文档的ID。
- K :基于词干条件创建的初始关键词集,可表示为 K : {k₁, k₂, …, kₘ},其中m是该集合中的关键词数量。
- Sk :由数据拥有者生成的密钥,用于加密、解密以及执行安全哈希操作。
- T₁, T₂ :用于创建密钥的矩阵。
- V, Q :表示数据向量和查询向量,相乘后可用于计算搜索时的排名分数。
- Pscore :通过考虑多因素而添加到词频规则中的分数。
3 近似匹配与基于多因素的排序方案
3.1 近似匹配
为了衡量所生成的关键词与原始查询关键词之间的相似性,我们提出了近似度评分对其进行排序。具体而言,ki的近似得分用APP(ki)表示,可公式化如下:
$$
APP(k_i) = \log_{10}\left(\frac{L_{ij}}{Q_j}\right) \times \left(\frac{U_{ij}}{Q_j}\right) \tag{1}
$$
算法1. 生成词干词
1: 过程 createstem(w_j, m, n) // w_j 表示给定多关键词查询中的单个关键词;
2: for j = 0 到 w_j 的长度 do
3: if j < m then
4: p' = +w_j[i];
5: else if j < (length(w_j) − n) then
6: s = +w_j[i];
7: endif
8: endfor
整个过程的伪代码总结如下。词干根据预定义条件创建,如算法1所示。然后基于预先创建的词干生成基本关键词集(如算法2所示)。最后,通过从基本关键词集中检索前l个关键词来构建最终关键词集(如算法3所示)。
算法2. 基本关键词集创建
1: 过程 关键词集遍历(I, p', S');
2: 如果 w_ji == 为空 那么
3: 返回 -1;
4: 否则
5: 返回 1 + Math.max(height(I.root.left), height(I.root.right));
6: // 计算树的高度;
7: 结束 if
8: 如果 I.root == nil 那么
9: 返回
10: 结束 if
11: 对于 i = 0 到树的高度 执行
12: 遍历(I.root.left, p', S');
13: 结束循环
14: 如果 I.root.left == p' 则
15: 保存到 K_i;
16: 否则如果 I.root.left == S' then
17: 遍历(I.根节点.右子树, p', S');
18: 结束如果
3.2 排名 相似度度量
在计算排名分数时,我们考虑了两个额外的因素,以进一步提高精度。一个是关键词相对于其他文档的位置,另一个是句子中关键词之间的距离。基于多因素的排名分数表示为Score(mi, W),其公式见公式2。
$$
Score(m_i, W) = \frac{1}{|m_i|} \sum_{w_j \in W} \left(1 + \ln(f_{m_i,w_j})\right) \cdot \ln\left(1 + \frac{|M|}{f_{w_j}}\right) + P_{score} \tag{2}
$$
Pscore是填充分数,可通过公式3计算。
$$
P_{score} = \left(\frac{f_{m_i,w_j}}{|m_i|}\right)\left(1 - \frac{\text{position}(w_j)}{|m_i|}\right) \tag{3}
$$
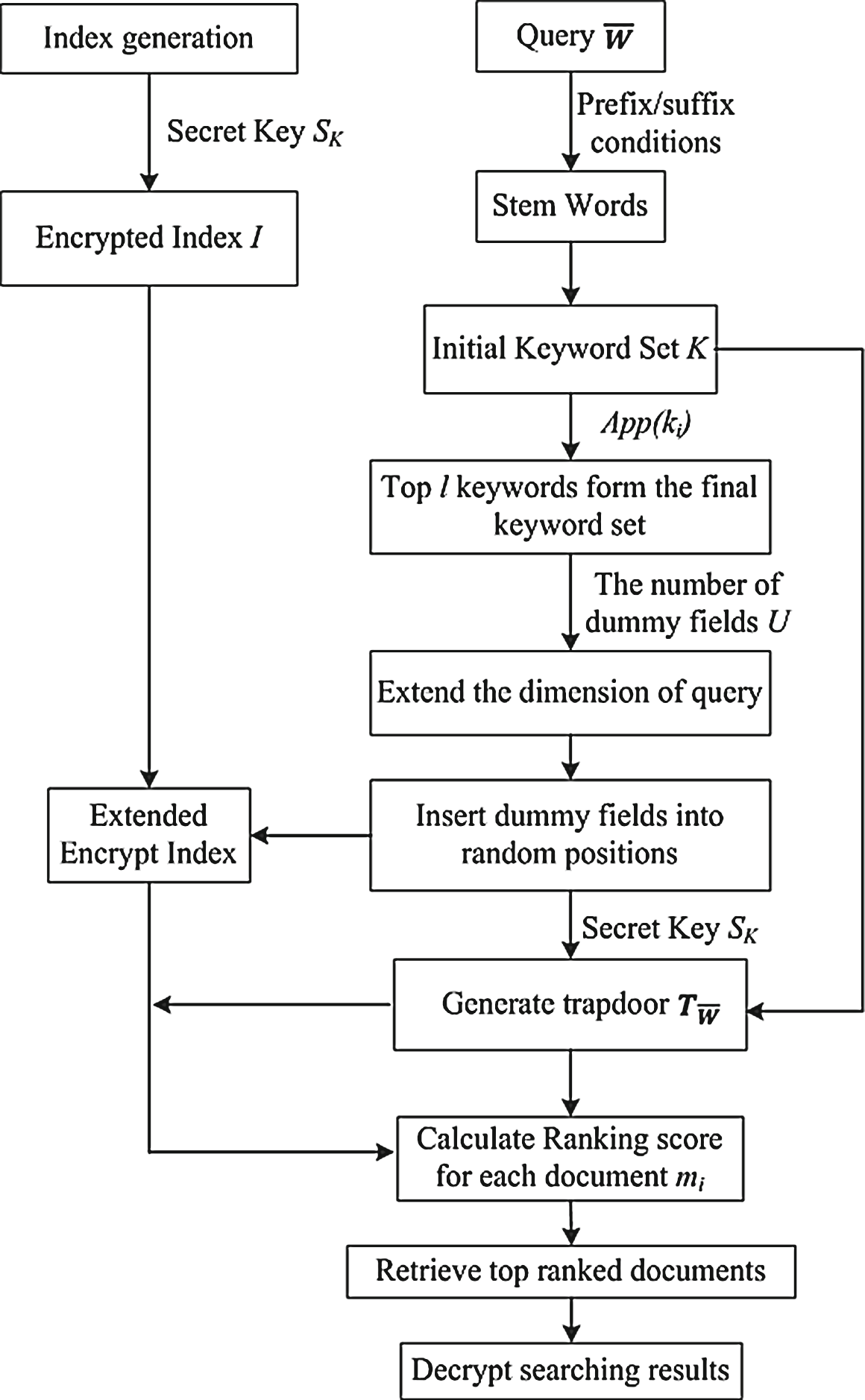
4 系统框架和高效搜索机制
在本节中,我们描述了系统在加密数据上工作的基本框架。系统框架的概述如图2所示。
4.1 随机虚拟字段插入机制
陷门使用公式4计算虚拟字段,并将关键词与排名分数进行匹配。
$$
I_i \ast T_W = T^T_1 \ast \vec{V}
l’,\ T^T_2 \ast \vec{V}_l’’ \ast T^{-1} Q
{\vec{l}’},\ T^{-1}
2 \ast Q
{\vec{l}’‘} = (\vec{V}
l \ast Q
{\vec{l}}) \ast (\vec{V}
l’’ \ast Q
{\vec{l}’‘}) \Rightarrow V_i \ast Q_i = Score(m_i, W) + \sum \mu(U) + t \tag{4}
$$
4.2 安全分析
为了提供隐私保护,通过扩展陷门和查询的数据向量维度来插入虚拟值。这些随机值可以动态地插入到扩展的维度中。每次生成陷门时,维度扩展可以不同,随机的虚拟字段也会不同。引入虚拟字段可为每次查询生成不同的方程。然而,在扩展维度中引入虚拟字段并将其与实际数据向量区分开来时,可能会牺牲性能。然而,提升隐私性是以降低计算速度和准确性方面的性能为代价的权衡。
5 性能分析
5.1 仿真设置
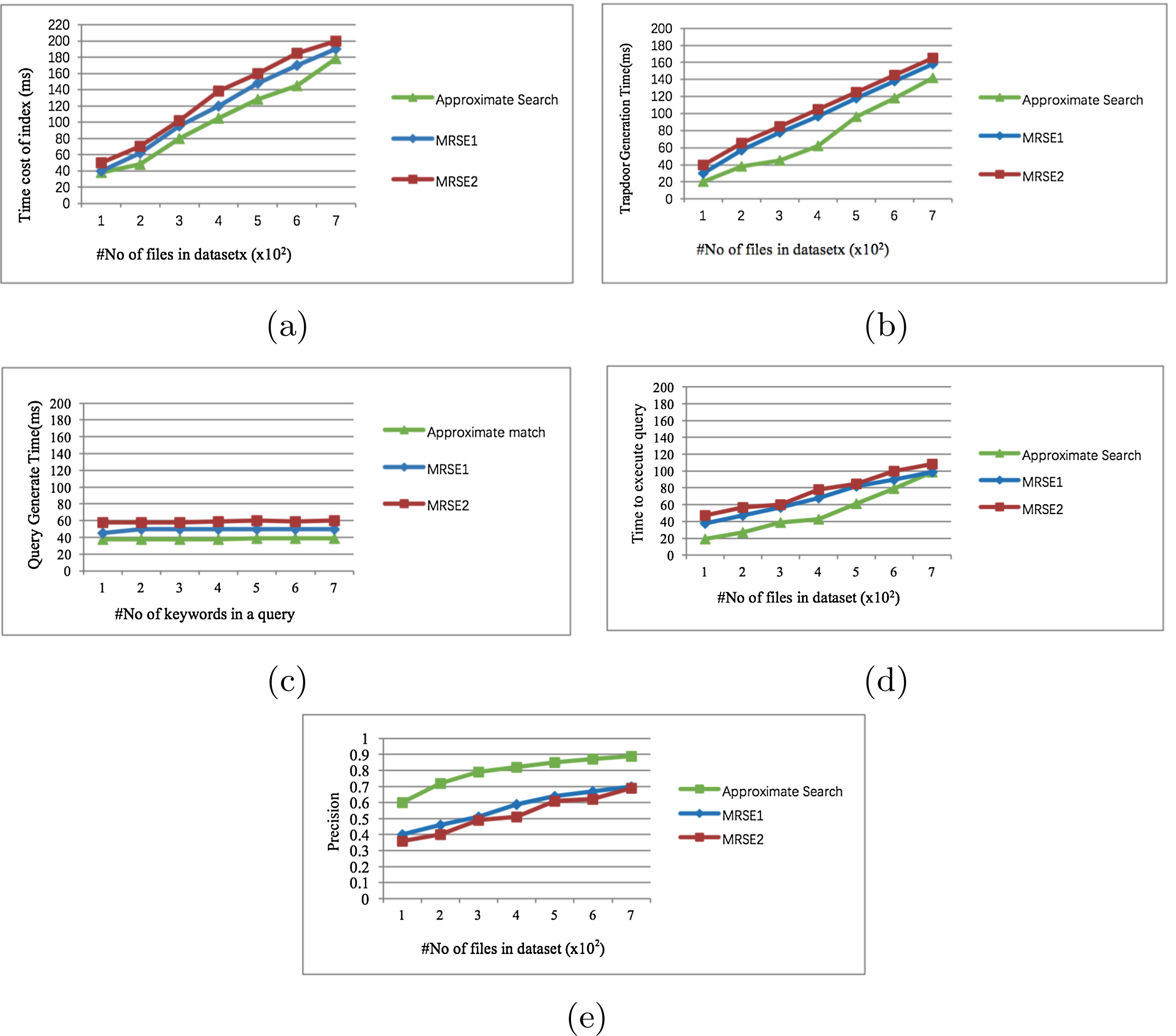
我们通过J2EE构建了自己的模拟器来模拟云场景。我们使用了安然数据集[4],其中包含来自60000名用户的电子邮件信息,并随机选择子集形成我们的测试数据集。实验在包含700个文件的数据集中进行,每个文件包含800个关键词。为了获得平滑的输出结果,我们对每100次实例的结果取平均值。我们实现了三种不同方案:(1)我们所提出的方案,标记为近似搜索。(2)文献中提出的已知密文模型下的隐私保护方案,标记为MRSE1。(3)文献中提出的已知背景模型下的隐私保护方案,标记为MRSE2。我们在索引创建时间、陷门生成时间和查询执行时间方面对它们进行了比较。
5.2 仿真结果
索引构建时间。 索引通过从文档中提取单词并使单词中的每个字母形成一个节点来创建。索引构建时间包括扫描文档和在索引树中创建节点的时间。图3(a)展示了所有三种算法的索引构建时间结果。
陷门生成时间。 生成陷门需要查询和密钥。图3(b)展示了当用户向服务器提交查询时陷门生成的时间开销。
查询生成与执行时间。 服务器中的查询执行包括创建和匹配哈希值,以区分随机性与实际数据,并对文档的顺序进行排名。图3(c) 显示了关于查询中关键词数量的查询执行时间结果。图3(d) 显示了关于文件数量的查询执行时间结果。图3(e) 总结了三种方案之间的准确率比较结果。
6 结论
本文首先引入一种可在加密的云数据上进行的近似匹配,以提高搜索效率。随后,提出了一种基于多因素的排名评分技术,以提高搜索结果的准确性。最后,为了增强保护隐私,采用了一种动态随机虚拟值插入方案,以抵御规模分析攻击。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









